







导语
LangChain 是一个优秀的 LLM 应用开发框架,让普通开发者能够快速入门 LLM 应用开发,能够轻松地实现预期功能。它封装了非常多的功能,让开发者在使用时变得容易,相应的,越强的封装性也就代表其背后做了越多的事情,使用越简单其框架代码就越复杂。
在使用 LangChain 开发的过程中,不少人感觉太黑盒了,对于内部运行的逻辑知之甚少,对于这一点,我们可以通过源码阅读来破局。本文就带领小伙伴一起阅读agent 模块的源码,这也是使用 LangChain 框架开发 LLM 应用中最重要的模块之一。
注:文章基于 LangChain v0.1.0 版本
基本概念
- Agent 组件的核心是以大语言模型为推理引擎,并根据这些推理来决定如何与外部工具交互及采取何种行动;
- Agent 是 LangChain 框架的一种高级组件,它将工具组件 tools 和链组件 chain 整合在一起;
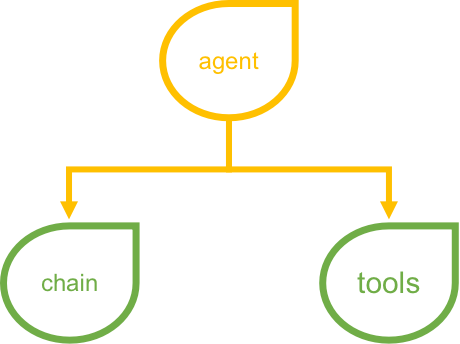
- 本质上就是编写 prompt,让模型仿照你的方式来进行执行的一种应用范式,prompt 里面包含一些 tools 的描述,然后我们可以根据模型的输出使用一些外部 tools;
Agent 分类
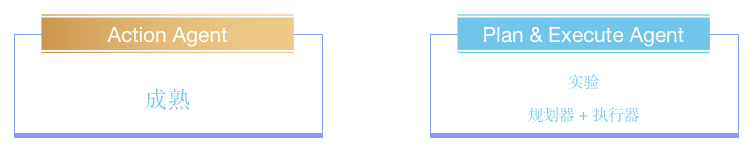
列举了两个 Agent 种类,这两个种类的区别是:
- Action Agent:在每个时间步长,使用所有先前操作的输出来决定下一步的操作;step by step,即每一步操作都会立即去执行,得到输出后使用该输出进行下一步的决策和操作;
- Plan-and-Execute Agent:它分成了两部分,一个是规划器,一个是执行器;它首先制定完整的行动顺序,然后在不更新计划的情况下全部执行。
当然还有一些其他类型的 Agent,这里不再赘述。
LangChain 中常用的 Agent 都属于Action Agent。
Action Agent 的控制流程是发送用户的输入后,如果需要,Agent 会寻找一个工具并运行它,然后 Agent 会检查该工具的输出;Agent 可以串联多个工具,可以将某个工具的输出作为下一个工具的输入,从而实现复杂和特定的任务。
LangChain 中的 Agent
关于 LangChain 已经集成的 Agent,可以关注:
- 枚举类:AgentType
- AGENT_TO_CLASS,这里描述了每个枚举类型对应的 Agent 实现类

下面是列举(简单浏览即可):
AgentType.ZERO_SHOT_REACT_DESCRIPTION:ZeroShotAgent。 此 agent 使用 ReAct 框架,仅根据工具的描述来确定要使用的工具。可以提供任意数量的工具。
AgentType.REACT_DOCSTORE: ReActDocstoreAgent。此 agent 使用 ReAct 框架与文档存储进行交互。必须提供两个工具:搜索工具和查找工具。“搜索”工具应搜索文档,而“查找”工具应在最近找到的文档中查找术语。
AgentType.SELF_ASK_WITH_SEARCH: SelfAskWithSearchAgent。此 agent 使用一个固定命名为“Intermediate Answer”的工具。这个工具需要能够查找问题的真实答案。
AgentType.CONVERSATIONAL_REACT_DESCRIPTION: ConversationalAgent。此 agent 程序设计用于会话,旨在使 agent 提供帮助并进行对话。它使用 ReAct 框架来决定使用哪个工具,并使用内存来记住以前的对话交互。
AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION: ChatAgent。针对聊天场景的 agent。
AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION: ConversationalChatAgent。会话式 + 聊天的 agent。
AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION: StructuredChatAgent。结构化工具聊天 agent 能够使用多参数输入工具。较旧的 agent 被配置为将操作输入指定为单个字符串,但此 agent 可以使用工具的参数架构来创建结构化的操作输入。这对于更复杂的工具使用非常有用,比如在浏览器中精确导航。
AgentType.OPENAI_FUNCTIONS: OpenAIFunctionsAgent。 某些 OpenAI 模型增加了函数调用的功能,通过 openai 模型可以预测何时应该调用函数,并用应该传递给函数的输入进行响应。OpenAI 函数代理是为处理这些模型而设计的。
Agent 的创建方法
1、隐式创建
调用的是 initialize_agent 方法,通过 agent=xxx 来指定要创建的 Agent 类型,这个类型来自我们上面提到的 AgentType 枚举,另外还需要提供 tools 列表、LLM,其余的初始化工作会在 initialize_agent 中自动进行。
封装性较强,更加黑盒。
注:当我们使用 v0.1.0 以上版本运行代码时,会提示我们当前使用的 api 将在 v0.2.0 中弃用,也就是说官方后面会更加推荐下面的显示创建方法
llm = Spark()
#加载工具
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
result = agent.run("影视剧演员邓超的妻子是谁?他现在有几个孩子?他的孩子的个数乘以2再加上5是多少?")
