






写在前面
先分享两个发现的够全的知识链接。最开始想了解某一模块,先从这种总结的特别全面的维度,每一块梳理,建立知识网络后,再遇到针对具体模块的讲解or优化文章,也能立马定位知道是针对网络上某个点知识的讨论,知道来自哪个角度,用于什么方向的优化。这个知识整理的方法我认为很有用,
关于RAG的各方面整理 https://github.com/charliedream1/ai_wiki/tree/536156d1df93015951a957596eb2c354b527480e/35_RAG
关于大模型的各方面整理
https://github.com/andysingal/llm-course/tree/83048a5312d60e643e9f4396ddcbb628b52ba5f2
<!>llamaIndex介绍
llamaIndex是一个用于LLM应用程序的数据框架。用于注入,结构化,并访问私有或特定领域数据。
首先,langchain和llamaindex的异同:
用通俗易懂的方式讲解:大模型应用框架 LangChain 和 LlamaIndex,到底谁更胜一筹? https://blog.csdn.net/2301_78285120/article/details/135895441
llamaindex的官网介绍:https://docs.llamaindex.ai/en/stable/examples/low_level/oss_ingestion_retrieval/
https://www.llamaindex.ai/
内容包括如下
使用模型,加载数据,数据向量化,存储向量,对输入query做检索,跟踪。效果评估。

关键步骤是将数据加载为文档,解析为节点,在文档/节点上构建索引,查询索引以检索相关节点,然后解析响应对象。索引也可以持久化并从磁盘重新加载。

相关样例的代码路径 llama_index-main/docs/examples
llamaindex应用相关代码地址,如下,内容很全,包括了各个角度的应用demo
https://github.com/andysingal/llm-course/tree/83048a5312d60e643e9f4396ddcbb628b52ba5f2/llama-index/llama_index_example
<!>lLlama-index 基本框架
https://zhuanlan.zhihu.com/p/671843127
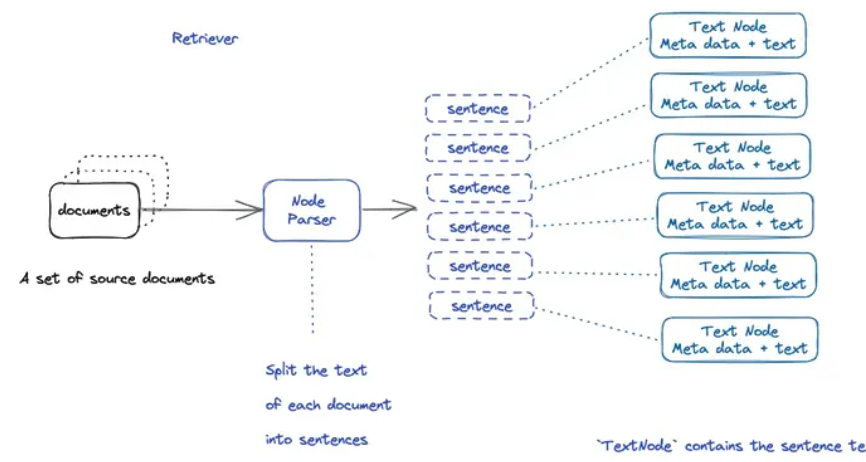
1.chunking过程
LLamaIndex将输入文档分解为节点的较小块。这个分块是由NodeParser完成的。默认情况下,使用SimpleNodeParser,它将文档分块成句子。
<!>lllama-index做RAG
代码: https://github.com/intel-analytics/ipex-llm/blob/main/python/llm/example/GPU/LlamaIndex/rag.py
llama-index实现基本RAG的示例
# load data
documents = SimpleDirectoryReader(input_dir="...").load_data()
