







#https://baijiahao.baidu.com/s?id=1673295674426968644&wfr=spider&for=pc
构建深度学习模型的基本流程就是:搭建计算图,求得损失函数,然后计算损失函数对模型参数的导数,再利用梯度下降法等方法来更新参数。搭建计算图的过程,称为“正向传播”,这个是需要我们自己动手的,因为我们需要设计我们模型的结构。由损失函数求导的过程,称为“反向传播”,
初识求导
import torch
x = torch.tensor(4.0,requires_grad=True)
x.requires_grad_(True)
y = torch.pow(x,2)
y.backward()
x.grad
tensor的创建与属性设置
tensor(data, dtype=None, device=None, requires_grad=False) -> Tensor
在tensor创建方法中有个requires_grad参数,这是表示tensor是否开启求导选项.默认是关闭的,这个参数是可以传递的例如:
import torch
x = torch.tensor([2.4,4.2],requires_grad=True)
y = torch.pow(x,2)
y.requires_grad
上面结果输出为True,当然也可以通过requires_grad_()方法设置
import torch
x =torch.arange(4.0)
print(x.requires_grad)
x.requires_grad_(True)
print(x.requires_grad)
backwrad函数详解
backward(gradient=None, retain_graph=None, create_graph=False)
规则
在pytorch里面,默认:只能是【标量】对【标量】,或者【标量】对[向量/矩阵】求导。标量可以理解为数字,向量和矩阵理解为多维数组,
上面的例子都是标量对标量求导,下来在举一个标量对向量求导。
import torch
X = torch.randn(4)
W = torch.normal(0,0.01,(4,1)).reshape(4)
W.requires_grad_(True)
y = torch.dot(X,W)
y.backward()
W.grad
上面做了一个y=X*W的计算,其中X和W都是一个向量
如果我们需要向量对向量求导,那该怎么办呢?
向量对向量求导–gradient
这是就需要使用backward参数gradient了。
X = torch.arange(4.0)
X.requires_grad_(True)
y = X *X
y.backward(torch.ones_like(y))
X.grad
需要注意的是,gradient的维度是和最终的需要求导的那个y的维度是一样的,
保留运算图——retain_graph
下面是一张计算图
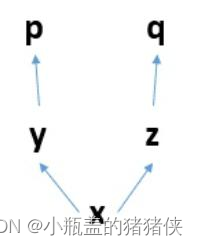
一个计算图在进行反向求导之后,为了节省内存,这个计算图就销毁了。 如果你想再次求导,就会报错
x = torch.arange(4.0)
x.requires_grad_(True)
y = 2 * x
p = torch.pow(y,2).sum()
p.backward()
p.backward()
上面第二次执行的p.backward()就会报错,当在第一个p.backward()中加retain_graph=True就不会报错,表示在执行backwark之后不会删除计算图















 3247
3247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