2、显式创建
代码量多,需要自己显式地创建好提示词模板、Agent 组件、AgentExecutor 组件。
好处是可定制化更好,适合自定义 Agent,比如即使你决定了使用某一个具体的 agent 类型,你仍然可以定制你的提示词,另外重要的一点是,你可以控制 AgentExecutor 中的很多参数来适应自己的功能要求及控制执行流程。
llm = Spark()
prompt = hub.pull("hwchase17/structured-chat-agent")
agent = create_json_chat_agent(llm, tools, prompt)
query = "影视剧演员邓超的妻子是谁?"
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
result = agent_executor.invoke({"input": query})
从类图看实现
从上面两种常见的创建方式可以看出来,核心的东西有两个:
- Agent组件
- AgentExecutor组件
其中tools在两个组件的创建过程中均涉及到了,因为在创建Agent组件的时候tools需要用来组成提示词,创建AgentExecutor的时候,是需要根据推理去实际调用tools。
agent的主要作用就是依靠大语言模型进行推理,它的核心方法是plan方法,也就是访问大语言模型获得计划。
AgentExecutor相当于是Agent组件的运行管理环境,负责调用和管理Agent组件,执行Agent组件制定的行动计划以及处理其他一些复杂的情况,比如日志记录、错误兼容处理等。
agent 类图

这里是拿 chat_agent 举例,实际上 LangChain 内置的 agent 继承关系几乎都是一样的,通过这个图我们也能很清楚地知道如果我们自己想自定义一个 Agent 应该如何去实现。
例如:
- 如果你对提示词创建过程有特殊处理,那就覆写 create_prompt 方法,比如需要实现多参数工具的使用;
- 如果你对工具类型有特殊逻辑,可以覆写 validate_tools 方法,比如校验工具传参个数、工具名称等;
AgentExecutor 类图
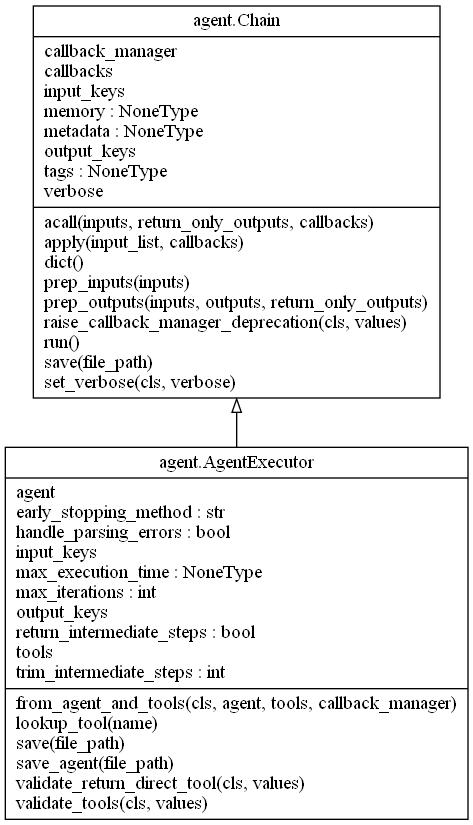