# build VectorStoreIndex that takes care of chunking documents
# and encoding chunks to embeddings for future retrieval
index = VectorStoreIndex.from_documents(documents=documents)
# The QueryEngine class is equipped with the generator
# and facilitates the retrieval and generation steps
query_engine = index.as_query_engine()
# Use your Default RAG
response = query_engine.query("A user's query")
<!>lllamaindex做RAG的一些高阶技巧
大模型 Advanced-RAG(高级检索增强生成):从理论到 LlamaIndex 实战!
https://zhuanlan.zhihu.com/p/683806246
一. 针对检索的一些高级用法
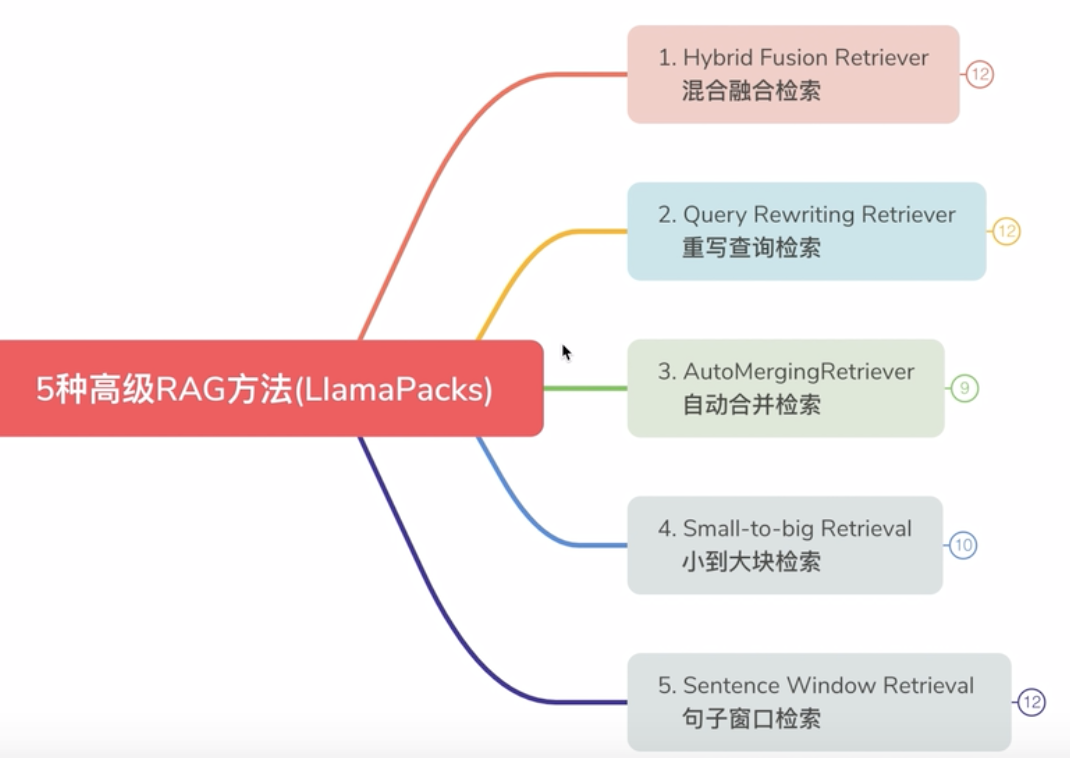
来源:
b站讲解1:https://www.bilibili.com/video/BV1qe411r78b/?spm_id_from=333.788.recommend_more_video.1&vd_source=c4e1d9d645f9a1554bc220274b5b24a8
b站讲解2:https://www.bilibili.com/video/BV1Yk4y1L7Vh/?spm_id_from=333.999.0.0
二. 针对query变形的一些优化
1)HYDE query transformer
用法:一些比较短的query,很容易导致embedding搜索结果不理想。比如比较泛的一些query。
解决:hyde:先让模型不查资料做个回答,再把答案和问题一起扔进去,做embedding,再做检索。相当于更丰富的输入来查结果。
代码位置:llama_index-main/llama-index-core/llama_index/core/indices/query/query_transform/base.py
HyDEQueryTransform(BaseQueryTransform):
2)DecomposeQueryTransformer
将一些比较长的问题,比如答案需要来自多个文档对比的问题,做分解,分解为多个子问题。子问题分别从LM获得答案,再将多个答案交给LM做合成分析后输出最终答案。
代码位置:两个实现方案
1. llama_index-main/llama-index-core/llama_index/core/query_engine/sub_question_query_engine.py
2.llama_index-main/llama-index-core/llama_index/core/indices/query/query_transform/base.py
DecomposeQueryTransform(BaseQueryTransform)
其中包括两种分解方法:single-step和multistep

