






一 案例分析
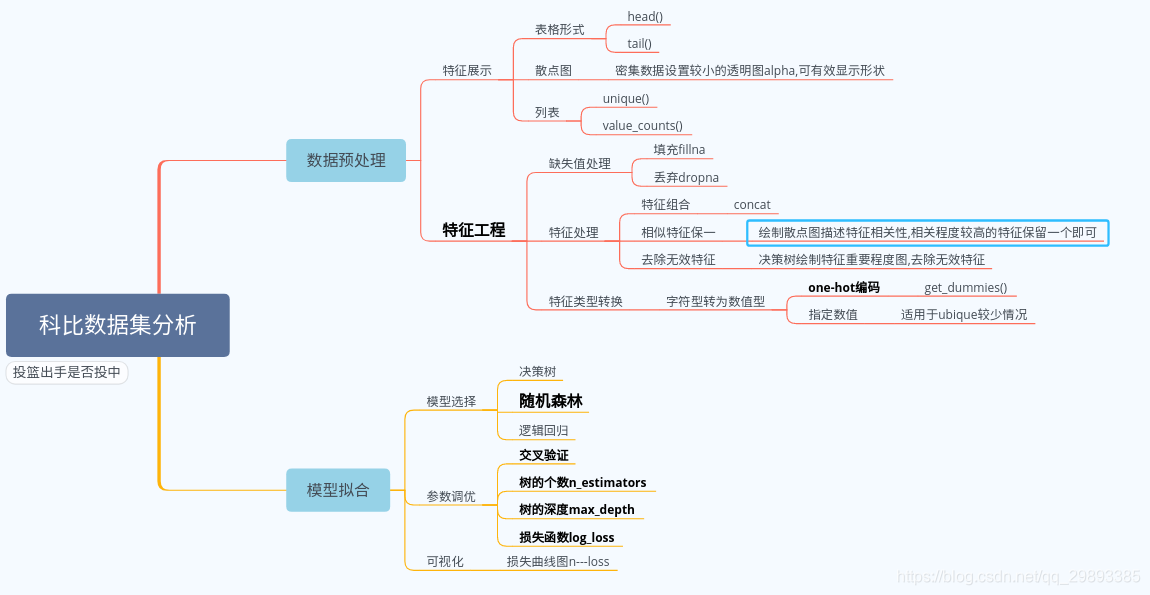
- 在给定科比职业生涯的相关数据,比如投篮命中率、投篮出手次数等特征进行分析,投出一球是否命中。本质上也为二分类问题,此次选用随机森林作为模型训练算法。
数据集及完整代码地址https://github.com/RenDong3/Python_Note
二 特征工程
1 读取数据
- 1.1基本属性 如head()、tail()、shape、columns
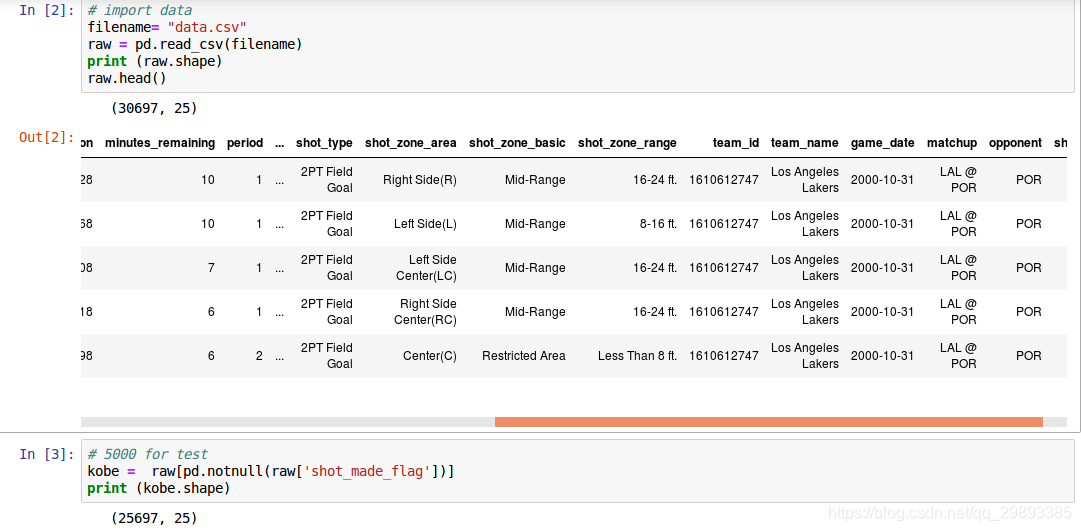
- 1.2特征联系
- loc_x、lox_y表示球场的经纬度 可以理解为位置,所以选用散点图可以看出整体表现为球场形状


