









Stable Diffusion WebUI 的强大之处在于其丰富的插件生态,这些插件可以大幅提升 AI 绘画的效率和质量。本文将详细介绍 21 个常用插件,包括它们的功能、效果说明以及下载地址,帮助你更好地使用 Stable Diffusion WebUI。
插件的安装方式
1、直接下载插件包,存放安装
下载 SD-插件-extensions.zip,解压后,将各个插件文件夹直接拷贝到stable-diffusion-webui/extensions文件夹
配套的sd安装包 为 stable-diffusion-webui_mac.zip,原则上window也能使用,不过window更推荐用网上的exe整合包。
2、链接安装:通过git地址安装
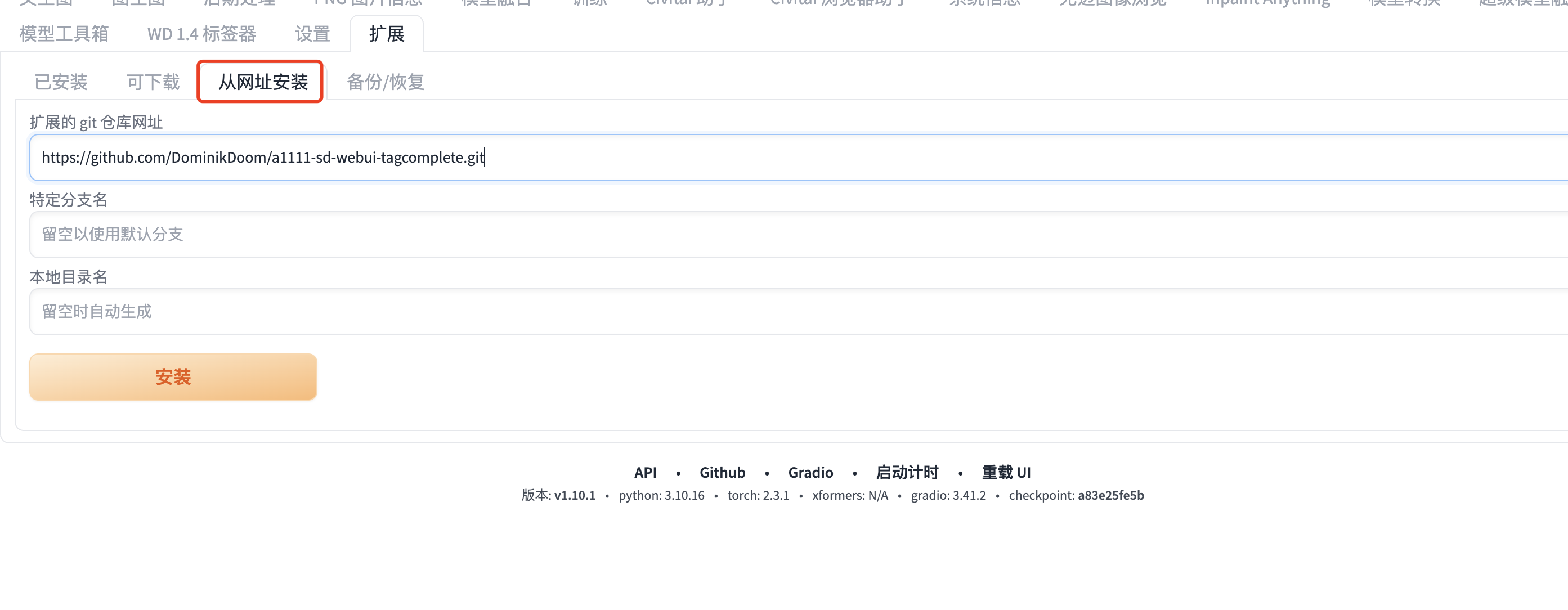
3、搜索安装:部分搜不到,需要根据链接安装
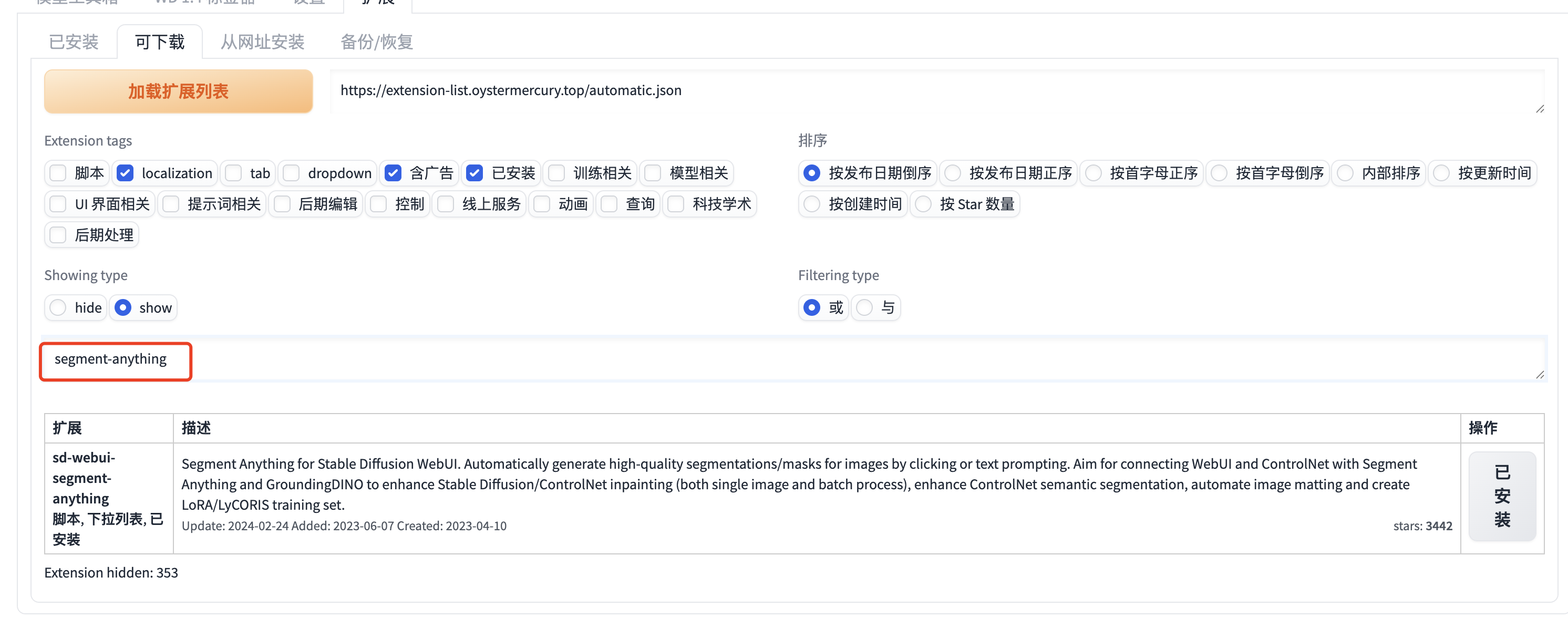
2和3的安装如果超时,需要用到梯子
安装后重启:
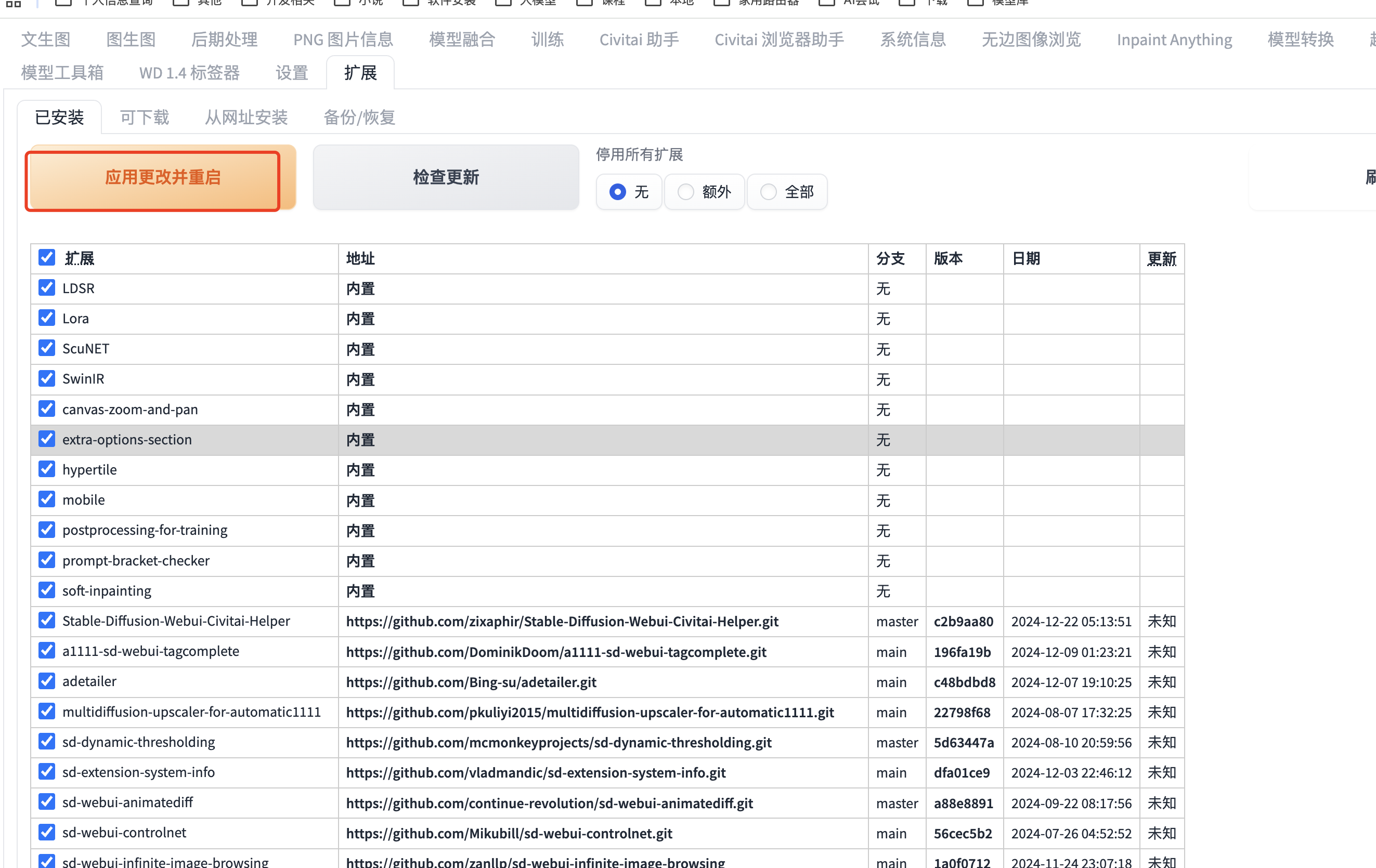