这是 AgentExecutor 的类图,可以看到它是继承了 chain,也就是说它具有 chain 所具有的所有功能,并且因为它是继承了 chain,所以我们在看代码的时候可以关注它的 _call 方法。
这里需要重点关注一下它的可用参数列表以及工具相关的一些方法,后面源码分析中会详细介绍。
源码分析
源码分析主要是两部分:
- 1、初始化过程
- 2、执行过程

由于内容较多,本篇文章会先分析初始化流程,执行过程放在下篇文章。
下面的分析过程我们将使用 STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION 类型,这个类型的特点是:
- 推理过程遵循 RE-ACT 范式,这也是 LangChain 中集成 Agent 使用最广泛的范式;
- 这个 Agent 类型擅长处理 JSON 数据;
- 更重要的是它不仅支持单参数的工具调用,还支持多参数的工具调用;
- 仅支持单个 Action 的输出,即不支持大语言模型一次输出多个要执行的任务。
在源码分析过程中,我们也会着重看一下这些特点分别是怎么来实现的。
初始化过程
准备工作:定义一个 tool 工具,该工具支持多参数传递,其中工具名称是“tool_name”,其输入参数结构为 ToolInput,即 args_schema 的定义
class ToolInput(BaseModel):
args1: str = Field(description="the desc for args1")
args2: str = Field(description="the desc for args2")
args3: str = Field(description="the desc for args3", default="")
class ToolFunction(BaseTool):
name = "tool_name"
description = "the desc for tool_name"
args_schema: Type[BaseModel] = ToolInput
return_direct = True
def __init__(self):
super().__init__()
def _run(self, args1: str, args2: str, args3: Optional[str] = "") -> dict[str, Any]:
return "tool result"
流程图:
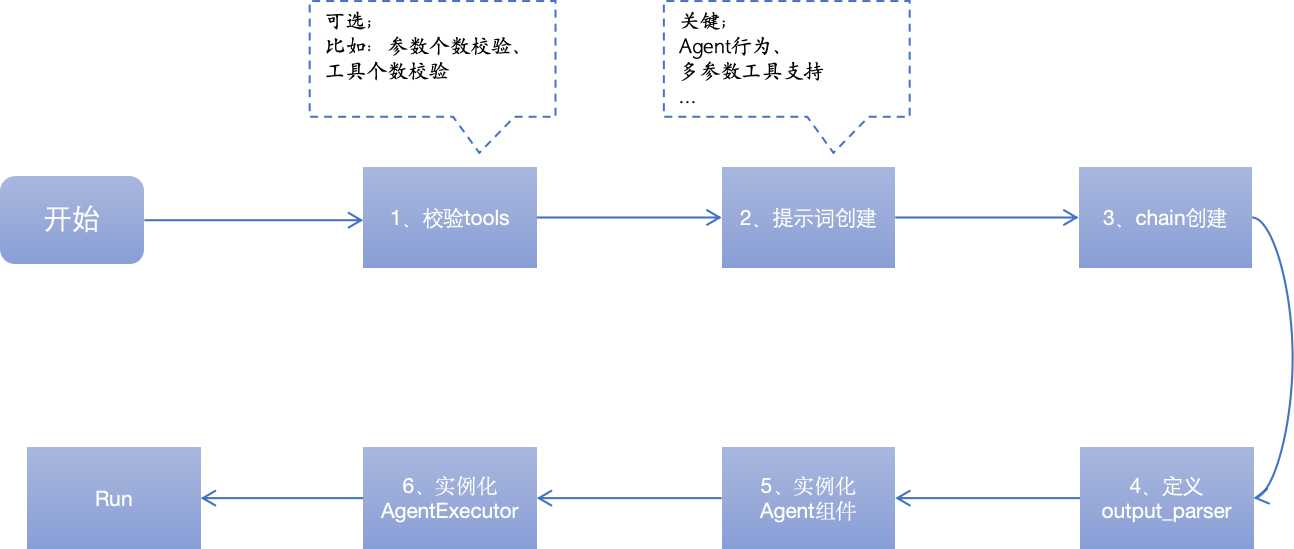
图中 1、2、3、4、5 的过程为初始化 Agent 的过程,6 为初始化 AgentExecutor 过程。
先看一下整个初始化过程(initialize.py->initialize_agent):
下图是调用 initialize_agent 方法初始化时的代码,总体只有两部分:
- 红框部分为初始化 Agent 组件
- 绿框部分为初始化 AgentExecutor 组件

1、初始化 Agent 组件
下面先看 Agent 初始化的逻辑,“agent”参数是指定 LangChain 中集成的 Agent 类型,“agent_path”参数为指定从某个路径或者 hub 上的文件加载 agent,文件必须是 JSON 或者 yaml 文件。这里主要看“agent”参数相关。
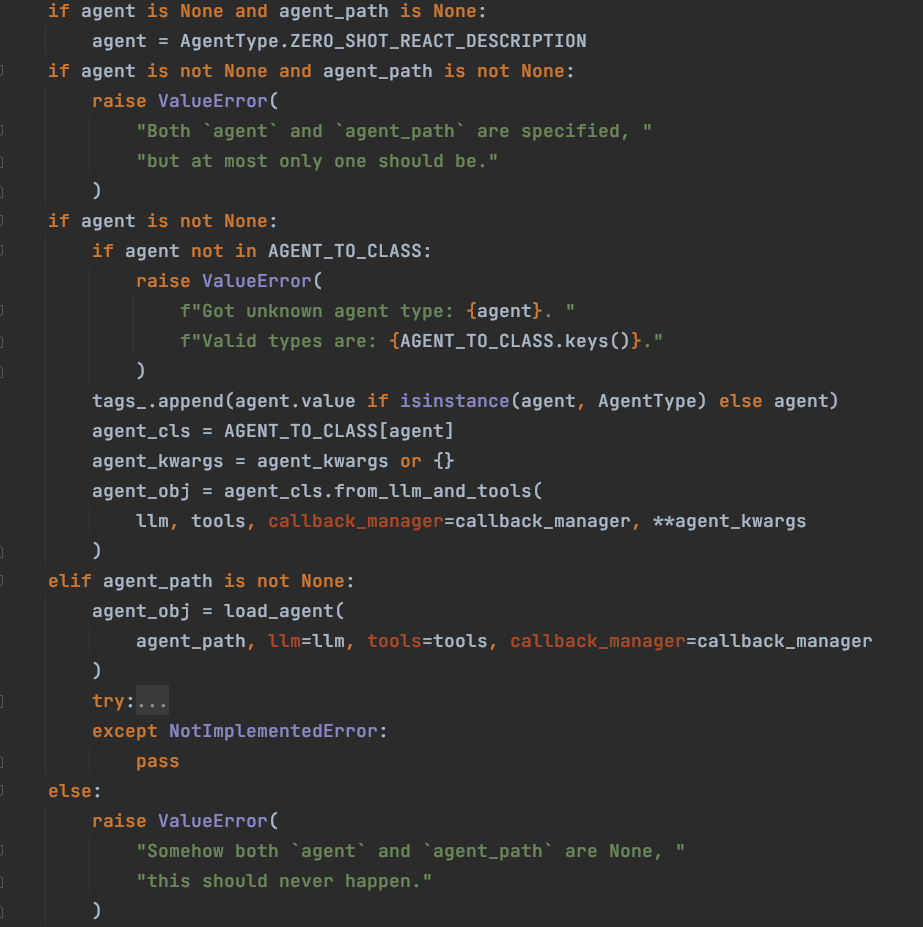
从代码可以看到,如果我们没有指定任何 agent_type,那么 LangChain 将默认使 ZERO_SHOT_REACT_DESCRIPTION;只有在我们指定的 agent_type 在 AGENT_TO_CLASS 中存在时才能正常初始化。
当检验通过,将调用 agent_cls.from_llm_and_tools 方法来初始化 agent 组件。
1.1 Agent 组件初始化(structured_chat/base.py)
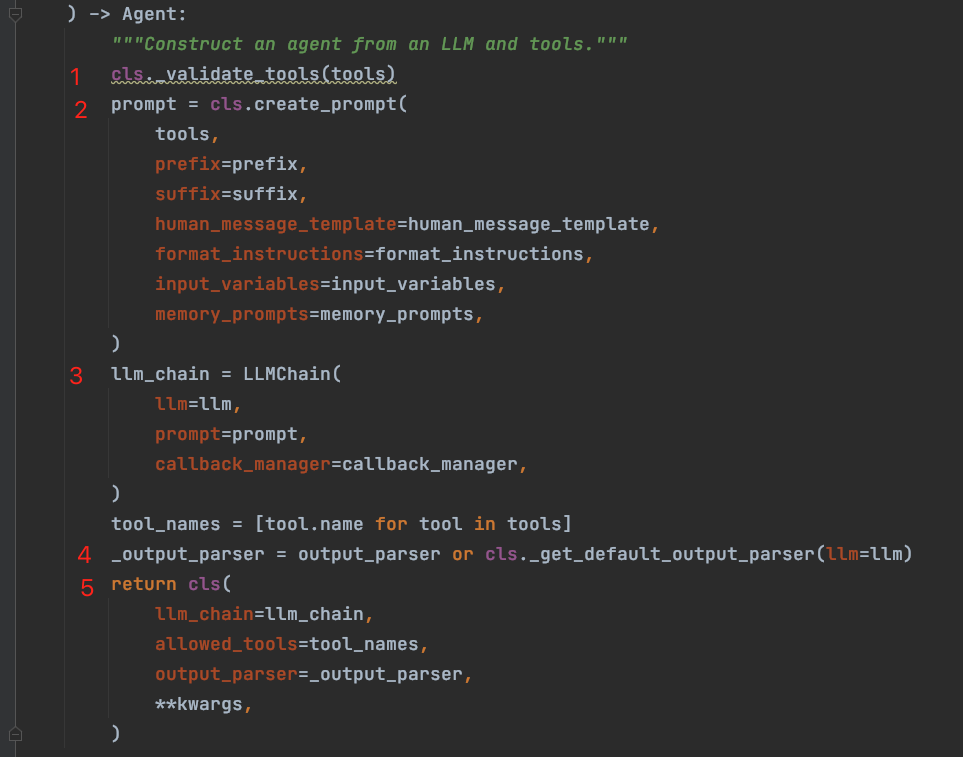
初始化 Agent 组件需要以下几个步骤:
-
A. 检验工具
_validate_tools 方法,在当前 Agent 类型中,它直接使用了父类的检验逻辑,而父类中实际上没有实现对工具的检验逻辑,也就是说这个类型的Agent不校验工具;
对工具的校验逻辑常见的有:- 工具参数个数检验
- 工具列表个数检验
- 工具名称检验
有的 Agent 比如 Self_ask,它要求工具必须是单参数,工具个数有且仅有 1 个,并且工具命名必须是"Intermediate Answer";当我们也有类似需求,则覆写父类的工具校验方法。
下图是 self_ask 类型的 agent 校验工具的逻辑示例: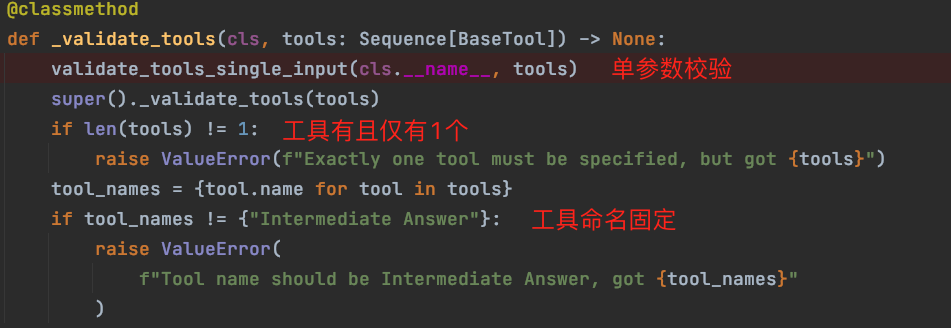
-
B. 提示词创建
