







今天分享一篇当日HuggingFace榜单第一的文章。
文章标题:Law Of Vision Representation In Mllms
文章地址:https://arxiv.org/pdf/2408.16357
作者单位:斯坦福大学,加州大学伯克利分校
1STANFORD UNIVERSITY 2UC BERKELEY
Abstract
作者提出了一种“视觉表征定律”(以多模态大型语言模型 (MLLM) 为背景),揭示了交叉模态对齐、视觉表征的一致性与MLLM性能之间的紧密关联。作者通过跨模态联接一致性及视觉表征的一致性指标(AC分)来量化这两个因素,并在包括13种不同的视觉表示设置在内的多轮试验中发现,AC分数和模型性能之间具有线性关系。
通过对这一关系的利用,仅优化视觉表征而不需每次对语言模型进行微调(从而实现99.7%的计算成本降低),即能达成作者的目标。相应的代码可以通过访问 https://github.com/bronyayang/Law_of_Vision_Representation_in_MLLMs 下载获得。
We present the "Law of Vision Representation" in multimodal large language models (MLLMs). It reveals a strong correlation between the combination of cross-modal alignment, correspondence in vision representation, and MLLM performance. We quantify the two factors using the cross-modal Alignment and Correspondence score (AC score). Through extensive experiments involving thirteen different vision representation settings and evaluations across eight benchmarks, we find that the AC score is linearly correlated to model performance.
By leveraging this relationship, we are able to identify and train the optimal vision representation only, which does not require finetuning the language model every time, resulting in a 99.7% reduction in computational cost. The code is available at https://github.com/bronyayang/Law_of_Vision_ Representation_in_MLLMs.
1. 引言
1 Introduction
当前的多模态大型语言模型(MLLMs)通过将预训练的视觉编码器与强大的语言模型结合,实现了显著的进步(Chen et al., 2024a; Liu et al., 2024e;d)。作为通用MLLM的核心组成部分,视觉表示至关重要。许多研究者使用CLIP(Radford et al., 2021)作为主要的图像特征编码器,但其局限性越来越明显(Tong et al., 2024b; Geng et al., 2023; Yao et al., 2021)。因此,对替代视觉表示以及多个视觉编码器的混合的探索变得活跃起来(Tong et al., 2024a; Lin et al., 2023)。尽管对这一领域的关注不断增加,但选择视觉表示的方法往往只基于经验。研究者通常在特定的MLLM上测试一组视觉表示,并选择在基准任务中性能最高的一个。然而,这种方法受到可测试呈现数量的限制,并且不足以解决某些特征表示为何能比其他表现更好的根本原因问题。结果,对于具体MLLM的最佳视觉表示往往是通过实践效能而非对有助于成功特性深入理解来确定的。关于什么使得特征表示能够获得最高性能的问题,仍然难以解答。
为了弥补对何种视觉表示对MLLMs最佳的理解不足,作者提出了MLLM中的视觉表示法则。旨在解释影响模型性能的主要因素,揭示视觉表示的重要属性。作者的研究揭示了一个关键发现:所选视觉表示的跨模态对齐(Alignment)和对应(Correspondence)对模型的表现强相关。具体而言,选择的视觉表示的跨模态对齐与对应度提高模型性能。作者定义了量化这一关系的交叉对齐得分(AC score),它衡量了在视觉表示中的跨模态对齐和对应。这项得分与模型性能之间显示了线性关系,相关系数为95.72%。
此外,视觉表示法则有助于指导选择MLLMs的最佳视觉表示方法。原本这一过程极其耗费成本,因为即使是图像编码策略微小的变化,比如更改编码器类型、修改分辨率或测试特征组合,都需要对语言模型进行重新调整(Lin et al., 2024)。例如,使用顶尖的数据效率高的MLLM管道,采用7B个参数的语言模型时,仅需测试文中使用的10种编码器就需要3,840小时的NVIDIA A100 GPU时间,成本约为$20,0001。
对于测试更进一步的编码器,则会导致成本线性增加。尤其是在近期对特征组合的流行趋势下,往往能得到更好性能的结果,这需要对视觉编码器进行组合测试。针对10种编码器的所有可能组合有10^3+种,导致了能源消耗和费用指数级别的增长。这一过程耗费约100,000千瓦时2的电量,足够一辆电动汽车绕地球行驶13次。
因此,作者首次提出了一项策略,交叉对齐政策(AC policy),该方策在给定的搜索区间内选择最佳视觉表示,并使用其得分进行。与传统方法依赖于基准测试性能不同,此策略可以扩展搜索空间——允许考虑更多的视觉展示——而无需额外成本。
作者证明了这一方法相比随机搜索能提高准确性同时增加效率。在以13个设置为界的搜索空间中识别优化配置的成功率达到了96.6%,通过仅对语言模型进行了三项微调就实现了这一点。
Current multimodal large language models (MLLMs) (Chen et al., 2024a; Liu et al., 2024e;d) have achieved remarkable advancements by integrating pretrained vision encoders with powerful language models (Touvron et al., 2023; Zheng et al., 2023). As one of the core components of a general MLLM, the vision representation is critical. Many researchers have utilized CLIP (Radford et al., as the primary image feature encoder, but its limitations are increasingly noticeable (Tong et al., 2024b; Geng et al., 2023; Yao et al., 2021). As a result, alternative vision representationand the combination of multiple vision encoders are being actively explored (Tong et al., 2024a; Lin et al., 2023). Despite this growing attention, the selection of vision representation has largely been empirical. Researchers typically test a set of vision representations on a specific MLLM and choose the one that yields the highest performance on benchmark tasks. This approach, however, is constrained by the number of representations tested and does not address the underlying factors that make certain feature representations perform better than others. As a result, the optimal vision representation for a specific MLLM is often determined by empirical performance rather than a deep understanding of the features that contribute to success. The question of what fundamentally makes a feature representation achieve the highest performance remains largely unanswered.
To address this gap in understanding what makes a vision representation optimal for MLLMs, we propose the Law of Vision Representation in MLLMs. It aims to explain the key factors of vision representation that impact MLLM benchmarks performance. Our findings reveal that the crossmodal Alignment and Correspondence (AC) of the vision representation are strongly correlated with model performance. Specifically, an increase in the AC of the selected vision representation leads to improved model performance. To quantify this relationship, we define an AC score that measures cross-modal alignment and correspondence in vision representation. The AC score and model performance exhibit a linear relationship, with a coefficient of determination of 95.72%.
Furthermore, the Law of Vision Representation guides the selection of an optimal vision representation for MLLMs. Originally, this process was extremely costly because even subtle changes in 1 vision encoding methods—such as switching encoder types, altering image resolution, or testing feature combinations—require finetuning the language model (Lin et al., 2024). For example, using a top data-efficient MLLM pipeline with a 7B language model requires 3,840 NVIDIA A100 GPUhours to test the 10 encoders used in this study, amounting to a cost of approximately $20,0001.
Testing additional encoders leads to a linear increase in cost. Moreover, the recent trend of feature combination, which often results in better performance, necessitates combinatorial testing of vision encoders. Testing all possible combinations of 10 encoders results in 1023 combinations, exponentially increasing the cost and energy consumption. This process consumes approximately 100,000 kilowatt-hours2, enough to drive an electric vehicle around the Earth 13 times.
Thus, we are the first to propose a policy, AC policy, that selects the optimal vision representation using AC scores within the desired search space. Unlike traditional methods that rely on benchmarking performance, the AC policy enables the expansion of the search space—allowing for an increased number of vision representations to be considered—without incurring additional costs.