如果遇到安装后不显示,可以删除插件后换种方式安装。
少部分插件存在冲突,只能安装一种。
1. Stable-Diffusion-Webui-Civitai-Helper
功能:方便在 WebUI 中与 Civitai 资源平台交互,快速浏览、下载 Civitai 上的模型、LoRA 等资源。
效果:在 WebUI 界面中增加便捷获取资源的入口,支持一键下载和更新模型。
下载地址:
https://github.com/zixaphir/Stable-Diffusion-Webui-Civitai-Helper
2. a1111-sd-webui-tagcomplete
功能:实现标签自动补全功能,输入提示词时智能推荐相关标签。
效果:输入 cat 时,会提示 black cat、cute cat 等,提高输入效率。
下载地址:
https://github.com/DominikDoom/A1111-sd-webui-tagcomplete
3. adetailer (After Detailer)
功能:专门针对人脸进行修复的插件,可解决生成全身图时人物面部扭曲、模糊问题 。自带多种修复模型,如 face_yolov8n.pt 、face_yolov8s.pt 针对 2D / 写实风脸部修复 。
效果:原本模糊的人脸变得清晰自然,支持 2D/写实风格修复。
下载地址:
https://github.com/Bing-su/adetailer
4. multidiffusion-upscaler-for-automatic1111
功能:用于图像放大,采用多扩散算法,能在相对低显存下对图像进行高清放大,提升图像分辨率 。
效果:放大后的图像细节更清晰,画面更锐利。
下载地址:
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
5. sd-dynamic-thresholding
功能:动态调整 CFG Scale 阈值,优化图像生成细节。
效果:减少过曝或色彩失真,使图像更稳定。
下载地址:
https://github.com/mcmonkeyprojects/sd-dynamic-thresholding
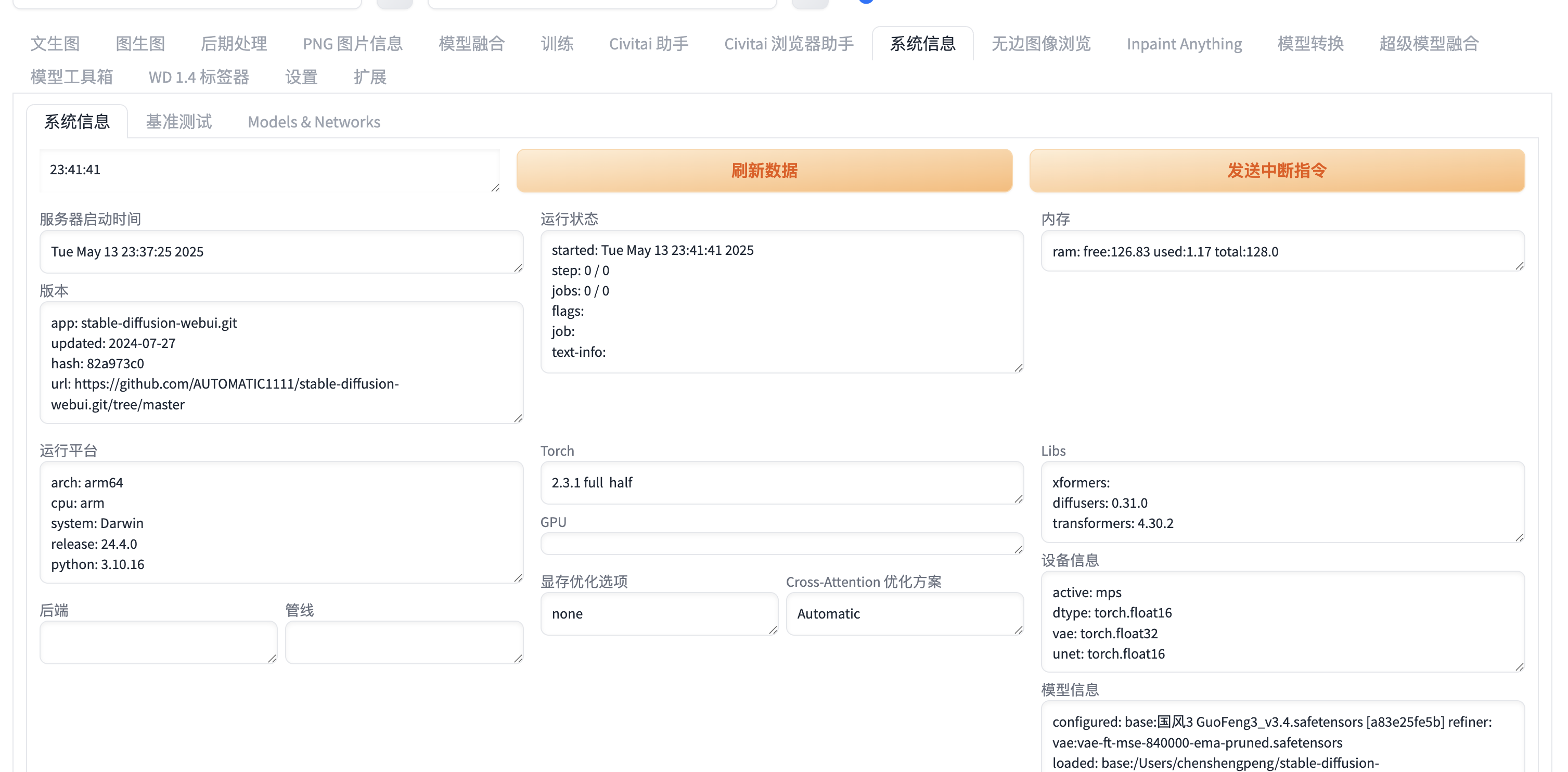
6. sd-extension-system-info