看create_prompt 方法,对于 STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION 类型,提示词中的关键信息是:- {tools}工具列表
- {tool_names}工具名称列表,这里和上面{tools}的作用区别是限制模型在 Action 中输出的名称范围
提示词模板截取示例:
input_variables=··· ··· {tools} Use a json blob to specify a tool by providing an action key (tool name) and an action_input key (tool input). Valid "action" values: "Final Answer" or {tool_names} Provide only ONE action per $JSON_BLOB, as shown: \``` {{ "action": $TOOL_NAME, "action_input": $INPUT }} \``` ··· ···如果想要看完整提示词,可以使用下面的代码下载提示词文件
prompt = hub.pull("hwchase17/structured-chat-agent") prompt = str(prompt).replace("\\n", "\n").replace("\\t", "\t") with open('promptstext/structured-chat-agent.text', "w") as file: file.write(prompt)当组件提示词有特殊逻辑时,我们可以覆写父类的 create_prompt 方法来实现;如下图所示是当前 agent 类型的提示词创建过程,提示词模板的处理主要是工具描述的组织,提示词其他部分都可以使用一些固定模板。
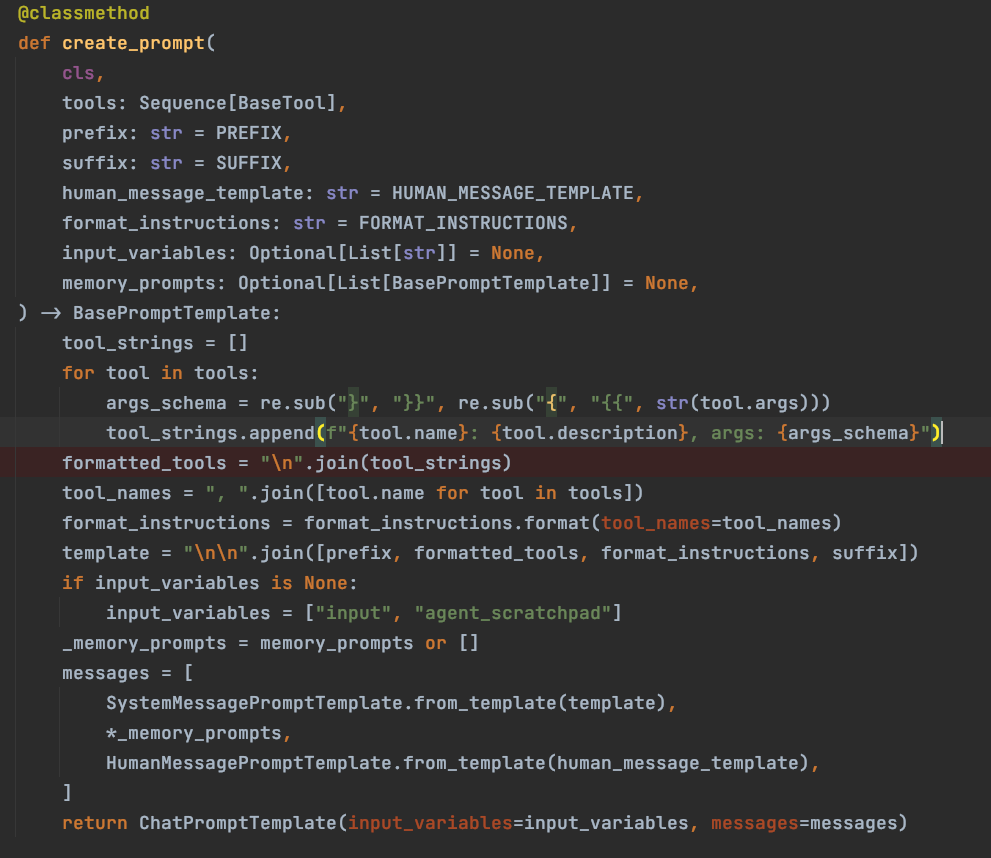
这里需要重点看一下下面这张图的的代码:

上面讲到 STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION 类型的特点里有提到“工具的多参数支持”,那么这里就是支持 multi-input 的关键所在,这里的 args_schema 取自工具定义中的 args_schema,在工具定义中 args_schema 赋值的是一个接口参数定义的类,里面描述了参数列表以及每个参数的描述信息,这里就是将参数的描述信息也一并传递给大语言模型,让大语言模型知晓如何按规则正确地输出 action_input 从而正确地调用 tool。