We demonstrate that this approach enhances both accuracy and efficiency compared to randomly searching for the optimal representation. The policy successfully identifies the optimal configuration among the top three choices in 96.6% of cases, with only three language model finetuning across a 13-setting search space.
2 Related Works
2.1 Vision For Mllms
近期的研究探讨了MLLM中的各种视觉表示(Beyer等人,2024年;Ge等人,2024年;Liu等人,2024年e;Wang等人,2024年;Sun等人,2023年;Luo等人,2024年)。有趣的是,一些发现表明,在CLIP家族之外(Cherti等人,2023年;Zhai等人,2023b;Li等人,2022年),仅依赖于外部编码器(如DINOv2 [Oquab等人,2023年] 和Stable Diffusion [Rombach等人,2021年])通常会带来较低的性能分数(Karamcheti等人,2024年;Tong等人,2024a)。
然而,并列使用这些编码器的特征与CLIP特性--如在单词或通道维度上堆叠图像嵌入--显著提高了超过单独使用CLIP的表现(Tong等人,2024a;b;Liu等人,2024年c;Kar等人,2024年)。研究者直觉性地认为这些额外的编码器提供了更精细的能力,但没有研究彻底分析了性能变化的根本原因(Wei等人,2023年;Lu等人,2024年)。这表明最优视觉表示的相关属性尚未完全被理解。
Recent studies have explored various vision representations in MLLMs (Beyer et al., 2024; Ge et al.,2024; Liu et al., 2024e; Wang et al., 2024; Sun et al., 2023; Luo et al., 2024). Interestingly, some findings indicate that relying solely on encoders outside of the CLIP family (Cherti et al., 2023; Zhai et al., 2023b; Li et al., 2022), such as DINOv2 (Oquab et al., 2023) and Stable Diffusion (Rombach et al., 2021), often leads to lower performance scores (Karamcheti et al., 2024; Tong et al., 2024a).
However, combining features from these encoders with CLIP features—such as concatenating image embeddings in the token or channel dimension—significantly enhances performance beyond using CLIP alone (Tong et al., 2024a;b; Liu et al., 2024c; Kar et al., 2024). Researchers intuitively suggest that these additional encoders provide superior detail-oriented capabilities, but no studies have thoroughly analyzed the underlying causes of the performance change (Wei et al., 2023; Lu et al., 2024). This suggests that the attributes of an optimal vision representation remain not fully understood.
2.2 跨模态对齐
2.2 Cross-Modal Alignment
跨模态对齐指的是图像和文本特征空间之间的对齐(段等,2022)。随着文本-图像对比学习的引入(Radford 等人,2021;Jia 等人,2021),这个概念出现了。尽管目前的多语言模型利用了通过对比预训练的图像编码器,但实现有效对齐的挑战仍然存在(叶等,2024;翟等,2023a;Woo 等人,2024)。尽管努力批评CLIP家族表示的局限性和探索替代视觉表征,许多方法仍然依赖于对比预训练编码器或在完全消除它们的同时添加对比损失(张等,2024a;Lu 等人,2024;东等,2024a;b; 刘等,2024b)。在作者的工作中,作者指出,在视觉表征中有对齐对于提高模型性能和数据效率至关重要。如果没有预先对齐的视觉表示,需要进行大量的数据分析预训练以实现语言模型中的跨模态对齐(Ge 等人,2024;陈等,2024b;李等,2024b)。
Cross-modal alignment refers to the alignment between image and text feature spaces (Duan et al., 2022). This concept emerged with the introduction of text-image contrastive learning (Radford et al., 2021; Jia et al., 2021). Although current MLLMs utilize contrastively pretrained image encoders, the challenge of achieving effective alignment persists (Ye et al., 2024; Zhai et al., 2023a; Woo et al.,2024). Despite efforts to critique the limitations of CLIP family representations and explore alternative vision representations, many approaches continue to rely on contrastively pretrained encoders or adding contrastive loss without fully eliminating them (Zhang et al., 2024a; Lu et al., 2024; Tong et al., 2024a;b; Liu et al., 2024b). In our work, we point out that alignment in vision representation is essential for improved model performance and is crucial for data efficiency. Without pre-aligned vision representations, extensive data pretraining is required to achieve cross-modal alignment within the language model (Ge et al., 2024; Chen et al., 2024b; Li et al., 2024b).##2. 3视觉对应关系
2.3 Visual Correspondence 视觉对应
视觉对应是计算机视觉的基本组成部分,精确的对应关系能够显著提升任务性能,如图像检测(Xu等人,2024; Nguyen与Meunier,2019),视觉生成(Tang等人,2023;Zhang等人,2024b)和跨语言模型(LLMs)(Liu等人,2024a)等任务。对应关系通常被分为语义性和几何性对应的两类。语义对应(Zhang等人,2024b; Min等人,2019)涉及匹配代表相同语义概念但并不一定代表同一实例的点。而几何对应(Sarlin等人,2020;Lindenberger等人,2023),则需要在图像之间匹配完全相同的点位,这通常是低级视觉任务如姿态估计(Sarlin等人,2020;Lindenberger等人,2023;Zhang与Vela,2015)、以及SLAM任务等所必需的。
多组分大型语言模型的相关研究指出CLIP家族的图像表示“缺乏视觉细节”(Lu等人,2024;Tong等人,2024b;Ye等人,2024)。作者从对应关系的概念来解释这一现象:当前的多模态大语言模型将图片转换为嵌入向量,每个向量代表图像中的一个像素区域。具有高对应性的图象特征会在相似语义内部图像块上增加内在关联性,从而使得更多详细信息的检索成为可能。
Visual correspondence is a fundamental component in computer vision, where accurate correspondences can lead to significant performance improvements in tasks, such as image detection (Xu et al., 2024; Nguyen & Meunier, 2019), visual creation (Tang et al., 2023; Zhang et al., 2024b), and MLLMs (Liu et al., 2024a), etc. Correspondences are typically categorized into semantic- and 1https://replicate.com/pricing 2https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet.pdf geometric-correspondences. Semantic correspondences (Zhang et al., 2024b; Min et al., 2019) involve matching points that represent the same semantic concept not necessarily representing the same instance. Geometric correspondences (Sarlin et al., 2020; Lindenberger et al., 2023), on the other hand, require matching the exact same point across images, which is often crucial for low-level vision tasks, such as pose estimation (Sarlin et al., 2020; Lindenberger et al., 2023; Zhang & Vela, 2015),and SLAM tasks, etc.
Several studies have pointed out that the CLIP family's vision representation "lacks visual details" (Lu et al., 2024; Tong et al., 2024b; Ye et al., 2024). We explain this observation through the concept of correspondence. Current multi-modal large language models (MLLMs) convert images into embeddings, with each embedding representing a patch of the image. Image features with high correspondence increase the similarity within internal image patches on similar semantics, thereby enabling the retrieval of more detailed information.
视觉表示的三条定律在MLLMs中的应用
3 Law Of Vision Representation In Mllms
作者引入了视觉表示在跨模大语言模型(MLLMs)中的视知觉表征定律。这一定律表明,MLLM的性能(Z),可以通过以下两个因素来估算:跨模对齐(A)和视知觉对应的度量(C)。假定视知觉作为唯一独立变量时,其他组件(例如语言模型和对齐模块)保持固定不变的情况下,这一关系可以表示如下:

We introduce the Law of Vision Representation in Multimodal Large Language Models (MLLMs).