功能:显示系统信息(显存、CPU 负载等),方便排查性能问题。
效果:在 WebUI 界面显示实时资源占用情况。
下载地址:
https://github.com/vladmandic/sd-extension-system-info
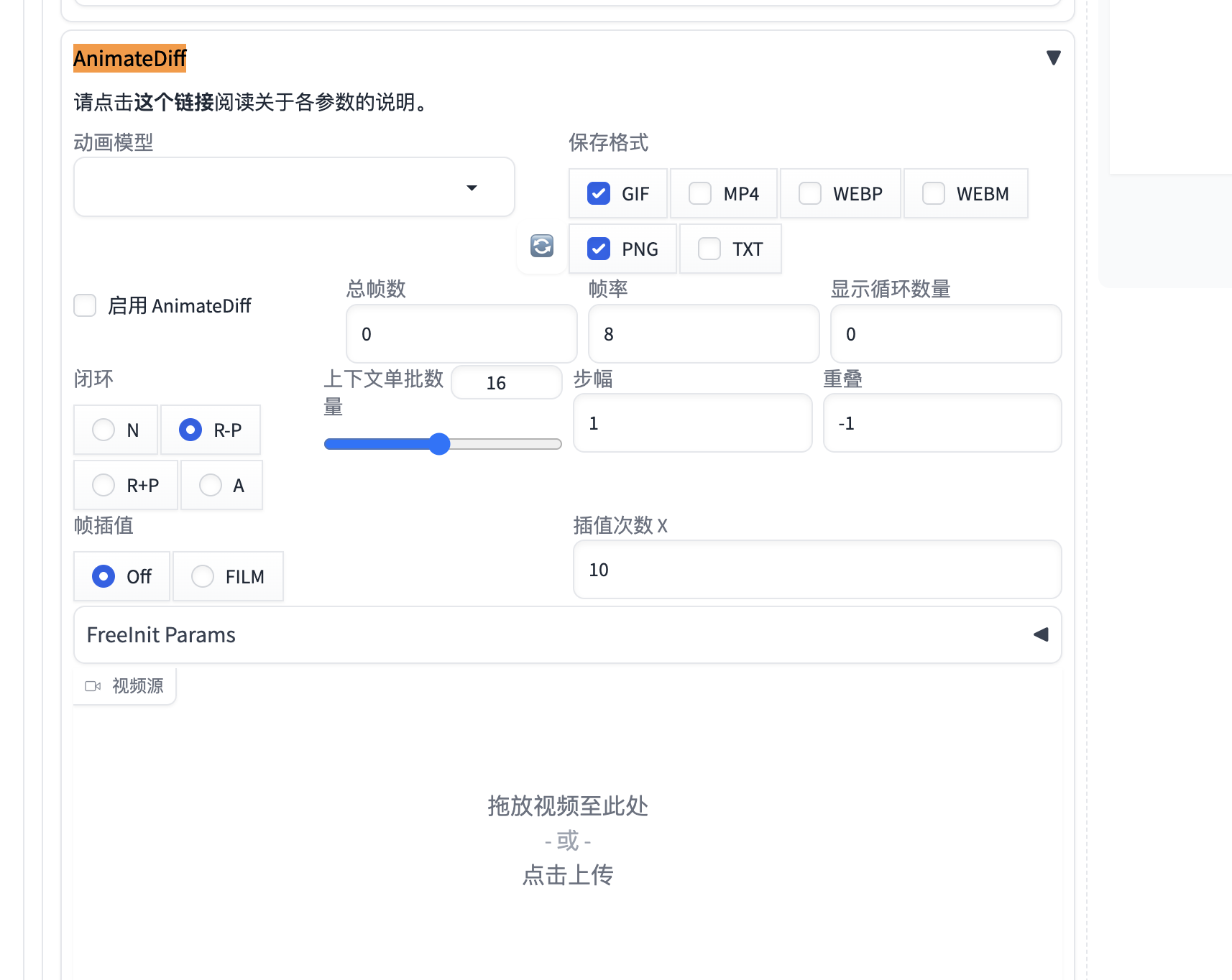
7. sd-webui-animatediff
功能:将静态图像转换为动画(GIF/视频)。
效果:生成角色眨眼、镜头移动等简单动画。
下载地址:
https://github.com/continue-revolution/sd-webui-animatediff
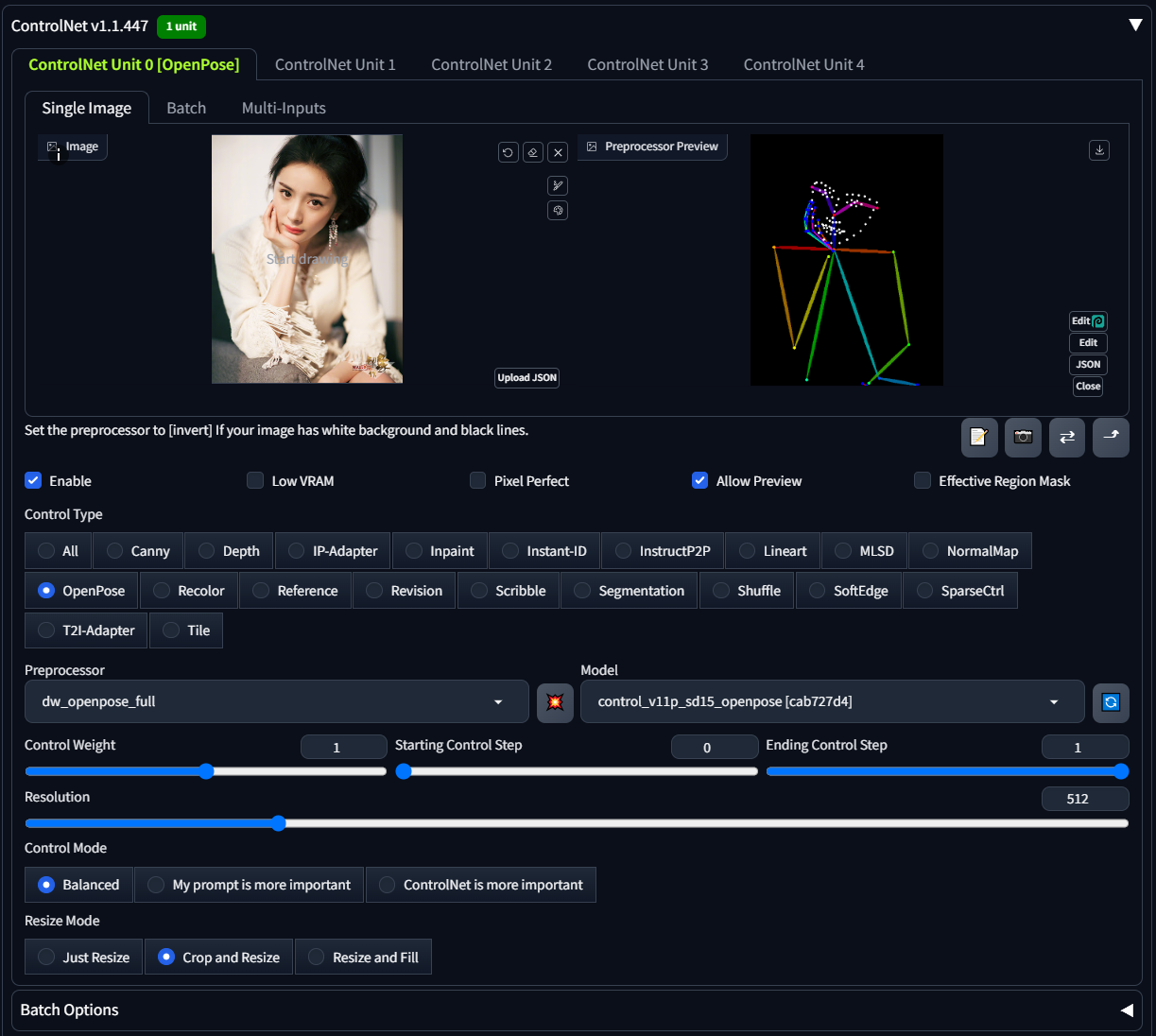
8. sd-webui-controlnet
功能:通过骨骼图、深度图等控制生成图像的姿势和构图。
效果:精准复现人物姿势、建筑结构等。
下载地址:
https://github.com/Mikubill/sd-webui-controlnet
9. sd-webui-infinite-image-browsing
功能:高效管理 AI 生成的图像,支持标签搜索、批量操作。