tool_strings 真实示例如下:可以看到除了工具的 name 和 description 外,里面还包含了参数列表的详细描述 args:
[ "tool_name: tool_desc, args: { { 'args1': {{'title': 'title1', 'description': 'desc1', 'type': 'string'}}, 'args2': {{'title': 'title2', 'description': 'desc2', 'type': 'string'}}, 'args3': {{'title': 'title3', 'description': 'desc3', 'default': '', 'type': 'string'}} } }" ] -
C. chain 的创建
较简明,不赘述
-
D. 输出格式化定义 output_parser
源码中支持传入一个指定的类作为格式化工具,如果我们不指定,那么它将使用自己集成的格式化工具:
源码:_output_parser = output_parser or cls._get_default_output_parser(llm=llm)这里的格式化逻辑,一定是与提示词中对大语言模型输出规范相匹配和适用的,我们要求 LLM 怎么给我们数据,就需要对应地去写什么样的解析逻辑来获取和组织数据。
然后具体看一下,STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION 类型的 Agent 使用的是 StructuredChatOutputParser 来格式化输出,看一下它的实现(structured_chat/output_parser.py),关注它的 parse 方法:
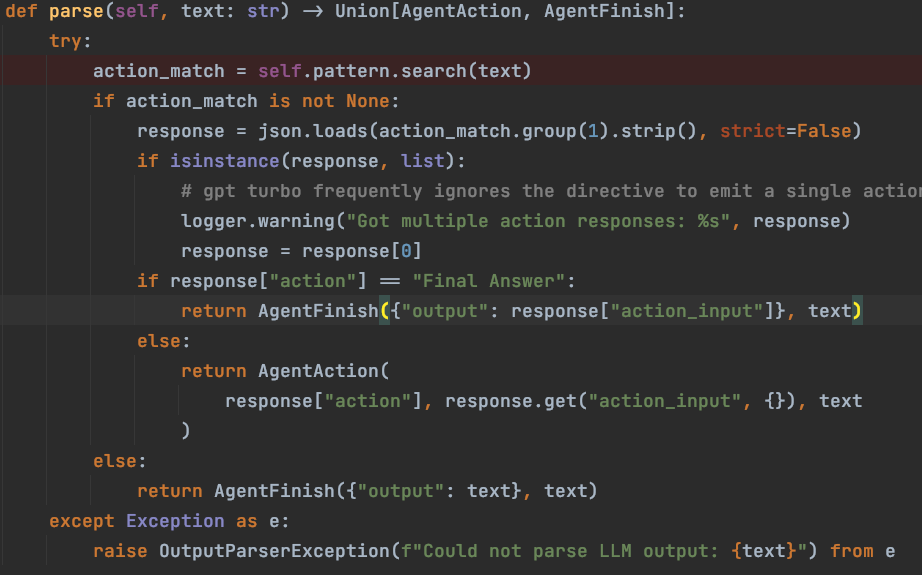
首先它会以 JSON 的格式加载响应数据,这里有个校验:如果返回的 Action 数据是个 list,也就是同时返回了多个 Action 动作,那么这里只会取第一个 Action 去执行;