3)多套index做复杂的嵌套
同一篇文档做两套index,比如A和B。查询的时候用A查一下,再用B查一下,再做两个结果的关系合并。
代码:llama_index-main/llama-index-packs/llama-index-packs-nebulagraph-query-engine/llama_index/packs/nebulagraph_query_engine/base.py
CustomRetriever(BaseRetriever):
"""Custom retriever that performs both Vector search and Knowledge Graph search."""
如下:两种index方法
vector_nodes = self._vector_retriever.retrieve(query_bundle)
kg_nodes = self._kg_retriever.retrieve(query_bundle)
如下,根据模式选择两种index查询后结果的合并形式
if self._mode == "AND":
retrieve_ids = vector_ids.intersection(kg_ids)
else:
retrieve_ids = vector_ids.union(kg_ids)
4)root retriever
类似langchain中的tool的概念,定义多个tool,每个tool使用的description来定义适用哪种场景。然后使用RouterQueryEngine来指定包含多个tool。对于不同的query调用不同的tool来输出结果。

代码:llama_index-main/docs/module_guides/querying/router/root.md
query_engine = RouterQueryEngine(
selector=PydanticSingleSelector.from_defaults(),
query_engine_tools=[
list_tool,
vector_tool,
],
)
query_engine.query("<query>")
<!>lllamaindex如何加载本地模型-四种方法
llamaindex的资料比langchain的少,很多介绍用法的上来也都是openai-key。这对于我这样没有key的用户很不友好。所以又得研究下如何加载各种中文大模型,或者各种自微调后模型了。
1)方法1:加载huggface的模型
代码地址 llama_index-main/docs/module_guides/models/llms/usage_custom.md
加载QWen模型实例:https://github.com/QwenLM/Qwen1.5/blob/1ae7e4069ad788b9fdc29859c2f789234af250de/docs/source/framework/LlamaIndex.rst
Example: Using a HuggingFace LLM:使用HuggingFaceLLM接口
import torch
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core import Settings
Settings.llm = HuggingFaceLLM(
model_name="HuggingFaceH4/zephyr-7b-beta",
tokenizer_name="HuggingFaceH4/zephyr-7b-beta",
context_window=3900,
max_new_tokens=256,
generate_kwargs={"temperature": 0.7, "top_k": 50, "top_p": 0.95},
messages_to_prompt=messages_to_prompt,
completion_to_prompt=completion_to_prompt,
device_map="auto",
)
更详细的讲解:llamaindex和QWen的结合搭建流程:
https://mp.weixin.qq.com/s/RwjywuzfswSCKP_lw135YA
langchain结合llamaindex,加载QWen的应用代码
https://github.com/modelscope/modelscope/blob/master/examples/pytorch/application/qwen_doc_search_QA_based_on_langchain_llamaindex.ipynb
2)方法2:加载自己定义的本地模型,或者甚至某个本地模型的api的接口
Example: Using a Custom LLM Model - Advanced,方法:定义一个OURLLM类
代码地址:同上
class OurLLM(CustomLLM):
。。。。。
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
。。。。
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
........
@llm_completion_callback()
def stream_complete(
self, prompt: str, **kwargs: Any
) -> CompletionResponseGen:
.......
使用的时候
# define our LLM
Settings.llm = OurLLM()
# define embed model
Settings.embed_model = "local:BAAI/bge-base-en-v1.5"
# Load the your data
documents = SimpleDirectoryReader("./data").load_data()
index = SummaryIndex.from_documents(documents)
# Query and print response
query_engine = index.as_query_engine()
response = query_engine.query("<query_text>")
print(response)
3)方法3:将模型部署后的api接口作为参数,加载模型,使用OpenAILike包
代码地址:https://github.com/sjtu-xx/obsidian_note/blob/dc225367e2c519b3883bc034c106f0af4e6d5418/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/%E6%A1%86%E6%9E%B6/llama-index.md
源码中example介绍 llama_index-main/docs/examples/llm/localai.ipynb
###使用OpenAILike包
from llama_index.llms.openai_like import OpenAILike
QWEN_72B = "Qwen-72B-Chat"
llm = OpenAILike(api_key="EMPTY", api_base="http://10.xxx/v1", model=QWEN_72B, is_chat_model=True) #此处api_base是部署模型后的包
message = ChatMessage(**{"role": "user", "content": "你好"})
llm.chat([message]).message.content
llm.complete("你好")
###定义向量模型
from llama_index.embeddings import HuggingFaceEmbedding
BGE_LARGE_ZH = "./bge-large-zh-v1.5"
embed_model = HuggingFaceEmbedding(model_name=BGE_LARGE_ZH, trust_remote_code=True)
4)方法4:使用Ollama,加载本地自定义模型
介绍:https://docs.llamaindex.ai/en/stable/module_guides/models/llms/usage_custom/
代码地址:https://github.com/andysingal/llm-course/blob/83048a5312d60e643e9f4396ddcbb628b52ba5f2/llama-index/llama_index_example/04_flask_demo.py
##代码
# 定义你的LLM
llm = Ollama(model="pxlksr/defog_sqlcoder-7b-2:Q8")
llm.temperature = 0.2
llm.base_url = "http://1.92.64.112:11434"
# 定义你的服务上下文
model_dir = os.path.abspath('data/embed_model/bge-small-en-v1.5')
service_context = ServiceContext.from_defaults(
llm=llm, embed_model="local:" + model_dir
)
关于ollama的介绍
https://blog.csdn.net/q20010619/article/details/135849369
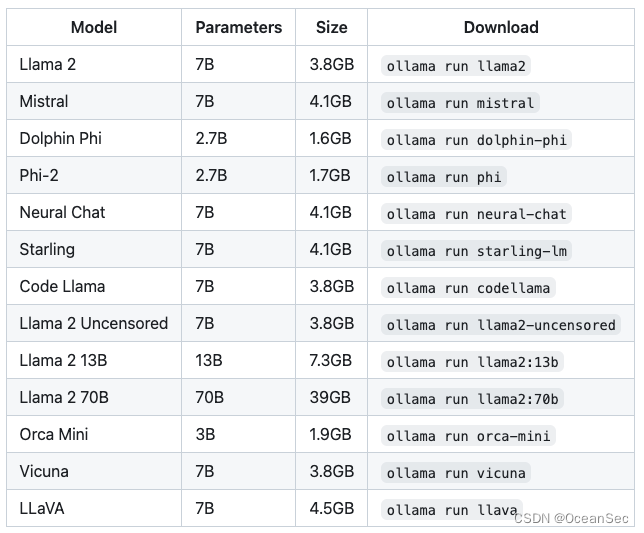
一个可以快速部署大模型的框架,支持windows,mac上部署
ollama run llama2 一个命令就可以部署















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