效果:类似本地版“Pinterest”,方便整理作品。
下载地址:
https://github.com/zanllp/sd-webui-infinite-image-browsing
10. sd-webui-inpaint-anything
功能:结合 Meta 的 Segment Anything 模型,精准替换/修复图像内容。
效果:可用于去水印、换装、修改场景元素。
下载地址:
https://github.com/Uminosachi/sd-webui-inpaint-anything
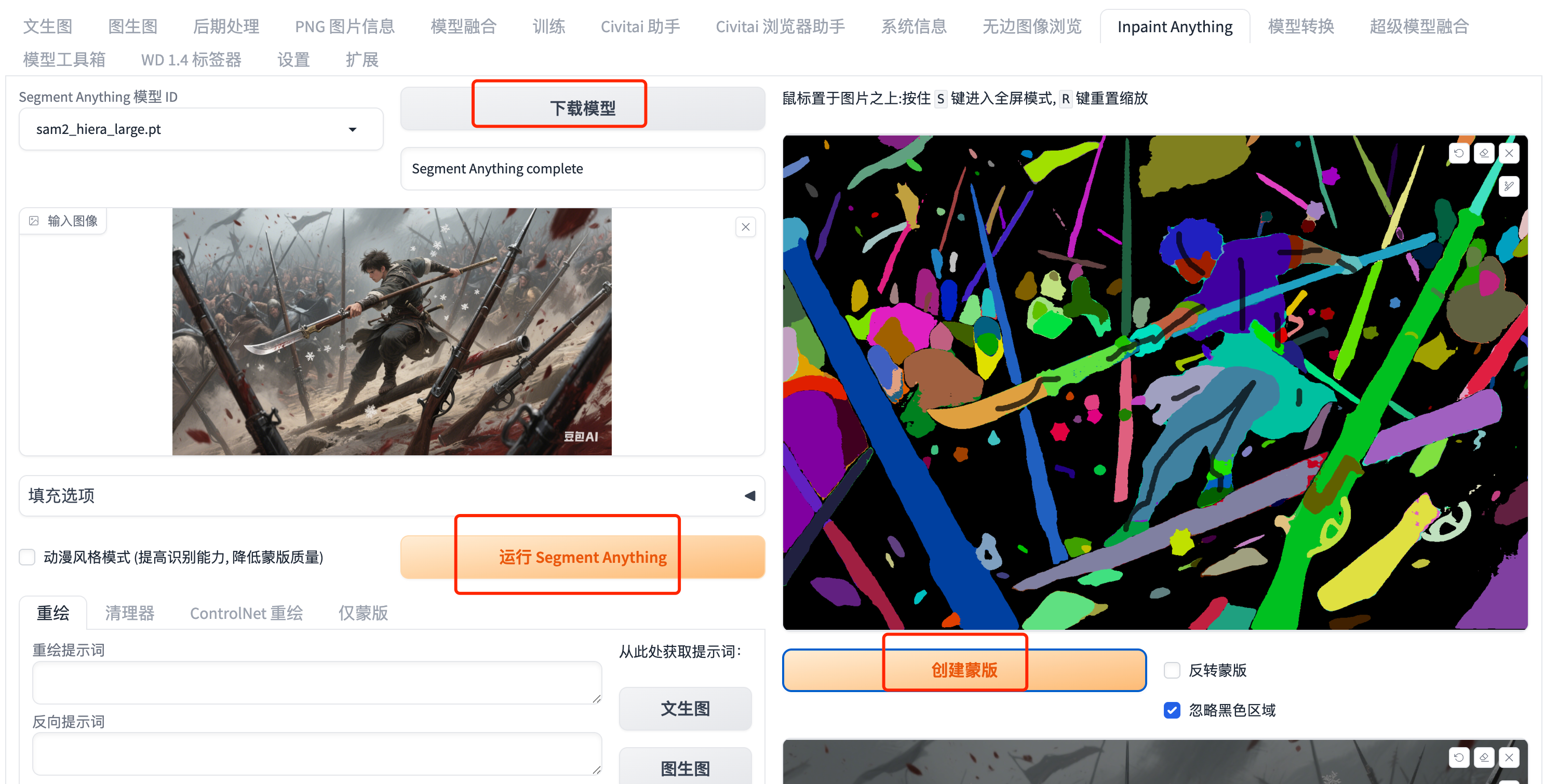
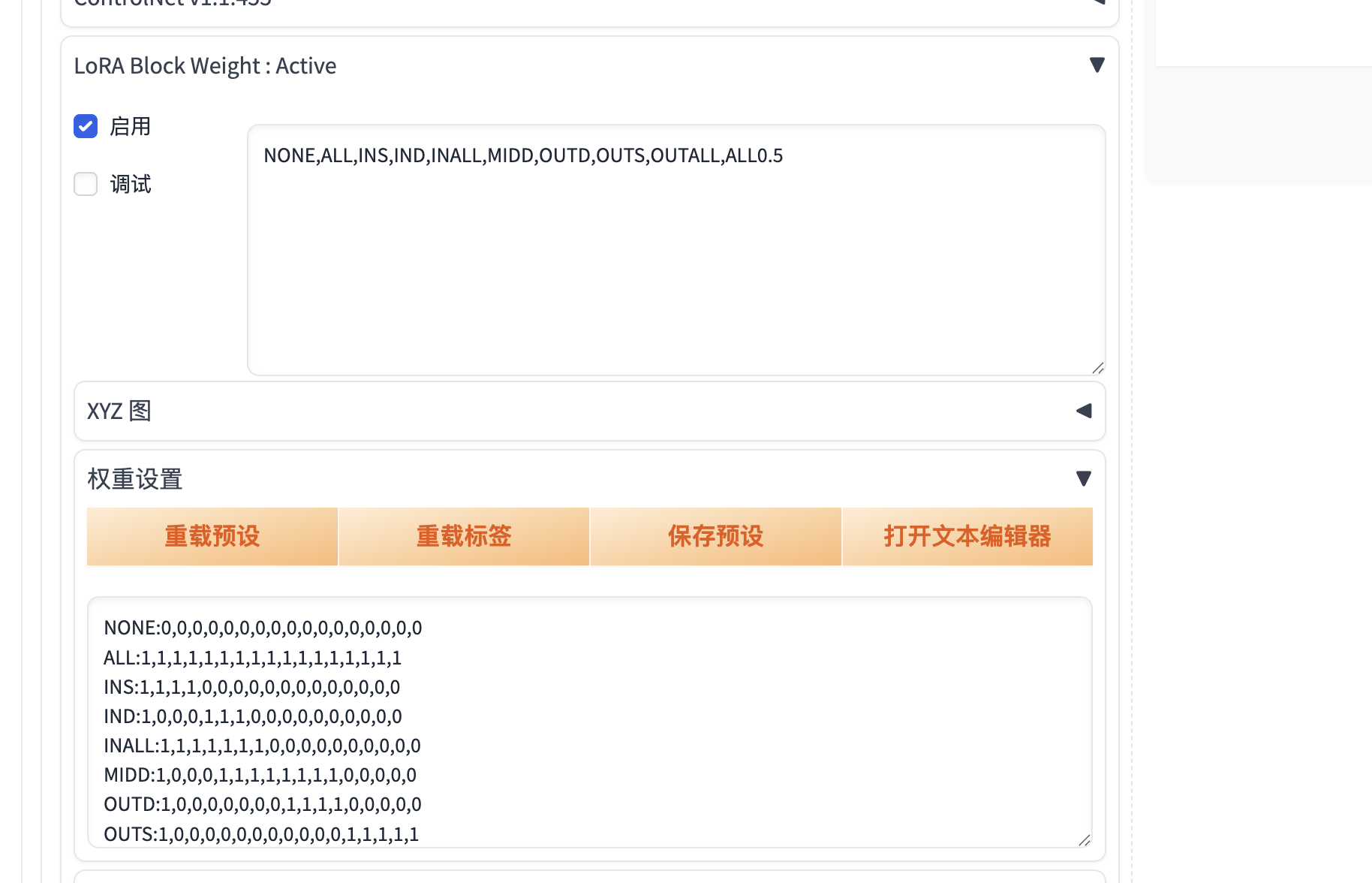
11. sd-webui-lora-block-weight
功能:调整 LoRA 模型中不同模块的权重,定制生成风格。
效果:混合多个 LoRA 时避免风格冲突。
下载地址:
https://github.com/hako-mikan/sd-webui-lora-block-weight
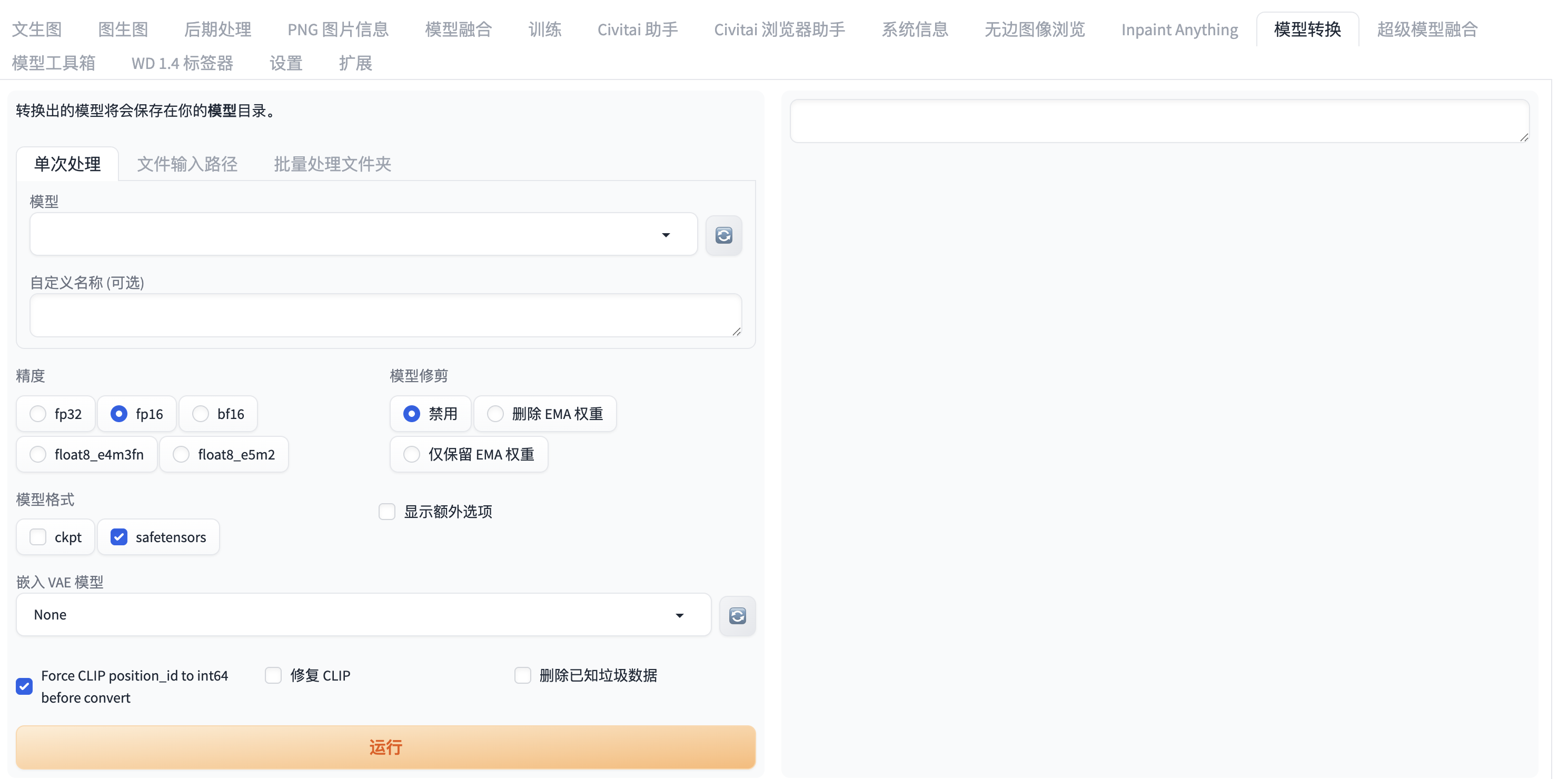