It states that the performance of a MLLM, denoted as Z, can be estimated by two factors: crossmodal alignment (A) and correspondence (C) of the vision representation, assuming vision representation is the sole independent variable while other components (e.g., language model and alignment module) remain fixed.
3.1 理论依据
在这一部分,作者理论分析了A和C增加是如何提高模型性能。当视觉表示显示出跨模态对齐度高并能够准确对应时,MLLM展现出以下希望拥有的特性:
- 在训练MLLM过程中, 如果视觉表示与语言分布之间高度预对齐,则预训练的语言模型在最后微调时将减少不同模态间差距的计算努力。在A.1节中,作者提供了理论依据以说明对准良好的多模态数据在finetune上等同于只含有文本的数据集——这就消除了超越语言finetune之外的额外工作量。这种效率可以带来性能提升,在有限训练样本的场景下尤为显著。 - 如果视觉表示能够保证准确对应,则图像嵌入的注意力是精确的。 因此,MLLM在可视化内容上的聚焦变得更为细致,捕捉到即使是文本对图像关注无法单独推导出的细节,从而对图像有更深入的理解。作者提供了A.2节中的理论依据进行证明。
3.1 THEORETICAL JUSTIFICATION
In this section, we theoretically analyze how an increase in A and C leads to improved model performance. When a vision representation demonstrates high cross-modal alignment and accurate correspondence, the MLLM exhibits the following desired properties:
-
When training a MLLM, if the vision representation is closely pre-aligned with the language distribution, the pretrained language model requires less computational effort to bridge the gap between different modalities during finetuning. In Section A.1, we provide theoretical justification that finetuning on well-aligned multimodal data is about equivalent to finetuning on text-only data, eliminating additional effort beyond language finetuning. This efficiency can lead to improved performance, especially in scenarios where the available training data for finetuning is limited.
-
If the vision representation ensures accurate correspondence, the attention within the image embeddings is precise. Consequently, the MLLM develops a refined focus on visual content, capturing even details that cannot be derived solely from text-to-image attention, leading to a more detailed interpretation of the image. We provide theoretical justification in Section A.2.
3.2 实证依据
3.2 Empirical Justification
在这一节中,作者通过经验的方式展示AC因素与模型表现强相关,为了量化AC与模型表现之间的关联性,作者将提出方法来测定跨模态的对齐和同模代表间的联系:
-
当提及跨模态的对齐时,作者要比较的是相同概念下的图像与文本嵌入。然而在实现上寻找相同的概念很难,原因在于对齐问题。对此作者将选择CLIP视觉内表征作为参考基准,并计算来自CLIP嵌入 (\hat{E})和目标视图表示嵌入 (E)的标量矢量内积向量化值 (S_C)最大公因数间的相似度(SC)。其中 n 为图像样本的总数,E(v)i = MLP(Fi)(v) 为第 i 幅图像的视觉特征 F 产生的第 v 个嵌入向量。
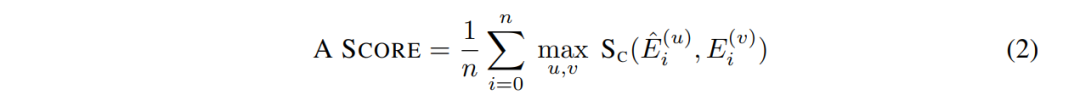
-
要计算对应分数,作者从一对匹配的图片中抽取特征,得到来自特定来源和目标对的 (F_i^s) 和 (F_i^t)。给定地实关键点集合 ({p{s1},...,p{sm}}),使用特征获取预测的关键点 ({p{t1},...,p{tm}})。对应分数是通过以下公式计算的百分比正确的关键点(PCK):
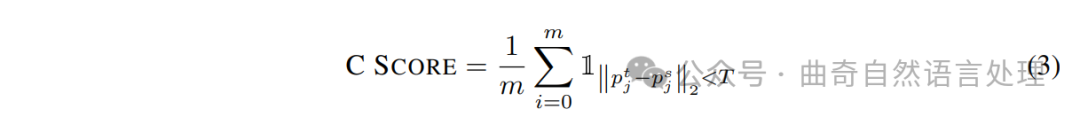
其中(T)定义为图像中实例对象的边界框大小的比例。最后,AC评分为A分和C分的二次多项式变换:
最终,AC 分数是 A 和 C 分数的二次多项式变换:
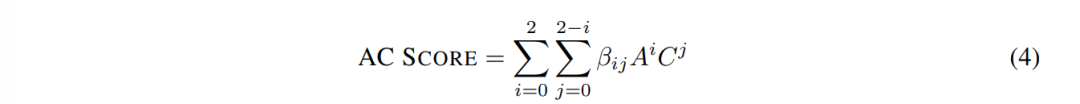
结果
作者使用13个视觉表示,在四大视觉为基础的MLLM基准上拟合了一个简单线性回归模型。如图1所示,使用视觉表征的AC分数获取的平均决定系数(R2)是95.72%。
作为对比,作者也用相同的参数拟合了以随机得分、A分数或者说C分数单独作为输入的模型,并在这些变量的基础上做了一次多项式变换。作者可以看到,仅利用单个因素或随机赋分的方法所获得的结果和最终性能相关性远低于使用AC分数的情况。这一结果充分证实了视觉表征定律的存在-即AC分数与MLLM性能之间存在高度相关性。详细的阐述见5.4节。
Results. We fit a simple linear regression model using 13 vision representations across 4 vision-based MLLM benchmarks. As shown in Figure 1, the average coefficient of determination (R2) obtained is 95.72% when using the AC score of the vision representations.
For comparison, we also fit models using 13 random scores, the A score alone, and the Cscore alone, all with polynomial transformations. The random scores and single-factor models show significantly lower correlations with performance. This result highlights the strong correlation between the AC score and MLLM performance, validating the Law of Vision Representation. Refer to Section 5.4 for details.$$\vdash\ \ \ \mathrm{AC\POLICY}$$
$$\vdash\ \ \ \mathrm{AC\POLICY}$$
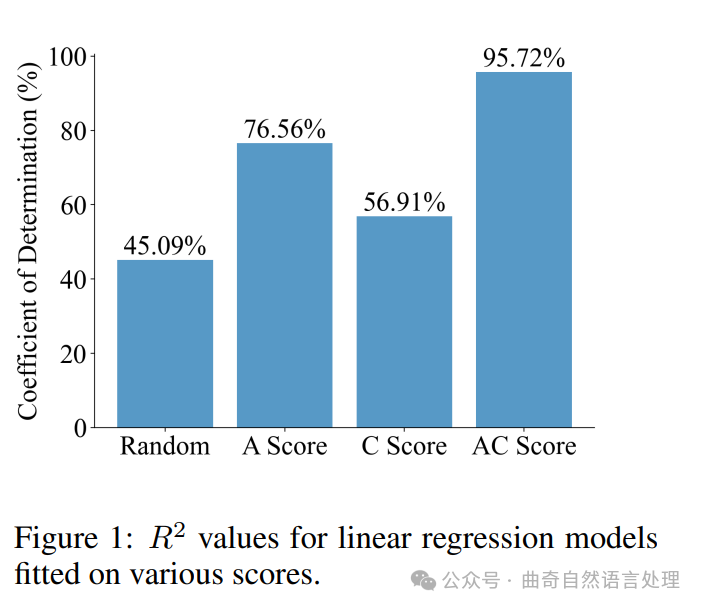
图1:在各种得分上拟合的线性回归模型的R2值。
Figure 1: R2 values for linear regression models fitted on various scores.