接下来就是对于 Action 结果的封装,如果 LLM 给出的 Action 动作是“Final Answer”,则代表是最终的答案,为什么这个代表的是最终答案呢,也是在提示词中规定好的,可以在提示词中查看对 LLM 给出的执行动作的规定;如果是其他动作,则一定是 tools 工具列表中的某一个,这时候是要继续往下执行工具的。
下面的内容是提示词模板中对最终答案的描述:
Thought: I know what to respond Action: \``` {{ "action": "Final Answer", "action_input": "Final response to human" }} \```此处我们先明确 LangChain 中两个类的定义,这两个类在 AgentExecutor 执行逻辑中用于状态判断:
- AgentFinish:最终结果,会终止循环并把 return_values 返回给用户作为最终输出
- AgentAction:调用工具执行动作,tool_input 作为被调用工具的输入,实际上 tool_input 就是 LLM 输出的 action_input 数据或者它的转换
-
E. 创建 Agent 实例
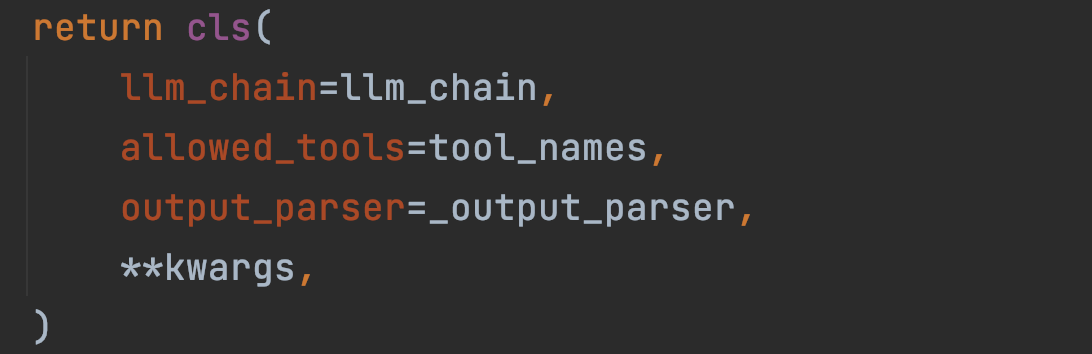
这里需要工具列表 tool_names,主要作用是用于在 AgentExecutor 中的一致性校验,确保在 AgentExecutor 中传入的工具列表和 Agent 组件中的工具列表是一致的。
初始化 Agent 组件的过程到此结束。
2、初始化 AgentExecutor
Agent.py ->from_agent_and_tools
,实例化方法是非常简单的,这里需要关注的是它的传入参数和工具相关的方法。
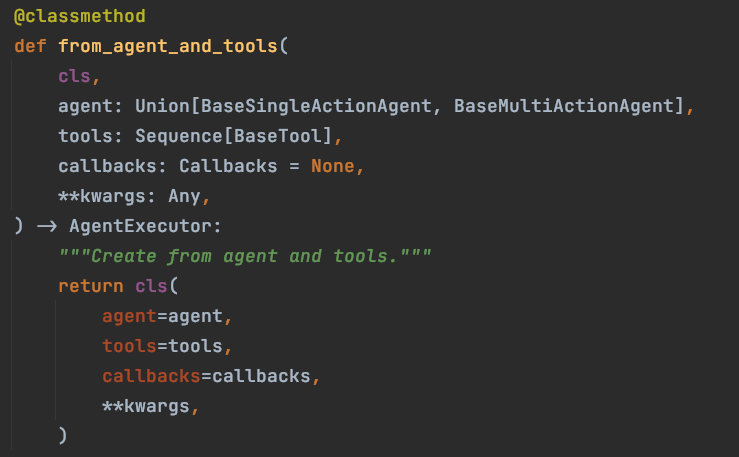
一、参数说明:
**Agent:**不用说了,就是前面刚初始化的 Agent 组件
**tools:**工具列表
**return_intermediate_steps:**表示是否在最后返回结果中添加 Agent 中间步骤的轨迹记录,默认是 False
**max_iterations:**这个从名字很好理解,是最大迭代次数,能够防止模型在一直拿不到理想推理结果的情况下进入无限循环,默认值是 15
**max_execution_time:**这个的作用也类似,从名字也能看出来,它是通过时间来进行循环的限制的,默认是没有值的
**early_stopping_method:**作用是在一直没有得到正常结束的输出结果的情况下,结束当前执行,是对异常终止的处理策略;他有’force’ 和 ‘generate’:
- force 就是在上面说的两个参数到达临界值的时候终止执行;