12. sd-webui-model-converter
功能:转换模型格式(如 .ckpt → .safetensors)。
效果:安全压缩模型大小,避免脚本错误。
下载地址:
https://github.com/Akegarasu/sd-webui-model-converter
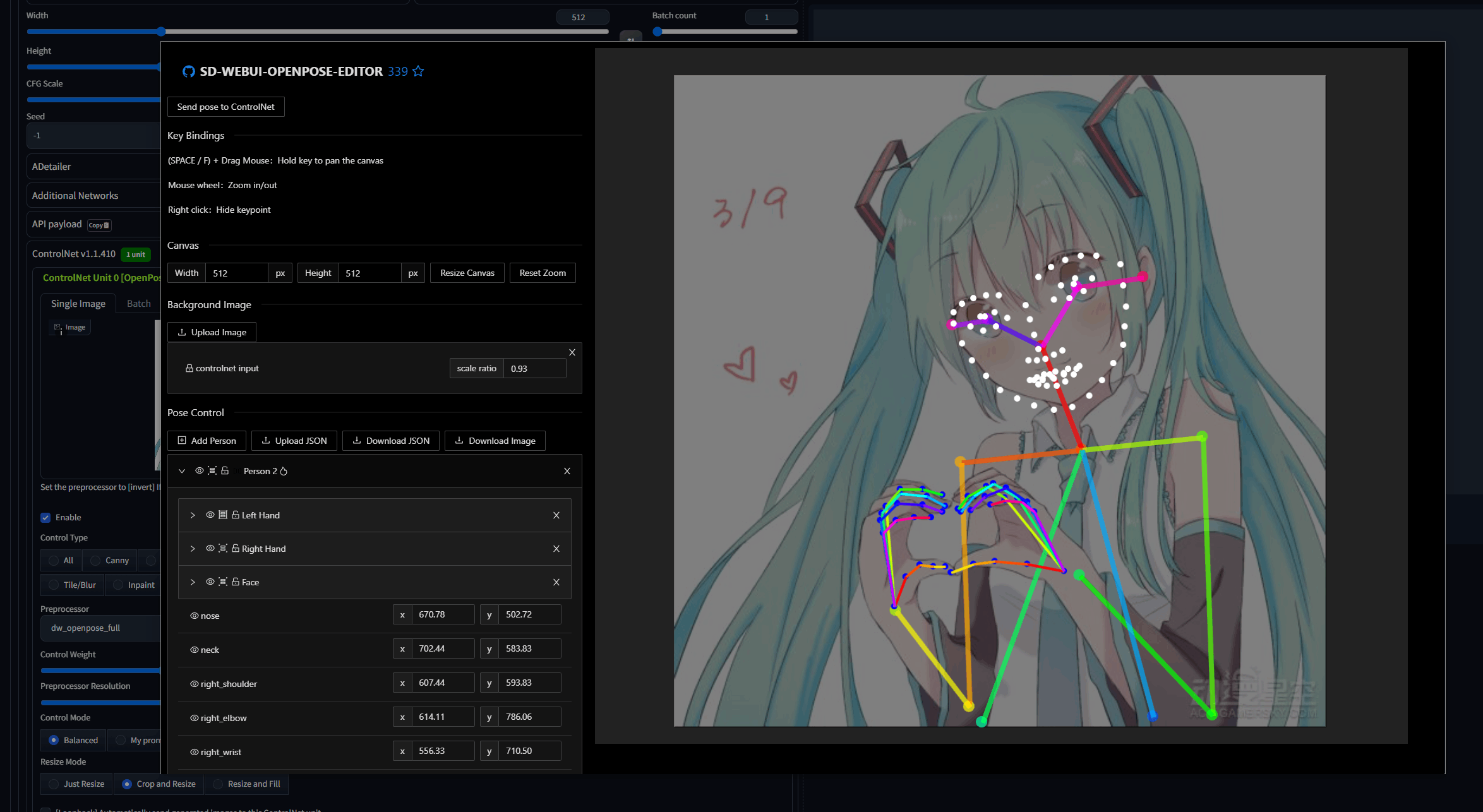
13. sd-webui-openpose-editor
功能:编辑 ControlNet 骨骼图,自定义人物姿势。
效果:类似 3D 建模软件,拖动关节调整动作。
下载地址:
https://github.com/huchenlei/sd-webui-openpose-editor
14. sd-webui-prompt-all-in-one
功能:提供提示词翻译、历史记录、风格模板等功能。
效果:支持中文输入,自动翻译为英文提示词。
下载地址:
https://github.com/Physton/sd-webui-prompt-all-in-one
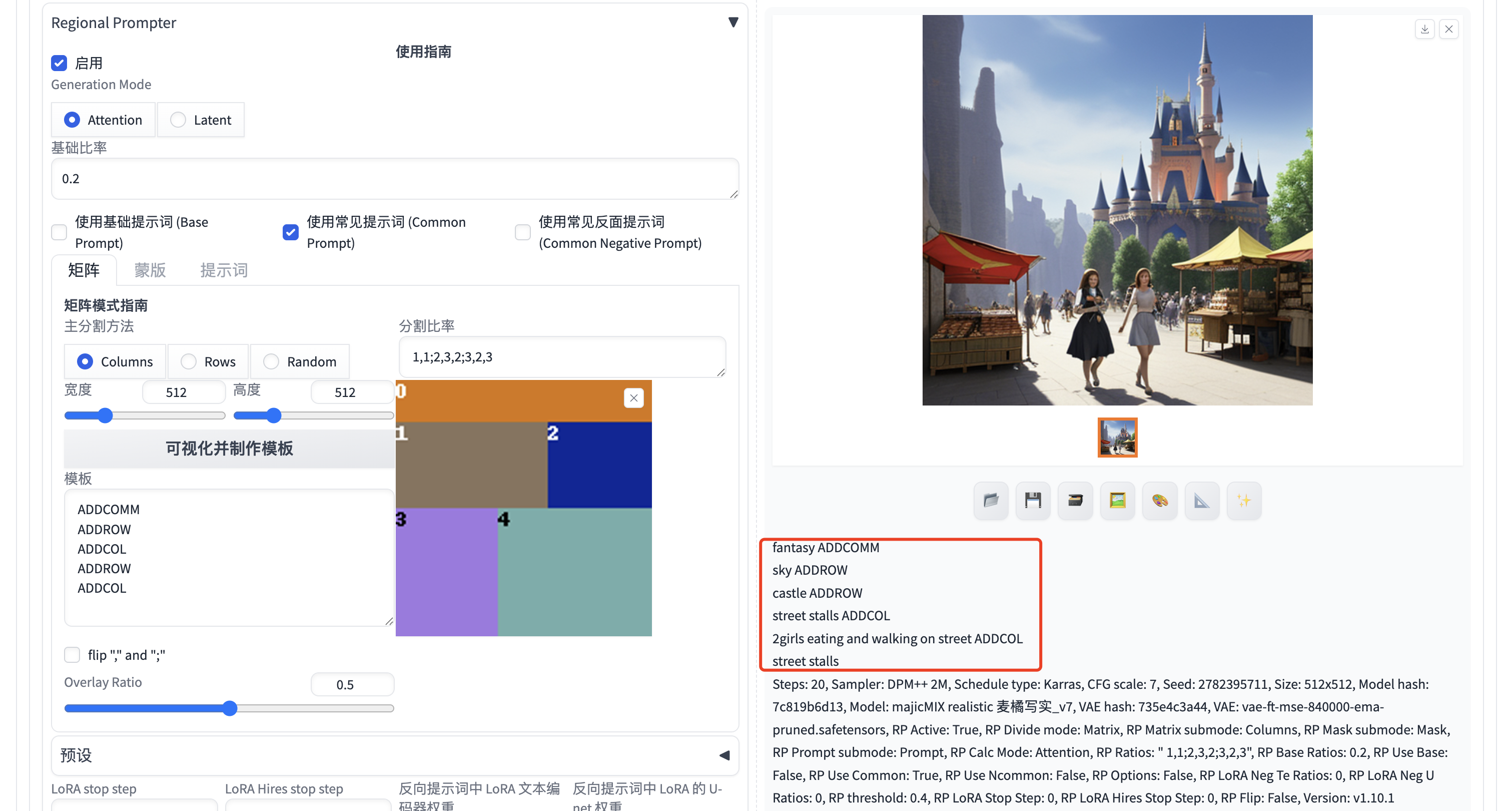