4 AC POLICY
问题表述。一般的MLLM架构包括一个冻结的视觉编码器,后面跟随可训练连接(对齐模块)和语言模型,类似于LLaVA(刘等人,2024e)中的设置。为了确定k个视觉表示中的最佳输出,原本需要将LLM细调k次,从而使得k的增长难度较大。因此,给定N个视觉编码器,作者提议使用AC策略(如图2所示),以有效地从所有可能的特征组合中,估计k个视觉表示中的最优视觉表示所组成的搜索空间内的最佳视觉示例。通过仅对k′个LLM进行细调以获取下游性能,并允许在k保持较小成本的情况下按比例缩放,其中k′远小于k。
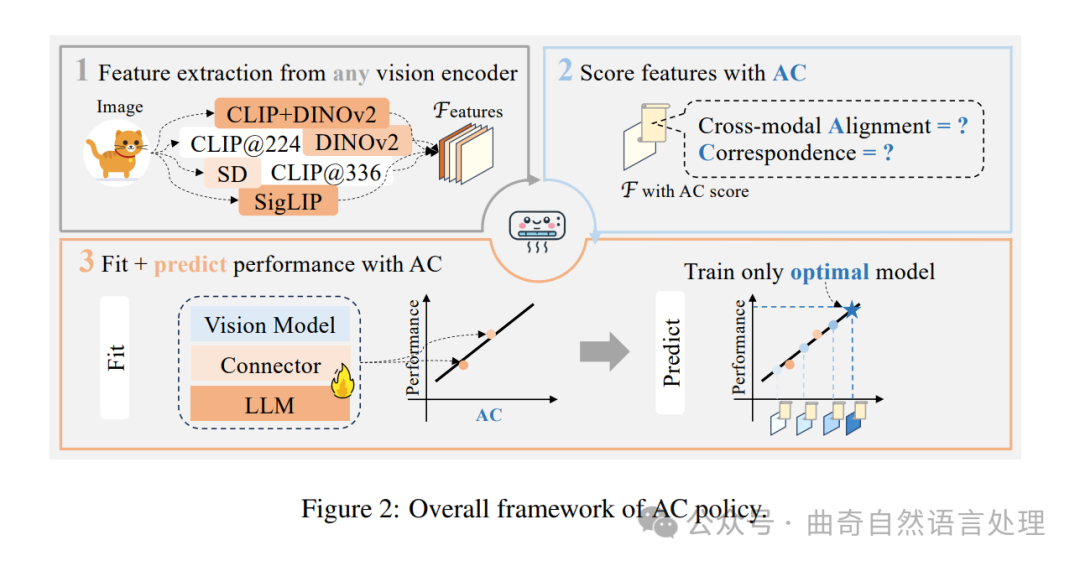
策略适合性(Policy Fitting)。将X ∈ R k×6 表示为包含搜索空间中所有视觉表示AC评分的矩阵。作者从X中随机抽取k′个数据点,并将其表示为Xs ∈ R k′×6 ,作为线性回归模型的输入:
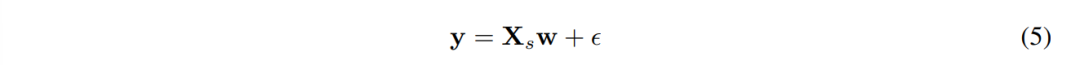
Problem Formulation. A general MLLM architecture consists of a frozen vision encoder followed by a trainable connector (alignment module) and the language model, similar to the setup in LLaVA (Liu et al., 2024e). To determine the optimal out of k vision representations, we originally needs finetune LLM k times, making the scaling of k difficult. Therefore, given N vision encoders, we propose AC policy, as illustrated in Figure 2, to efficiently estimate the optimal vision representation from a search space consisting of k vision representation out of all 2 N − 1 possible feature combinations. We finetune only k′ LLMs to obtain downstream performance, allowing k to scale without significant cost, where k′ ≪ k.
采样策略。k'的选择可以影响函数拟合,进而影响预测的准确性。为了避免在A和C得分接近的情况下采样点,作者采用基于坐标位置的采样策略。
(k视图表示中,A和C的标准化分数对作为坐标的(A,C),为了保证具有多样性,作者将图像区域细分到4个相等的部分进行划分。
然后删除空域以及包含已采样点的区域。下一个数据点随机选择自剩余区域。
结果。在表1中,作者表明,在有限搜索空间的情况下(例如,在这种情况下为13个设置) , AC策略始终能够预测最优化视图表示并采用最少资源。作者的目标是一较小子集的空间进行细调仍然在一个顶3内识别最优视图表示(Recall@3)而不需要对进行大量的超参数调优而达到在超过90%的Recall@3,然而如果随机选择一部分来训练的话,则需要12个从总数13中获取以实现超过90%的Recall@3。相比之下, AC策略平均只需要3.88次全训练运行就可达到89.69%的Recall@3。在5.5节中有详细说明。
Here, w ∈ R6is the vector of model parameters, ϵ ∈ Rk′is the vector of error terms, and y ∈ Rk′represents the downstream performance on a desired benchmark.
Sampling Strategy. The selection of k′can impacts the function fit and, consequently, the accuracy of predictions. To avoid sampling points that are too close in terms of their A and C scores, we employ a sampling strategy based on the coordinates.
The normalized A and C score pairs of k vision representation can be plotted on a 2D graph as coordinates (A, C), To ensure diverse sampling, we divide the graph into regions. For each iteration j in which the total sampled points do not yet fulfill k′, we divide the graph into 4 jequal regions.
We then remove empty regions and those that contain previously sampled points. The next data point is randomly selected from a remaining region. Results. In Table 1, we show that AC policy consistently predicts the optimal vision representation with minimal resources, given a finite search space—in this case, 13 settings. Our goal is to finetune only a small subset of the search space while still identifying the optimal vision representation within the top-3 predictions (Recall@3). However, if we randomly select a subset to train on, we need 12 out of 13 finetuning to achieve over 90% Recall@3. In contrast, the AC policy requires only 3.88 full training runs on average to reach 89.69% Recall@3. Refer to Section 5.5 for details.