2 特征工程
2.1 去除无效特征
- 一般对于ID、time等这些无关紧要的特征可以直接丢弃
- axis的重点在于方向,而不是行和列
- 当axis=1时,数组的变化是横向的,而体现出来的是列的增加或者减少
- 如果是拼接,那么也是左右横向拼接;如果是drop,那么也是横向发生变化,体现为列的减少。

2.2 缺失值处理
- 丢弃dropna()
- 对于缺失数据较多的特征可以选择直接丢弃特征,缺失数据较少的特征可以只丢弃缺失值
- 填充fillna()
- 一般选择特征的未缺失值的均值进行缺失值的填充
2.3 特征组合
- 如这里可以将小时和分钟进行结合作为新的特征

2.4 相似特征保一
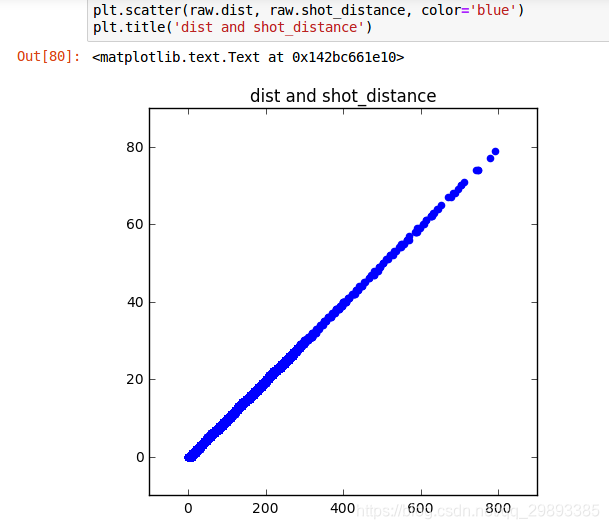
- 绘制散点图描述特征相关性,相关程度较高的特征保留一个即可
- 如本例中dist特征和shot_distance特征具有很高的正相关,属于相似特征
2.5 特征类型转换
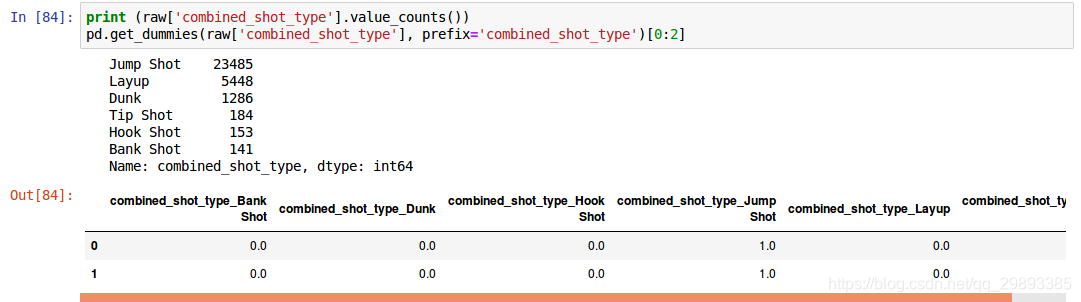
- 字符型转为数值型
- one-hot编码
- 一个长度为n的数组,只有一个元素是1.0,其他元素是0.0。
- 自定义字典调用replace
- 去除特定字符
- 如’ % ‘、’ - '等特殊连接符号
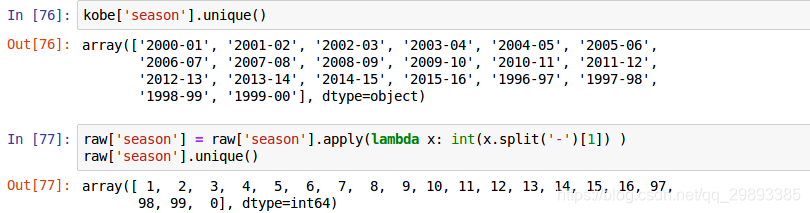
- 如’ % ‘、’ - '等特殊连接符号
三 模型训练
1 随机森林
1.1 原理
- 随机森林由Leo Breiman(2001)提出的一种分类算法,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集合训练决策树,然后按以上步骤生成m棵决策树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于独立抽取的样本。
- 单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样本可以通过每一棵树的分类结果经统计后选择最可能的分类。
1.2 流程
- 从样本集中有放回随机采样选出n个样本
- 从所有特征中随机选择k个特征,对选出的样本利用这些特征建立决策树(一般是CART,也可是别的或混合)
- 重复以上两步m次,即生成m棵决策树,形成随机森林
- 对于新数据,经过每棵树决策,最后投票确认分到哪一类
1.3 优点
- 每棵树都选择部分样本及部分特征,一定程度避免过拟合
- 每棵树随机选择样本并随机选择特征,使得具有很好的抗噪能力,性能稳定
- 能处理很高维度的数据,并且不用做特征选择
- 适合并行计算
- 实现比较简单
1.4 缺点
- 参数较复杂
- 模型训练和预测都比较慢
2 参数调优
2.1 参数详解
对于随机森林存在很多参数,但是用的比较多的一般为下面几个:
- n_estimators:
- 在利用最大投票数或平均值来预测之前,你想要建立子树的数量。 较多的子树可以让模型有更好的性能,但同时让你的代码变慢。 你应该选择尽可能高的值,只要你的处理器能够承受的住,因为这使你的预测更好更稳定。
- max_depth:
- 决策树最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。
- 一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。
- 常用的可以取值10-100之间。
- min_samples_leaf:
- 叶子节点最少样本数,这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
- min_samples_split:
- 内部节点再划分所需最小样本数, 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。
- 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
代码演示
