







 本文详细介绍了如何使用Flexibile-Yolov5框架来替换YoloV5的默认DarkNet主干网络,包括理解YoloV5结构、环境配置、数据集准备、修改网络配置文件、训练模型和部署检测。重点讲解了如何设计和调整模型的yaml及py文件,以实现特征金字塔结构,并提供了具体的代码示例。
本文详细介绍了如何使用Flexibile-Yolov5框架来替换YoloV5的默认DarkNet主干网络,包括理解YoloV5结构、环境配置、数据集准备、修改网络配置文件、训练模型和部署检测。重点讲解了如何设计和调整模型的yaml及py文件,以实现特征金字塔结构,并提供了具体的代码示例。
Flexible-Yolov5:可自定义主干网络的YoloV5工程实践
本文目录:
- 概述
- 理论学习与环境配置
- 准备自己的数据集
- 修改或调整自定义的主干网络
- 部署训练
一、概述
YoloV5的主干网络是优秀的,但是许多时候默认的DarkNet并不能满足我们的需求,包括科研、立项时需要更多的创新性。而Yolo框架出色的集成了许多目标检测相关的功能与输出,很容易让人联想到在Yolo框架下替换掉DarkNet来测试自己的网络性能水平。
本文是一篇经验帖,主要描述如何使用Github的开源项目flexible-yolov5(以下简称FY5)来达到我们替换YoloV5的主干网络的目的,虽然YoloV5官方也可以修改主干网络,但由于集成度较高,对替换操作有较大的阻力,因此选用该项目进行替换。授人以鱼不如授人以渔,在本文中我尽量以分析的视角来描述如何掌握整个FY5项目。
说两句题外话: Yolo只不过是目标检测的入门框架,可轻松上手,请不要在未持有深度学习设备、拥有相关导师的情况下因为Yolo轻易选择入行深度学习的计算机视觉领域,在目前该领域内卷爆炸的时代浪费自己的青春。
二、理论学习与环境配置
在进行实际操作前,我们先阅读Yolo中主干网络结构,主干网络是将图片的输入进行特征提取的神经网络,一般情况下我们也只需要对主干网络进行修改,即下图中从张量大小为608* 608* 3的输入图片到最右侧变成3个蓝色的张量的过程,在主干网络将图片变换为3幅特征图后,主干网络的任务就完成了,最后生成的3幅特征图共同组成了“三层特征金字塔结构”。
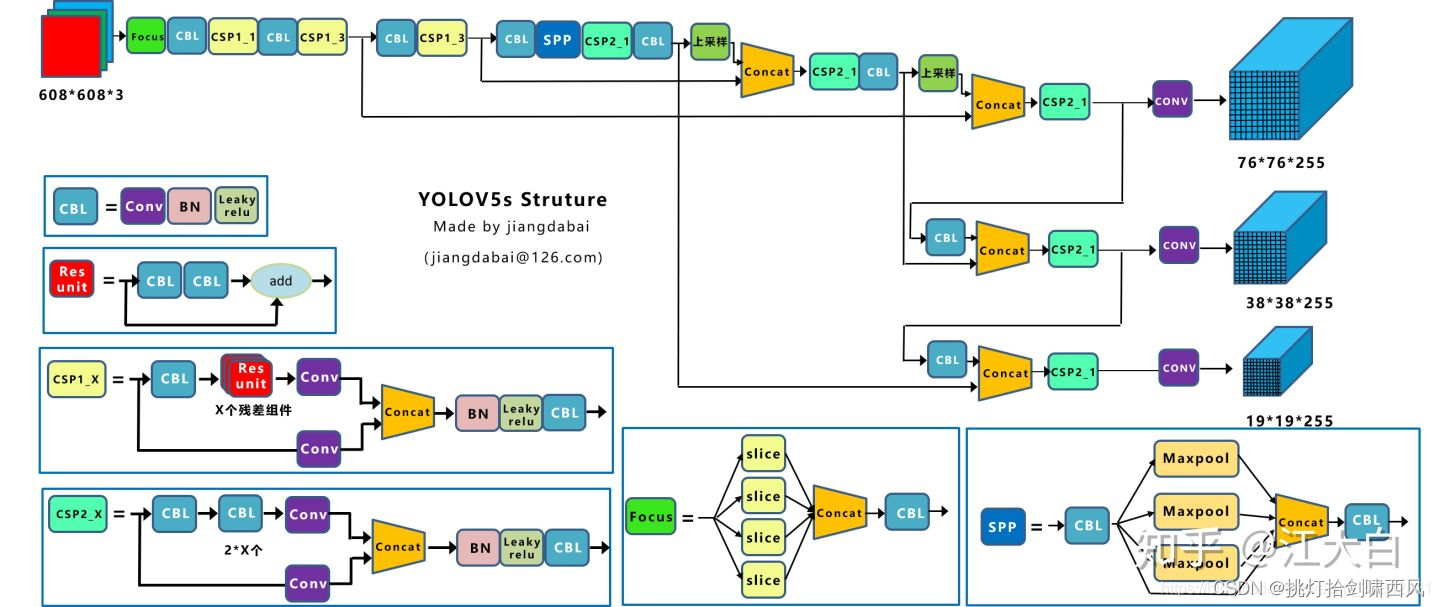
因此,我们的主干网络只要能够将输入的图片转化为3个蓝色的向量,交给目标检测任务的其他部分(实际上也可以对这部分进行修改,以提高检测速度或精度,但本文不再陈述),就可以了。
接下来我们从Github下载FY5的代码(GitHub链接),其目录结构如下图所示。
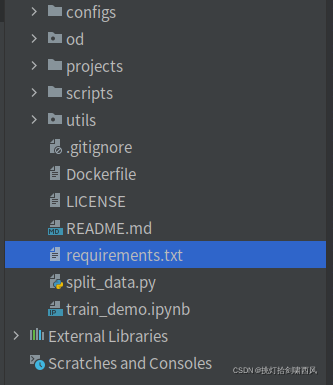
各个目录结构的作用:
- configs:存储数据集与主干网络的Yaml文件(配置文件)
- od:存储模型的结构文件(基于Pytorch框架的py脚本)与数据集的一些处理操作
- projects:项目部署相关的一些py脚本,笔者没有使用过
- scripts:训练模型、模型检测的一些py脚本
- utils:可视化等相关工具
配置环境:直接使用Pip工具利用目录下的requiements.txt配置即可,值得一提的是,使用requirements.txt部署环境时请尽量使用Linux系统,Windows系统的某些Python依赖缺失,需要编译安装比较麻烦。
三、准备自己的数据集
数据集的准备工作网络上的教程已经很多了,这里只简单说明一下FY5要求的数据集格式。实际上FY5与Yolov5官方的数据集要求相同,都是Txt格式的Bbox标签、Yaml格式的数据集配置文件要求(该部分可查阅网络相关资料),可以直接将Yolov5项目上配置的数据集迁移过来,准备数据集的主要思路是:下载数据集->找到标签配置文件(一般是Json文件)->转换标签内容为Bbox的txt格式标签->创建并配置相关Yaml文件->在FY5项目的Script目录的train.py中如下图所示配置Yaml文件(下文会再次介绍)。