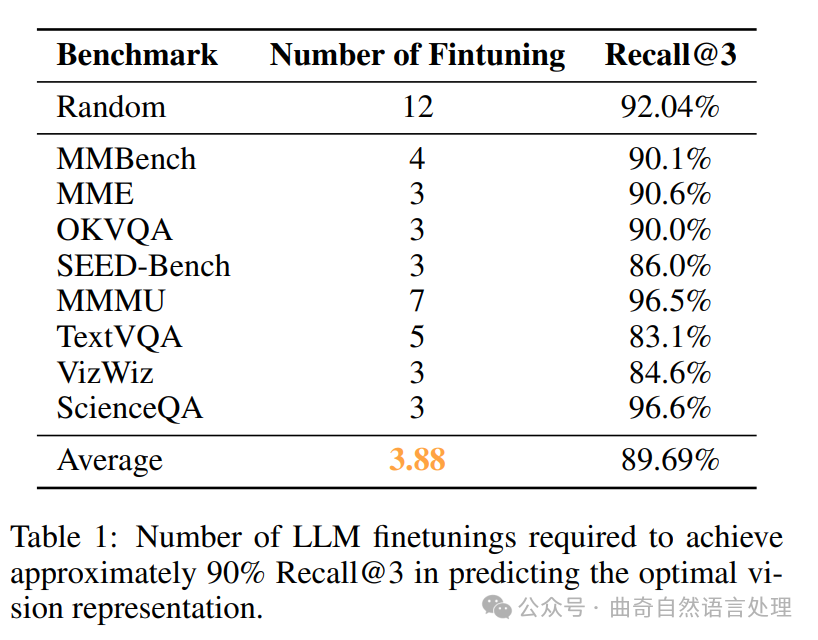
表格1:预测最优视图表示时,达到约90%召回率( recalls@3)所需的LLM微调次数。
5 实验结果细节
5 Empirical Result Details
5.1 实验设置
5.1 Experiment Settings
为了作者特定的MLLM管道,作者遵循LLaVA (Liu et al., 2024e)中描述的培训过程、通用架构和数据集。培训流程分为两个阶段:第一阶段,作者使用包含558,000个样本的LLaVA 1.5数据集训练具有两层的GeLU-MLP连接器;在第二阶段,作者在扩展后的LLaVA 1.5数据集上(含665,000个样本)同时对连接器和语言模型进行培训。需要注意的是,在每一轮培训中,都将所有因素保持不变,除了视觉表达方式的变化。本论文中包含的13种视觉表示详细信息见表2。作者使用了4个基于视觉的数据集作为MLLM基准评估,包括MMBench (Liu et al., 2023), MME (Fu et al., 2023), OKVQA (Marino et al., 2019), 随后是SEED-Bench (Li et al., 2024a)。此外,还涉及到包含QCR评估的四个额外基准:包括MMBU (Yue et al., 2024),TextVQA (Singh et al., 2019), VizWiz (Gurari et al., 2018),以及ScienceQA (Lu et al., 2022)。
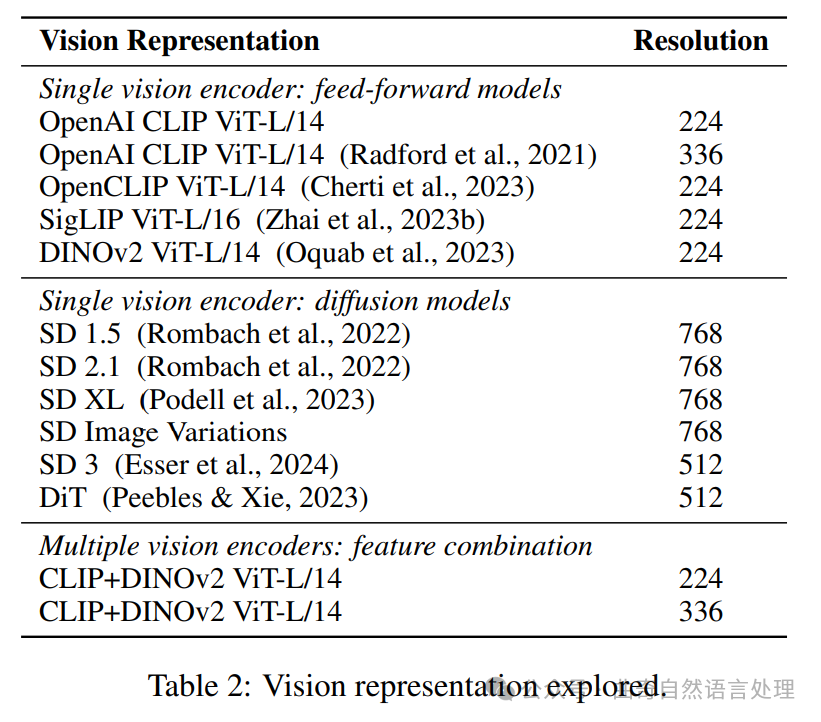
表2:探索的不同视觉表示:| 视觉表示 | 分辨率 | 单一视觉编码器(前馈模型) | OpenAI CLIP ViT-L/14(224)| OpenAI CLIP ViT-L/14 (Radford et al., 2021)(336)| OpenCLIP ViT-L/14 (Cherti et al., 2023)|(224) | SigLIP ViT-L/16 (Zhai et al., 2023b) | DINOv2 ViT-L/14(224) | 多重视觉编码器(特征组合)| CLIP+DINOv2 ViT-L/14(224)| CLIP+DINOv2 ViT-L/14(336)
For our specific MLLM pipeline, we follow the training procedure, general architecture, and dataset outlined in LLaVA (Liu et al., 2024e).
The training process consists of two stages: in the first stage, we train a 2-layer GeLU-MLP connector using the LLaVA 1.5 dataset with 558Ksamples. In the second stage, we train both the connector and the language model on the expanded LLaVA 1.5 dataset with 665K samples. It is important to note that for each training, all factors are held constant except for the vision representation being changed. The 13 vision representation in this paper are outlined in Table 2. The MLLM benchmarks used in this paper includes 4 vision-based benchmarks, MMBench (Liu et al., 2023), MME (Fu et al., 2023), OKVQA (Marino et al.,2019), SEED-Bench (Li et al., 2024a), and 4 QCR-based benchmarks including, MMMU (Yue et al.,2024), TextVQA (Singh et al., 2019), VizWiz (Gurari et al., 2018), ScienceQA (Lu et al., 2022).
Vision Representation Resolution Single vision encoder: feed-forward models OpenAI CLIP ViT-L/14 224 OpenAI CLIP ViT-L/14 (Radford et al., 2021) 336 OpenCLIP ViT-L/14 (Cherti et al., 2023) 224 SigLIP ViT-L/16 (Zhai et al., 2023b) 224 DINOv2 ViT-L/14 (Oquab et al., 2023) 224 Single vision encoder: diffusion models SD 1.5 (Rombach et al., 2022) 768 SD 2.1 (Rombach et al., 2022) 768 SD XL (Podell et al., 2023) 768 SD Image Variations 768 SD 3 (Esser et al., 2024) 512 DiT (Peebles & Xie, 2023) 512 Multiple vision encoders: feature combination CLIP+DINOv2 ViT-L/14 224 CLIP+DINOv2 ViT-L/14 336 Table 2: Vision representation explored.五点二 雅思成绩
5.2 Ac Score
为了计算跨模态对齐分数,作者执行第1阶段训练,使用所有视觉表示来获取MLP。该过程所需的计算量远少于第2阶段,仅涉及可训练参数的0.298%。针对每个基准测试项,作者随机抽取100张图像并将对齐分数计算平均值。对于对应分数, 作者遵循常见做法使用SPair-71k(Min等人, 2019)数据集进行计算。因此,每个基准都有自己的对齐分数,而对应分数在所有表示之间保持一致。
To compute the cross-modal alignment score, we perform stage 1 training with all the vision representations to obtain the MLPs. This process requires significantly less computation than stage 2, involving only 0.298% of the trainable parameters. The alignment score for each benchmark is averaged across 100 randomly sampled images. For the correspondence score, we follow common practices using the SPair-71k (Min et al., 2019) dataset. Consequently, each benchmark has its own alignment score, while the correspondence score remains consistent across all representations.