# find the best n_estimators for RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import KFold
print('Finding best n_estimators for RandomForestClassifier...')
min_score = 100000
best_n = 0
scores_n = []
range_n = np.logspace(0,2,num=3).astype(int)
for n in range_n:
print("the number of trees : {0}".format(n))
t1 = time.time()
rfc_score = 0.
rfc = RandomForestClassifier(n_estimators=n)
for train_k, test_k in KFold(len(train_kobe), n_folds=10, shuffle=True):
rfc.fit(train_kobe.iloc[train_k], train_label.iloc[train_k])
#rfc_score += rfc.score(train.iloc[test_k], train_y.iloc[test_k])/10
pred = rfc.predict(train_kobe.iloc[test_k])
rfc_score += log_loss(train_label.iloc[test_k], pred) / 10
scores_n.append(rfc_score)
if rfc_score < min_score:
min_score = rfc_score
best_n = n
t2 = time.time()
print('Done processing {0} trees ({1:.3f}sec)'.format(n, t2-t1))
print(best_n, min_score)
# find best max_depth for RandomForestClassifier
print('Finding best max_depth for RandomForestClassifier...')
min_score = 100000
best_m = 0
scores_m = []
range_m = np.logspace(0,2,num=3).astype(int)
for m in range_m:
print("the max depth : {0}".format(m))
t1 = time.time()
rfc_score = 0.
rfc = RandomForestClassifier(max_depth=m, n_estimators=best_n)
for train_k, test_k in KFold(len(train_kobe), n_folds=10, shuffle=True):
rfc.fit(train_kobe.iloc[train_k], train_label.iloc[train_k])
#rfc_score += rfc.score(train.iloc[test_k], train_y.iloc[test_k])/10
pred = rfc.predict(train_kobe.iloc[test_k])
rfc_score += log_loss(train_label.iloc[test_k], pred) / 10
scores_m.append(rfc_score)
if rfc_score < min_score:
min_score = rfc_score
best_m = m
t2 = time.time()
print('Done processing {0} trees ({1:.3f}sec)'.format(m, t2-t1))
print(best_m, min_score)
结果:

四 总结


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