四、修改或调整自定义的主干网络
接下来的网络配置是最为关键的一步(毕竟这么多的准备也只是为了这一步),先介绍思路:
- 设计、调整模型的yaml文件
- 准备py格式的网络文件(可以是自己设计的,也可以是从复现、从网络上找的)
- 将网络文件进行修改,使得网络头、尾与Yolov5的结构相匹配
- 设计、调整超参数的yaml文件
根据前文学习的Yolov5的结构知识,现在我们以Resnet为例,阅读源码的结构与思路。
1.模型的yaml文件
Yaml文件是模型的配置文件,简单来说:框架在运行时根据Yaml文件(与Yolov5官方的yaml文件类似)来生成相应的模型Class,是一个类似于Json的解析文件,只是为了在调整网络结构的时候方便开发者而已,ResNet的yaml文件可以在“\configs”目录中找到,下面是默认的yaml文件以及相关注释:
backbone: #主干网络的部分,我们也只需要对这部分进行调整
type: resnet #网络类型为resnet,在构建模型的时候会解析出来,即"od/models/backbone/__init__.py"中解析
#下面的都是模型的相关参数
version: 18 # 18, 34, 50, 101, 152 #这里的version实际上是Resnet的深度,
#我们自定义的网络如果需要大量调整的话可以修改相关代码让这个参数起作用,如果只是简单运行一下则不需要,下面的同上
dcn: False #是否启用参数共享机制
cbam: False #是否启用cbam注意力机制
head: #head结构是网络头,起到分类器的作用
nc: 1 #num_class的缩写,取决于你的目标检测任务所需要的分类的类别
stride: [8.0, 16.0, 32.0] #网络头的步长,一般不用做修改
anchors: #Yolov5是自适应的锚定框,这个参数一般也不用修改
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
yaml文件需要在后续的train.py中调用。
2.模型的py文件
还是以resnet为例,我们从"od/models/backbone/resnet.py"中构造resnet的函数看起:
def resnet(pretrained=False, **kwargs):
version = str(kwargs.pop('version')) #解析模型的版本
if version == '18': #判断网络版本
return resnet18(pretrained, **kwargs) #pretrained是是否启用预训练权重进行迁移学习的布尔代数
if version == '34':
return resnet34(pretrained, **kwargs)
if version == '50':
return resnet50(pretrained, **kwargs)
if version == '101':
return resnet101(pretrained, **kwargs)
if version == '152':
return resnet152(pretrained, **kwargs)
不难看出,构造不同的resnet实际上也只有两个关键的区别:
- 不同的构造函数
- 不同的kwargs
以resnet18为例,我们继续进入分析:
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Resnet(BasicBlock, [2, 2, 2, 2], **kwargs) #构造resnet
if pretrained: #调用预训练权重
model.load_state_dict(model_zoo.load_url(model_urls['resnet18'], model_dir='.'), strict=False)
return model