5.3 特征提取
5.3 Feature Extraction
卷积模型和得分计算都涉及到图像特征提取。接下來,本节详细介绍获得两种视觉表示的方法。
从前馈模型得到的视觉表征。给定一张图像I ∈ RH×W×3,作者分别以原始形式处理它(用于U-Net模型)或打块形式处理它(用于变换器模型)。对于变换器,作者提取最后一个隐藏状态F ∈ Rl×c, 其中l为序列长度,c为隐藏维度。针对U-Net模型,作者采取第一层上采样后的中间激活F ∈ RHˆ ×Wˆ ×c 。注意,这两种模型之间的特征可以在重塑和平铺处理后在序列和网格格式之间互换。为了保持一致性,在下文的讨论中假设所有特征都已预转换成相同格式。
从扩散模型得到视觉表征。扩散模型主要用于通过多步去噪生成图像(Xu等人, 2024; 2023; Zhang等人, 2024b; Tong等人, 2024a) 。具体来说,给定一个图像I ∈ RH×W×3 , 作者首先对I的VAE编码表示添加噪音:
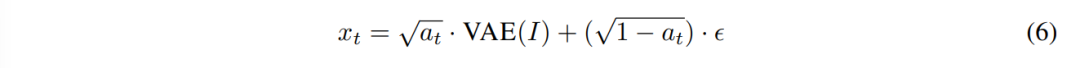
ϵ~N(0,I),且at由噪声调度确定。请注意,作者通过将t设置为1来利用小噪点策略。在这种情况下,扩散模型仅对噪声潜变量进行一次去噪操作,并将一步去噪的潜变量作为视觉表示特征处理。
Both MLLM training and score computation involve image feature extraction. Below, we introduce the approach for obtaining two types of vision representations.
Vision Representation from Feed-forward Models. Given an image I ∈ RH×W×3 we process it either in its raw form for U-Net models or in a patchified form for transformer models. For transformers, we extract the last hidden state F ∈ Rl×c where l is the sequence length and c is the hidden dimension. In the case of the U-Net model, we take the intermediate activation F ∈ RHˆ ×Wˆ ×cafter the first upsampling block. Note that the features from these two types of models are interchangeable between sequence and grid formats through reshaping and flattening. For consistency, the following sections assume that all features have been pre-converted into the same format.
Vision Representation from Diffusion Models. Diffusion model is primarily used for generating images via multi-step denoising, yet a recent trend is to use diffusion model as the vision representation model (Xu et al., 2024; 2023; Zhang et al., 2024b; Tong et al., 2024a). Specifically, for diffusion models, given an image I ∈ RH×W×3, we first add noise to the VAE-encoded representation of I:$t_{t}$ 的平均值-V。
where ϵ ∼ N (0, I) and at is determined by the noise schedule. Note that we utilize the little-noise strategy by setting the t = 1. In that case, the diffusion model only denoises the noise-latents once and we treat the one-step denoising latents as the vision representation features.
5.4 视觉表示的额外结果
5.4 Additional Results On The Law Of Vision Representation
第3部分 表達了一种有機的A类分数与C类分数之间的关系,这是由A/B分数在OCR识别中表现出来的。作者观察到当在文本数据集中使用A/C项时,相比于其他模式下会有更好的表现且保持了较高的相关性。尽管存在一些异常,如第一张表所示的基准测试与OCR分数的线性关系并不明显,在实际应用中这并不能提供足够准确的结果。在处理多标签问题时,作者发现C类数据的表现更优,而在对包含文本信息的图像做分类的问题上效果相对较弱。
第3部分通过分析了不同特征之间的关联来解释表1和4中的结果,并给出了具体原因描述。其中,AC分数与MLLM性能的相关性更强,这可能是因为当MLLM模型在A/B类数据上表现良好时,它在C类数据上的性能也就相应提高了。为了探究这种相关性的性质以及背后的原因,作者在不同转换方式(线性或二次多项式)下比较了数据的调整,并将它们用于模型预测中。
第部分中的关系表明,通过添加基线来分析和评估模型的表现是必要的,这样做可以使作者更准确地理解C类分数的作用及其与其他类别的相关性。尽管AC分数在性能上通常优于其他设置(如表3所示),但第二项发现也显示,在一些特定的应用场景下将其表现提升至最高水平需要对A、C得分进行非线性调整并采取合适的特征处理方法。
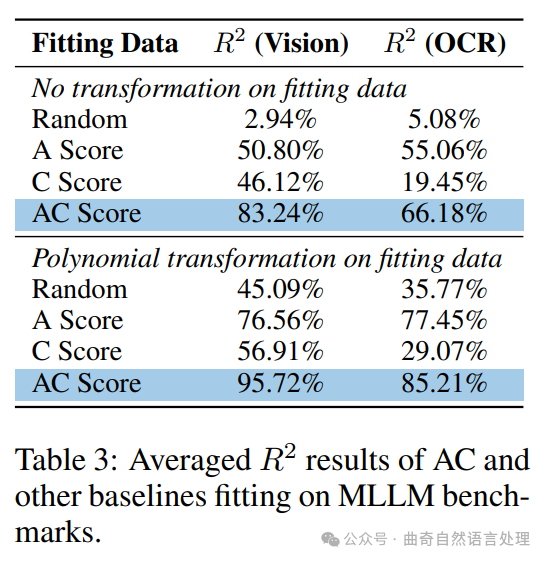
另外,从表格中3可以看出,当只考虑文本信息时(如第一张表所示的Ocr基准测试结果),与模型性能的关系较为松散。这可能是因为这些数据集在实际情况下无法全面捕获所有类型的文本内容,例如多标签场景下的情况就需要综合考虑不同类别之间的相互关系。
综上所述,在预测文本相关任务中的表现时使用AC分数而非单一的A/B分类指标可能更加合理和有效。因此,在未来的研究或实践中需要对数据预处理、特征提取和模型训练过程中进行适当的调整,并在多种设置之间权衡以找到最佳组合策略来获得更高的性能提升。
在表7(用于详细解释第3部分发现)中,作者看到了与文本相关的AC分数在不同场景下的表现差异情况。虽然其中一些比较可能看似互异,但这些结果都揭示了A、B和C类数据集之间的复杂关系,并表明某些情况下调整特征权重或选择更合适的分类策略将有助于获得更好的OCR任务效果。
因此,总体而言,该研究表明改进对含有文本信息的图像的理解和处理是提升模型性能的关键。通过合理的特征工程和使用更先进的方法来整合多种类型的信息(如结合A、B和C类得分),可以进一步优化预测效果并提高准确性。
In Section 3, we demonstrate the strong correlation between the AC score and MLLM performance by analyzing the coefficient of determination (R2) obtained from fitting a linear regression model. In this section, we further ablate the experiments by adding baselines, fitting model performance with random scores, A scores, and C scores separately. Additionally, we explored the relationship between the A score and C score by applying two different data transformations: no transformation and second-degree polynomial transformation. We avoid higher-degree transformations to prevent overfitting, which could obscure the true relationship between A and C scores.
As shown in Table 3, the results indicate that using the ACscore consistently outperforms all other settings in terms of R2 values. While this observation holds regardless of transformation, applying a second-degree polynomial transformation to the A and C scores yields the highest correlation with model performance. This suggests an inherent trade-off between A and C scores: vision representations with high cross-modal alignment often exhibit lower correspondence, and vice versa.
Interestingly, we observe a lower correlation between OCR-based benchmark performance and Cscores, which leads to a reduced correlation between the AC score and OCR-based benchmark performance. In Section 6.3, we discuss how the use of the SPair-71k correspondence dataset across all benchmarks fails to adequately capture correspondence in images containing text.