- generate,作用是根据前面一步的结果最后一次访问大语言模型并作为最终结果返回;
**handle_parsing_errors:**是处理异常的,可以在发生异常的情况下,保证下一步能够继续正常和大语言模型进行交互;他有三种策略:
- 1 是传入 boolean 值 True,会把错误信息传给大语言模型进行下一次推理;
- 2 是 String,那么你传入的这个 String 就会在出现错误时被当做输入传给 llm 进行下一步推理;
- 3 是 function,这里允许使用 function,当发生异常时使用该 function 的执行结果作为输入,让 llm 进行下一步推理。
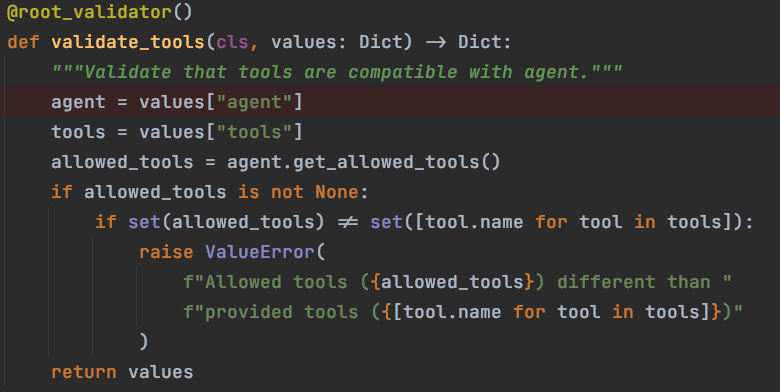
二、工具校验方法:
-
A. 工具列表是否一致
代码如下
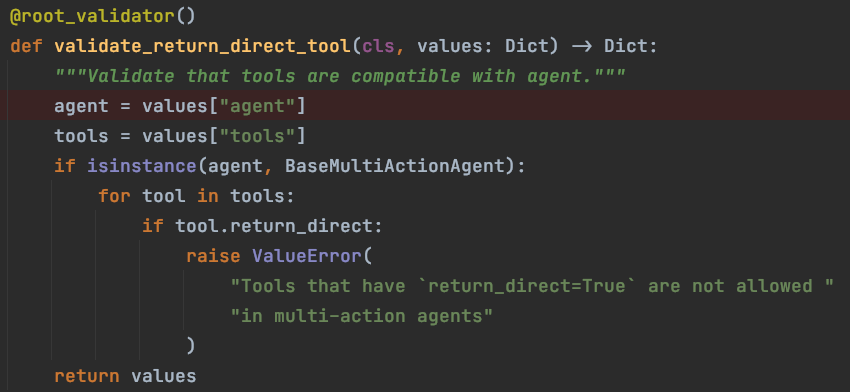
-
B. return_direct 参数校验
对于 multi-action 的 Agent,禁用工具中的 return_direct 参数
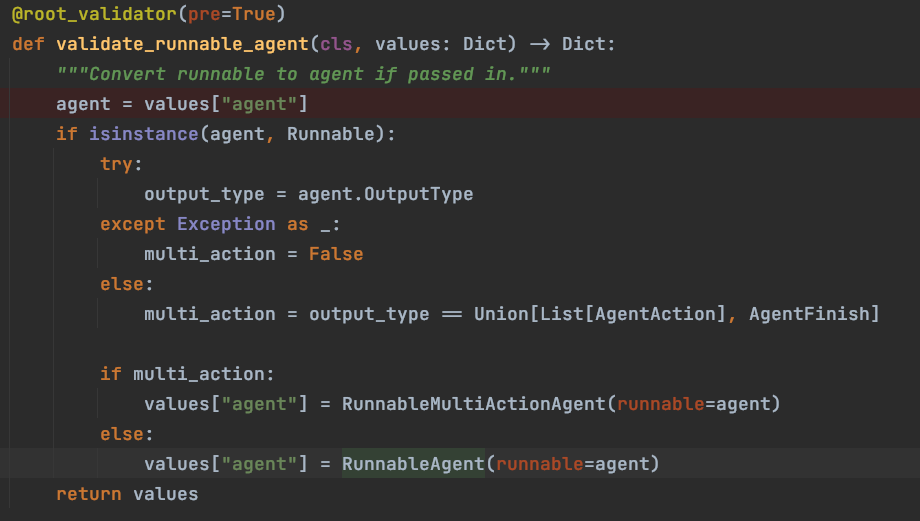
-
C. LCEL 管道对象处理
对于使用 LCEL 创建的管道对象进行类型转换,转成 RunnableAgent 对象,RunnableAgent 对象继承自 BaseSingleActionAgent
总结
至此,Agent 和 AgentExecutor 初始化已经基本完成,我们分析了它初始化中的重要方法和关键逻辑,比如对多参数 tool 的支持等,本次的内容到此结束。
下一篇我们将继续分析使用 Executor 对象来执行推理过程。关注我不迷路~
快乐学习,简单学习!
关注了解更多 AI 编程、Java 编程知识!

本文由mdnice多平台发布

















 1951
1951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