终于要对模型的结构动刀子了,如果有相关经验的朋友肯定已经发现了flexible-yolov5使用的resnet几乎就是官方的resnet,甚至目前为止都没有出现任何区别,接下来的地方就是前文理论学习中讲到的“三层特征金字塔结构”所需要修改的地方了。
接下来我们定位到resnet的构造函数部分,对构造函数进行分析。
class Resnet(nn.Module):#注意:无关代码略有删减!
def __init__(self, block, layers, cbam=False, dcn=False):
super(Resnet, self).__init__()
self.inplanes = 64 #输入的通道数
self.dcn = dcn #是否启用dcn,该项由yaml文件中的同名项解析而来
self.cbam = cbam#是否启用cbam,该项由yaml文件中的同名项解析而来
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) #resnet的proj结构
self.bn1 = nn.BatchNorm2d(64) #防止过拟合的BN
self.relu = nn.ReLU(inplace=True) #relu激活函数
self.out_channels = [] #输出通道数(此项是我们要替换的网络也需要具备的),后面的三层特征金字塔结构会用到
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)#最大池化层
self.layer1 = self._make_layer(block, 64, layers[0])#通过make.layer函数构造一层网络(这里的层其实我更愿意看做一个stage)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, cbam=self.cbam, dcn=dcn)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, cbam=self.cbam, dcn=dcn)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, cbam=self.cbam, dcn=dcn) #第四层网络选择是否启用cbam
self.out_shape = {'C3_size': self.out_channels[0] * 2,
'C4_size': self.out_channels[1] * 2,
'C5_size': self.out_channels[2] * 2} #需要通过make_layer函数中设定的通道数来计算
print("backbone output channel: C3 {}, C4 {}, C5 {}".format(self.out_channels[0] * 2, self.out_channels[1] * 2,
self.out_channels[2] * 2))
def _make_layer(self, block, planes, blocks, stride=1, cbam=False, dcn=None): #make layer函数是构建网络层的函数
downsample = None #下采样,不用管
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
) #是构建下采样层,我们要替换的网络里不一定需要
layers = [block(self.inplanes, planes, stride, downsample, cbam=cbam, dcn=dcn)] #构建网络层,这个想必都不用我说了
self.inplanes = planes * block.expansion
self.out_channels.append(self.inplanes) #将输入通道数添加到前面的out_channels列表里,这一步很重要!我们替换的网络也要有这样一个列表,也要将通道数添加到该列表里,后面的forward方法会用到!