15. sd-webui-regional-prompter
功能:分区控制提示词(如左半边“星空”,右半边“森林”)。
效果:实现复杂分镜构图。
下载地址:
https://github.com/hako-mikan/sd-webui-regional-prompter
16. sd-webui-segment-anything
功能:一键分割图像中的物体(类似 PS 快速选择工具)。
效果:自动生成蒙版,便于局部编辑。
下载地址:
https://github.com/continue-revolution/sd-webui-segment-anything
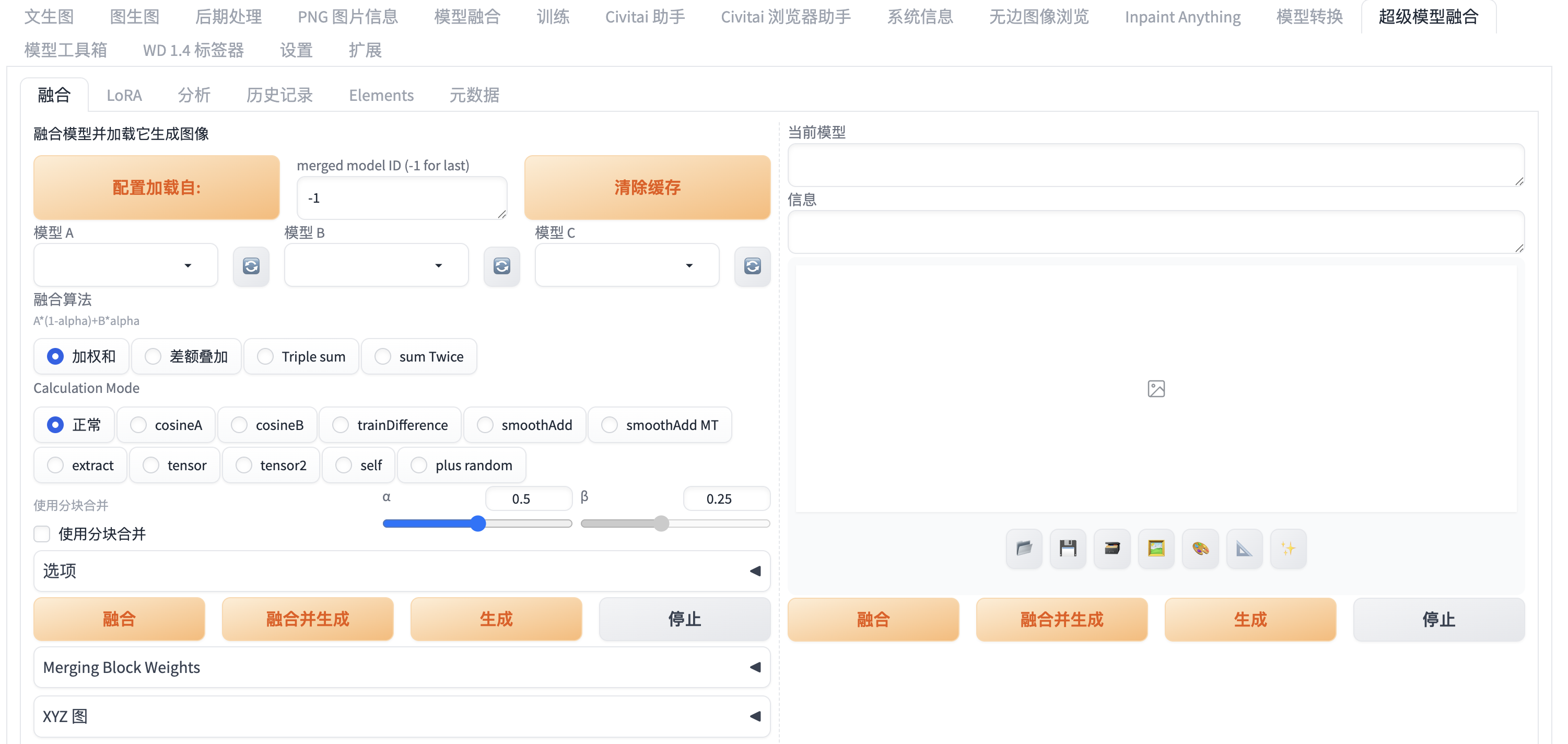
17. sd-webui-supermerger
功能:合并多个模型(Checkpoint/LoRA),创造混合风格。常规模型融合通过简单线性加权,快速混合风格,但细节易丢失、可控性差;超级模型融合可分模块精细调整,适配复杂场景,效果更优 。
效果:融合不同画风,如“写实+动漫”。
下载地址:
https://github.com/hako-mikan/sd-webui-supermerger