5.5 AC策略的额外结果
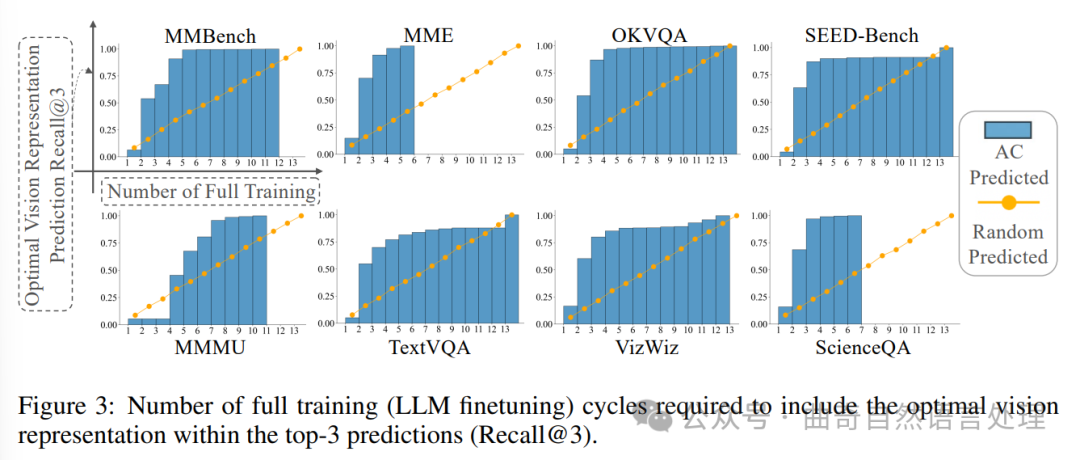
图3:将最佳视觉表示纳入前三名预测(召回率@3)所需的完整训练(LLM微调)循环次数。
在第4部分,作者证明:在有限的搜索空间(本文中为包含13个设置的情况下),使用一致性 AC 分数拟合可以预测使用最少资源获取的最佳视觉表征。在此部分,作者会针对表格中的每个实验,提供可视化数据并解释结果背后的逻辑。通常进行视觉编码器相关试验时,都会随机选取一部分用于训练以节约成本。但是,作者通过在3进行的1000次模拟实验表明,在包括最优视觉表征的情况下,至少需要对11个设置进过训练,这样可以有81.2%的概率获得最优解。这说明使用小部分的视觉表示做训练是行不通的,应该尽可能的利用全部设置进行训练,至少也需要11项以上才能在大部分情况下得到最优结果。
In Section 4, we demonstrate that fitting the AC score consistently predicts the optimal vision representation with minimal resources, given a finite search space—in this case, 13 settings. In this section, we provide detailed visualization for Table 1. When performing ablation experiments on vision encoders, it's common to randomly select a subset to train on. However, as shown in Figure 3, with 1000 runs of simulated ablation experiments, we found that to include the optimal vision representation 81.2% of the time, at least 11 out of the 13 settings need to be trained. This suggests that running a small subset of vision representations is
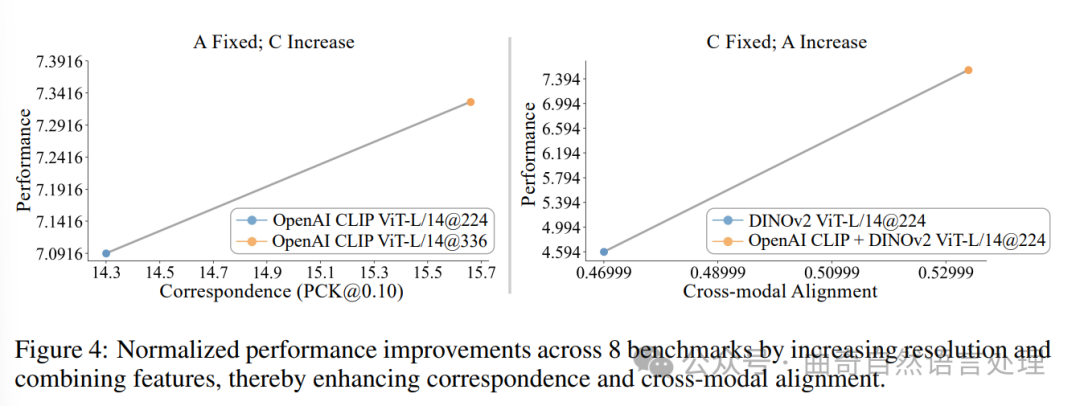
图4:通过增加分辨率和融合特征,提升8个基准的规范化性能改进,在此过程中增强对应和跨模态对齐。
Figure 4: Normalized performance improvements across 8 benchmarks by increasing resolution and combining features, thereby enhancing correspondence and cross-modal alignment.
相比之下,AC策略只需要平均3.88次完整的训练跑就能达到89.69%的召回率@3。
在最成功的预测基准ScienceQA中,该策略在96.6%的情况下成功在前三选项中找到最佳配置,仅通过13个设置搜索空间内的三次语言模型微调运行。这个结果表明,AC策略显著降低了对于多模态语言模型探索视觉表示的劳动和成本。
unreliable, especially as the search space expands, making it increasingly unlikely to identify the true optimal representation by training only a subset.
In contrast, the AC policy requires only 3.88 full training runs on average to reach 89.69% Recall@3.
For the most successful prediction benchmark, ScienceQA, the policy successfully identifies the optimal configuration among the top three choices in 96.6% of cases, with only three language model finetuning runs across a 13-setting search space. This result shows that AC policy significantly reduces the effort and cost of exploring vision representations for MLLMs.
6 Discussion And Limitations
讨论与限制
6.1 Finding Vision Representations With High Ac 高精度视觉表示的寻找
由于AC分数与MLLM基准性能高度相关,为了从视觉角度改进MLLM,识别具有高AC分数的视觉表示并将其纳入搜索空间是至关重要的。作者提出以下两种策略来实现这一目标:提高分辨率和融合特征。
图4展示了八个基准上归一化性能提升的总和。增加具有良好对齐的特性的解析度可直接增强对应关系。例如,将CLIP中的图像分辨率从224像素增加到336像素,在保持跨模态对齐的同时,提高了0.2点(从7.1升至7.3)。
此外,特征组合——通过在通道维度上合并两项高A和C评分的特性——可在保留对应关系的同时增强跨匹配。作者选择沿着通道维度连接特性以保留上下文长度并符合附录A.2中从作者的高度对应注意力证明得出的直觉。具体而言,具有高度对应特性的功能可以支持关注机制中特征检索的信息,在跨模态对齐良好的特征上获取信息。例如,将CLIP与DINOv2结合使用导致跨模态对齐得到改善,从而提升模型性能。
Since AC score is highly correlated with MLLM benchmark performance, to improve MLLM from the vision side, it is essential to identify vision representations with high AC scores and add them into the search space. We suggest two strategies to achieve this: increasing resolution and combining features.
Figure 4 shows the normalized performance improvement summed across eight benchmarks. Increasing the resolution of well-aligned features directly enhances correspondence. For example, increasing the image resolution from 224 to 336 for CLIP, while maintaining cross-modal alignment, resulted in a performance increase from 7.1 to 7.3 out of 8.
Additionally, feature combination—merging two features with high A and C scores along the channel dimension—can enhance cross-alignment while preserving correspondence. We chose to concatenate features along the channel dimension to preserve context length and to align with the intuition from our high correspondence attention proof in Appendix A.2. Specifically, the high correspondence feature can support the retrieval of information in the attention mechanism for the feature with high cross-modal alignment. Combining CLIP with DINOv2, for instance, leads to an increase in cross-modal alignment, thereby improving model performance.