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, cbam=cbam, dcn=dcn)) #将每层网络以此添加到layers数组
return nn.Sequential(*layers)
def forward(self, inputs):#forward方法是最关键的一步了,如果您这一步明白了,那么结合特征金字塔的理论图,就全部都明白了
x = self.conv1(inputs)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x) #获得从第一个网络层的输出
x2 = self.layer2(x1) # 80,80 #保存第二个网络层的输出
x3 = self.layer3(x2) # 40,40 #保存第三个网络层的输出
x4 = self.layer4(x3) # 20,20 ##保存第四个网络层的输出
return x2, x3, x4 #注意:此处是将三个网络层的输出一起返回!!!
看到了forward方法的return,您一定就明白了resnet中实现特征金字塔的方式,那就是将不同的网络层的输出分别保存下来,再分别返回,依照这样的方式,我们自己要替换的网络也可以轻而易举地完成到特征金字塔模型的转换。
那么您一定会好奇,返回了3个平行的张量去了哪里呢?随后我们继续阅读"od/models/model.py"的Model类,定位到forward方法,立刻就真相大白了。
def forward(self, x):
out = self.backbone(x) #这里的backbone就是我们前面陈述的resnet,相应的out就是前面的3个平行输出,关于该类的定义以及部件请详见Model类的构造函数
out = self.fpn(out) #可与理论学习的Yolov5图结合理解
out = self.pan(out) #可与理论学习的Yolov5图结合理解
y = self.detection(list(out))
return y
Model类是FY5项目中的模型类,用于完成整个目标检测任务,即提取特征+分类+检测,我们都知道Yolov5是使用滑动窗口进行目标检测的,我们的主干网络将特征提取出来,直接丢给fpn进行后续处理就可以了,完全不许要再进行任何操作。我们的主干网络实际上在代码中只对应backbone部分,也只完成特征提取的操作。只要我们已经有了模型的py文件,将其略作修改,将模型输出按照特征金字塔的结构返回给Fpn,我们就不需要在进行其他操作即可借助Yolov5的框架完成目标检测任务了。
在添加模型的py文件后,我们还需要在"od/models/backbone/init.py"中添加网络引用,如下面的代码与注释所解释的一样。
# -*- coding: utf-8 -*-
from .resnet import resnet #与resnet一样,我们需要在od/models/backbone/目录下添加我们的py模型文件
from .testnet import testnet #是左侧的格式
__all__ = ['build_backbone'] #这个不用修改
support_backbone = ['resnet', 'shufflenetv2', 'mobilenetv3', 'YOLOv5', 'efficientnet', 'hrnet', 'swin', 'vgg',
'repvgg' ,'testnet'] #在这个字典里添加我们的网络名称
def build_backbone(backbone_name, **kwargs):#下面的函数不用修改,该函数会自动根据yaml文件生成kwargs(传递构造网络参数的字典)
assert backbone_name in support_backbone, f'all support backbone is {support_backbone}'
backbone = eval(backbone_name)(**kwargs)
return backbone
综上所述,我们重新一下修改BackBone的几个要点:
- 设定模型的Yaml文件
- 添加模型的py脚本文件(要点在于forward方法需要调整,以满足三层特征金字塔结构),这一步需要对网络计算的张量大小有较好的理解
- 将模型信息添加到__init.py__文件中
- 使用train.py时调用模型的Yaml文件即可进行训练
此外,训练的超参数与官方的Yolov5使用方法基本相同,直接在"configs/hyp.scratch.yaml"中修改,在train.py中调用即可
# Hyperparameters for COCO training from scratch
# python train.py --batch 40 --cfg yolov5m.yaml --weights '' --data coco.yaml --img 640 --epochs 300
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
