







论文总结系自用,有疑问可评论互相交流。
Efficient Estimation of Word Representations in Vector Space
0. Summary
作为word2vec的开篇之作,可以说是开创了NLP的一个新的时代。就像作者最后在conclusion中说的,以后所有的NLP任务都离不开词向量了。不过本文没有深入到深入到CBOW和Skip-gram算法的细节中去,主要目的还是将这种方法与传统NNLM方法做对比。
1. Research Objective
作者说:本文的主要目标就是介绍可以从大型数据集中学习高质量的词向量的各种技术;以及如何评价词向量质量的技术。
2. Problem Statement
本文提出了两个新的训练词向量的模型——Skip-Gram和CBOW。但是大量的篇幅用在评价词向量质量上,尤其是对应用在语义-词法任务上的分析。下面一节,我将介绍,当你身处2013年,如何对提出的一个当前可用的词向量训练模型进行令人信服的评价。而本节下面的内容简短的介绍我们手中的训练词向量的模型工具以及他们中出现的问题。
- NNLM(前向神经网络语言模型)
Q = N × D + N × D × H + H × V Q=N \times D+N \times D \times H+H \times V Q=N×D+N×D×H+H×V - RNNLM(循环神经网络语言模型)
Q = H × H + H × V Q=H \times H+H \times V Q=H×H+H×V - DistBelief(并行训练神经网络)
问题:复杂度较高,在使用大量训练数据集和训练高维词向量上基本不可能。(注:主要还是最后的输出层softmax计算较为复杂,最后从隐藏层映射到V(词汇表概率分布)上,动辄上百万大小的词汇表,每次反向传播都是巨大的消耗)
3. Method(s)*
作者首先对NNLM和RNNLM进行了改进,使其可以运用在大数据集上成为可能。
改进方法:将softmax输出的概率分布使用huffman树改造成分层softmax。这里po一个分层softmax的优质博文链接,很重要,后面很多词向量算法都需要其进行加速。需要说明的是,到目前为止,所有用到的技术,包括分成softmax都是之前有人提出并且用过的。
提出新模型
- Continuous Bag-of-Words(CBOW)
Q = N × D + D × log 2 ( V ) Q=N \times D+D \times \log _{2}(V) Q=N×D+D×log2(V) - Continuous Skip-gram(SG)
Q = C × ( D + D × log 2 ( V ) ) Q=C \times\left(D+D \times \log _{2}(V)\right) Q=C×(D+D×log2(V))

改进点:从给出的复杂度公式也能看出,比NNLM少了个隐藏层,作者这里利用了一个绝妙的思想“You shall know a word by the company it keeps”,因此就能通过最大化上下文单词和中心词的条件概率来学习权重矩阵,即我们的词向量。
4. Evaluation(s)**
讲实话,这篇论文对两种新模型的介绍比较少,仅仅是分析了训练的复杂度,其实这也是为Evaluation做准备。我在这里直接总结下作者用的几种评估技术,虽然是2013年的,但是应该也有一定的借鉴作用。
训练模型的变量:语料规模的大小和词向量维度
- 作者自己搞的一个semantic-syntactic测试集,比较严苛,测试5个语义任务和9个词法任务。只有一个正确答案,错了就是错了(CBOW)

- 测试语料规模和维度对S-S任务准确率的影响(CBOW)
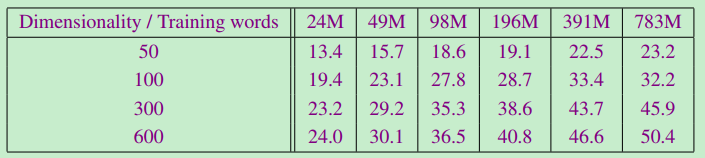
- 不同模型之间的比较(640维词向量)
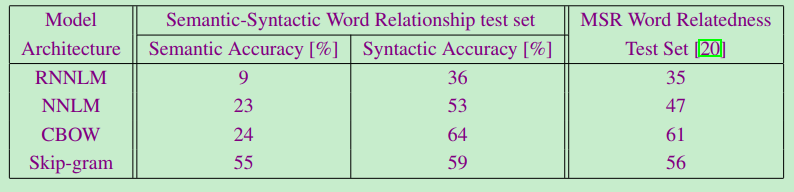
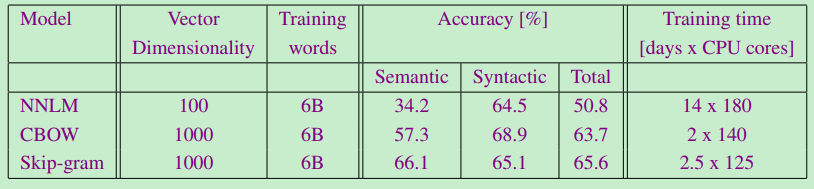
- 所有可收集到的模型对比

- 时间对比

- 其他对比。(使用DistBelief分布式框架)
- 其他对比。(在Microsoft Sentence Completion Challenge)

- 最最重磅的一个测试
通过简单的向量加减计算寻找词之间的关系。

5. Conclusion
- CBOW和Skip-gram取得了较低的训练复杂度结果,使用DistBelief分布式框架更是可以训练上万亿词的语料。
- 获得了相对较高质量的词向量。
- 可以对NLP其他任务都有相应的提升。
- NLP应用的基石。
Notes(optional)
不符合此框架,但需要额外记录的笔记。
Reference(optional)
列出相关性高的文献,以便之后可以继续track下去。















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