6.2 精化打分设计
6.2 Refining A Score Design
作者设计的A评分计算是CLIP嵌入和目标嵌入每对嵌入向量的最大余弦相似度。然而,如果从CLIP和目标编码器获得的功能在分辨率上有所差异,可能会无意间将对应效果包含进来了。例如,当使用CLIP@224与CLIP@336计算A评分时,并非应当为1,因为作者假设CLIP始终具有A评分为1的假定。这表明,在这种情况下,A评分的计算没有完全分离出对应的效应。最好的做法是始终将相同输入分辨率用于CLIP和目标编码器两个方面上。然而,作者只具备在224和336两种分辨率下的CLIP信息资源,如果目标编码器工作在更高解析度,那么作者就不能得出对齐分数了。为了缓解此问题影响,作者分别用CLIP@224和CLIP@336计算每个目标视觉表示的A评分平均数,目的在于均化对应的影响。
另一个限制是使用CLIP作为参考度量工具这一做法可能会存在问题:如果在搜索空间中存在另一种跨模态对齐更好得嵌入编码器时。然而,作者认为这个错误不应该大到能导致预测最优视图呈现落在前三或者前五之外的范围中。如果有一个与CLIP具有相同对应的视觉呈现却表现出显著更高的MLLM性能,那么建议切换至这种模型作为更精确跨模态对齐参考工具是有利的。
We design the A score calculation as the maximum cosine similarity between each pair of embedding vectors from the CLIP embedding and the target embedding. However, correspondence effects can be unintentionally included if the features obtained from CLIP and the target encoder differ in resolution. For example, the A score computed for CLIP@224 with CLIP@336 is not 1, which it is supposed to be, as our assumption is that CLIP always has an A score of 1. This shows that correspondence is not fully disentangled in the A score calculation in this scenario. The best practice is to always use the same input resolution for both CLIP and the target encoder. However, since we only have CLIP at resolutions 224 and 336, we cannot compute the alignment score if the target encoder operates at a higher resolution. To mitigate this effect, we compute the averaged A score for each target vision representation using both CLIP@224 and CLIP@336, aiming to average out the influence of correspondence.
Another limitation is the use of CLIP as a reference metric. This could be problematic if another encoder with better cross-modal alignment exists in the search space. However, we believe the error should not be significant enough to cause the predicted optimal vision representation to fall outside the top-3 or top-5. If a vision representation with the same correspondence as CLIP yields significantly higher MLLM performance than CLIP, it would be advisable to switch to this model as a more accurate cross-modal alignment reference model.六点三,改进C分设计
6.3 Refining C Score Design
作者注意到,基于OCR的基准性能与AC评分之间的相关性较弱,相比于基于视觉的基准。这种差异的主要原因是用于计算C分数的对应数据集的选择。SPair71k是自然图像特征对应的评估数据集,例如猫和火车等对象。如图5所示,CLIP编码器在自然图像中的对应性较差,而DINOv2较好。然而,在包含文本的图像中,CLIP的对应性显著优于DINOv2及其他任何编码器。因此,使用SPair-71k计算C分数不能准确反映所有情况下的真实对应关系。理想情况下,每个基准测试都应该有自己的带有关键点标注的图像来进行对应性评估。至少针对OCR而言,有一个专门的数据集用于衡量MLLMs在对应关系方面的性能会非常有益。据作者所知,目前并不存在这样的数据集。作者鼓励对此方向进行进一步调查研究,在MLLM领域具有重要意义,尤其是理解表格和图表等基础能力。自然图像中的对应性与包含文本的图像之间的对应性 CLIP DINOv2 CLIP DINOv2 图5:对自然图像和包含文本的图像中CLIP和DINOv2的对比可视化。左侧显示原始图片,右侧显示目标图片。
蓝色圆点标记了最相似的关键点区域,绿色部分表示相对高相似度的区域。

We have noted that OCR-based benchmark performance shows a weaker correlation with the AC score compared to vision-based benchmarks. The primary cause of this discrepancy lies in the correspondence dataset we selected to compute the C score. The SPair71k dataset measures feature correspondence for natural images, such as objects like cats and trains. As shown in Figure 5, the CLIP encoder demonstrates poorer correspondence in natural images compared to DINOv2. However, when it comes to images containing text, CLIP exhibits significantly better correspondence than DINOv2 or any other encoders. Therefore, using SPair-71k to calculate the C score does not accurately capture true correspondence across all scenarios. Ideally, each benchmark should have its own keypoint-labeled images for correspondence evaluation. At a minimum, an OCR-specific correspondence dataset would be highly beneficial for assessing MLLMs. To our knowledge, no such dataset currently exists. We encourage further investigation in this direction, as it would be valuable across fields in MLLM, particularly for understanding tables and charts—a fundamental capability.
Correspondence of Nature Image Correspondence of Image with Text CLIP DINOv2 CLIP DINOv2 Figure 5: Visualization of correspondence on natural images and images containing text for CLIPand DINOv2. The left image shows the source image, while the right one shows the target image.
Blue dots indicate key points with the highest similarity, and the green areas represent regions with relatively high similarity.参考资料
References
Lucas Beyer, Andreas Steiner, Andre Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, ´Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al.
Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726, 2024.
Kaibing Chen, Dong Shen, Hanwen Zhong, Huasong Zhong, Kui Xia, Di Xu, Wei Yuan, Yifei Hu, Bin Wen, Tianke Zhang, et al. Evlm: An efficient vision-language model for visual understanding.
arXiv preprint arXiv:2407.14177, 2024a.
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821, 2024b.
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2818–2829, 2023.
Jiali Duan, Liqun Chen, Son Tran, Jinyu Yang, Yi Xu, Belinda Zeng, and Trishul Chilimbi. Multimodal alignment using representation codebook. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15651–15660, 2022.
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Muller, Harry Saini, Yam ¨Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning,2024.
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394, 2023.
Chunjiang Ge, Sijie Cheng, Ziming Wang, Jiale Yuan, Yuan Gao, Jun Song, Shiji Song, Gao Huang, and Bo Zheng. Convllava: Hierarchical backbones as visual encoder for large multimodal models.
arXiv preprint arXiv:2405.15738, 2024.
Shijie Geng, Jianbo Yuan, Yu Tian, Yuxiao Chen, and Yongfeng Zhang. Hiclip: Contrastive language-image pretraining with hierarchy-aware attention. arXiv preprint arXiv:2303.02995,2023.
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3608–3617, 2018.
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pp. 4904–4916.
PMLR, 2021.
Oguzhan Fatih Kar, Alessio Tonioni, Petra Poklukar, Achin Kulshrestha, Amir Zamir, and Federico ˘Tombari. Brave: Broadening the visual encoding of vision-language models. arXiv preprint arXiv:2404.07204, 2024.
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models.
arXiv preprint arXiv:2402.07865, 2024.
Hyunjik Kim, George Papamakarios, and Andriy Mnih. The lipschitz constant of self-attention. In International Conference on Machine Learning, pp. 5562–5571. PMLR, 2021.
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan.
Seed-bench: Benchmarking multimodal large language models. In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition, pp. 13299–13308, 2024a.
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pretraining for unified vision-language understanding and generation. In International conference on machine learning, pp. 12888–12900. PMLR, 2022.
Yifan Li, Yikai Wang, Yanwei Fu, Dongyu Ru, Zheng Zhang, and Tong He. Unified lexical representation for interpretable visual-language alignment. arXiv preprint arXiv:2407.17827, 2024b. Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pretraining for visual language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26689–26699, 2024.
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ´ Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, 2014.
Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, et al. Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575, 2023.
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Pollefeys. Lightglue: Local feature matching at light speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision,pp. 17627–17638, 2023.
欢迎关注公众号:曲奇自然语言处理

















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