lr0: 0.001 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.957 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
五、部署训练
模型的训练使用"scripts/train.py"脚本即可。FY5的训练模型方法同Yolov5官方一样,都支持命令行,但是我个人习惯使用运行代码的方式。
我们定位到train.py的main部分,如下所示:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='', help='initial weights path') #是否有权重继续训练,这个应当是Yolov5训练出来的权重
parser.add_argument('--cfg', type=str,
default='',
help='model.yaml path') #模型的yaml文件
parser.add_argument('--data', type=str, default='',
help='data.yaml path')#数据集的Yaml文件
parser.add_argument('--hyp', type=str, default='',
help='hyperparameters path')#超参数的Yaml文件
parser.add_argument('--epochs', type=int, default=250)#训练Epoch的Yaml文件
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs') #batch_size
parser.add_argument('--img-size', nargs='+', type=int, default=[800, 800], help='[train, test] image sizes') #对数据集进行预处理后的图像大小
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='2', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') #设定训练的GPU设备
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', default=True, action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')
parser.add_argument('--log-artifacts', action='store_true', help='log artifacts, i.e. final trained model')
parser.add_argument('--workers', type=int, default=4, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
opt = parser.parse_args()
#注:以下代码略,不需要修改
设定好了以上参数后,我们就可以开始训练了!控制台的输出、模型的保存方式等都与YoloV5官方一致。训练完成后,在"scripts/runs/train"中,如下图所示我们能够得到一批pt格式的模型权重与部分训练可视化结果:
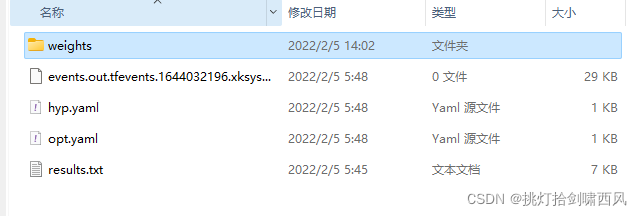
打开weights文件夹,就是我们训练得到的权重文件(last是最后一轮,best是表现最好的一轮):

到此,我们的训练就大功告成了!
训练完成后,我们可以使用"scripts/detector.py"来调用模型进行检测,我们定位到该py文件的main处:
if __name__ == '__main__':
pt_path = 'last.pt'#pt文件的路径
#mes_file = 'names.txt' #检测类别的txt文件,单独存放,用于模型检测完成后加上在矩形框加上文字说明,官方代码不包含此模块
model = Detector(pt_path, mes_file, 800, xcycwh=False) #通过Pt文件搭建的模型,其中变量以官方代码为准
imgs_root = 'scripts/detect_1'#待检测的图片文件夹
save_dir = '/scripts/detect_out' #保存检测成功的图片文件夹
#注:以下代码略,无需修改
imgs_root目录直接放图片即可:

以上的准备工作完成后,我们直接运行detector.py进行检测,检测结果输出在代码中的save_dir中:


至此,FY5的使用介绍完成!
感谢Flexible-yolov5的开发者yl305237731

















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