18. stable-diffusion-webui-localization-zh_Hans
功能:汉化 WebUI 界面,支持简体中文。
效果:所有菜单和选项显示为中文。
下载地址:
https://github.com/hanamizuki-ai/stable-diffusion-webui-localization-zh_Hans
19. stable-diffusion-webui-model-toolkit
功能:模型管理工具(查重、清理、分类)。
效果:快速筛选重复或低质量模型。
下载地址:
https://github.com/arenasys/stable-diffusion-webui-model-toolkit
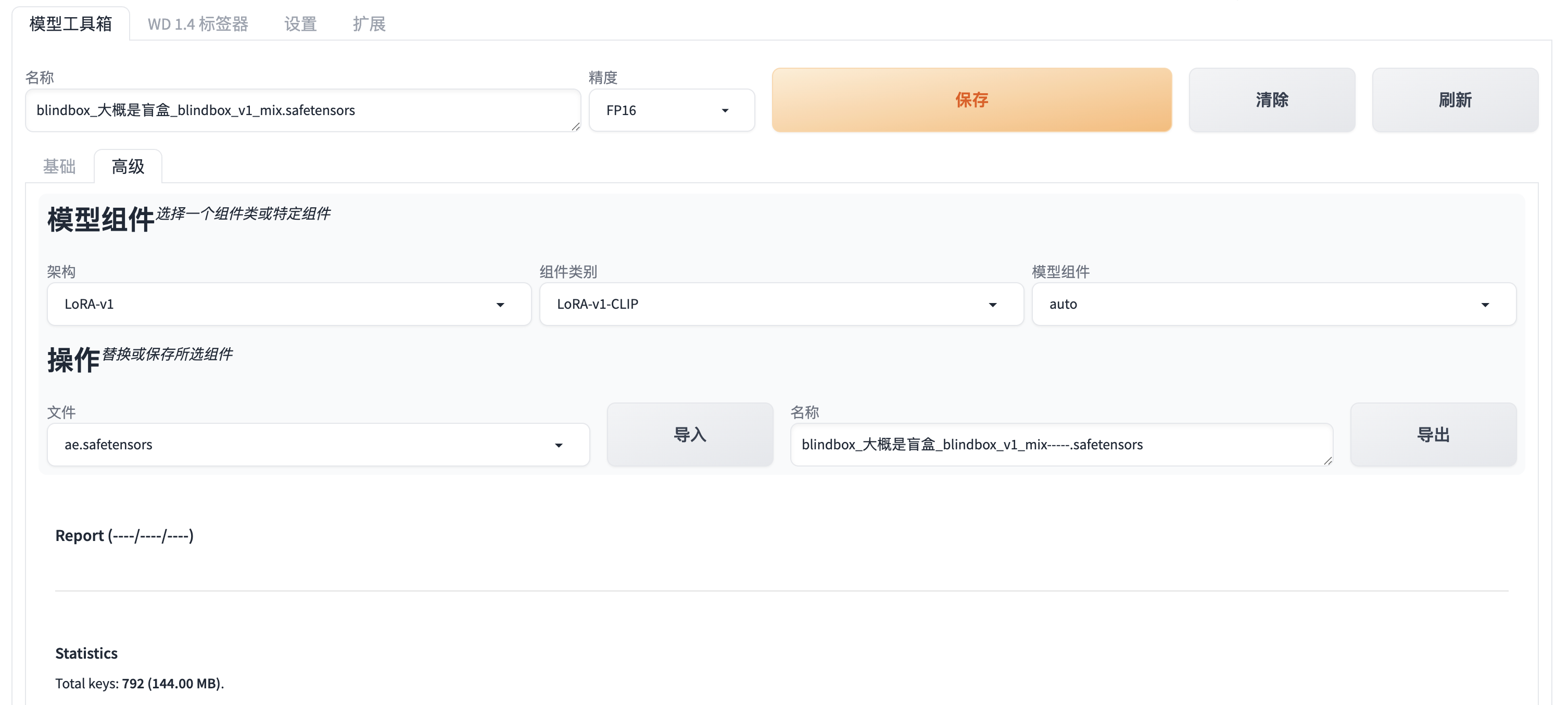
20. stable-diffusion-webui-wd14-tagger
功能:自动为图像生成标签(反向推导提示词)。
效果:分析图片生成描述文本,便于分类检索。
下载地址:
https://github.com/Delteuz/sd-webui-wd14-tagger-copyonly
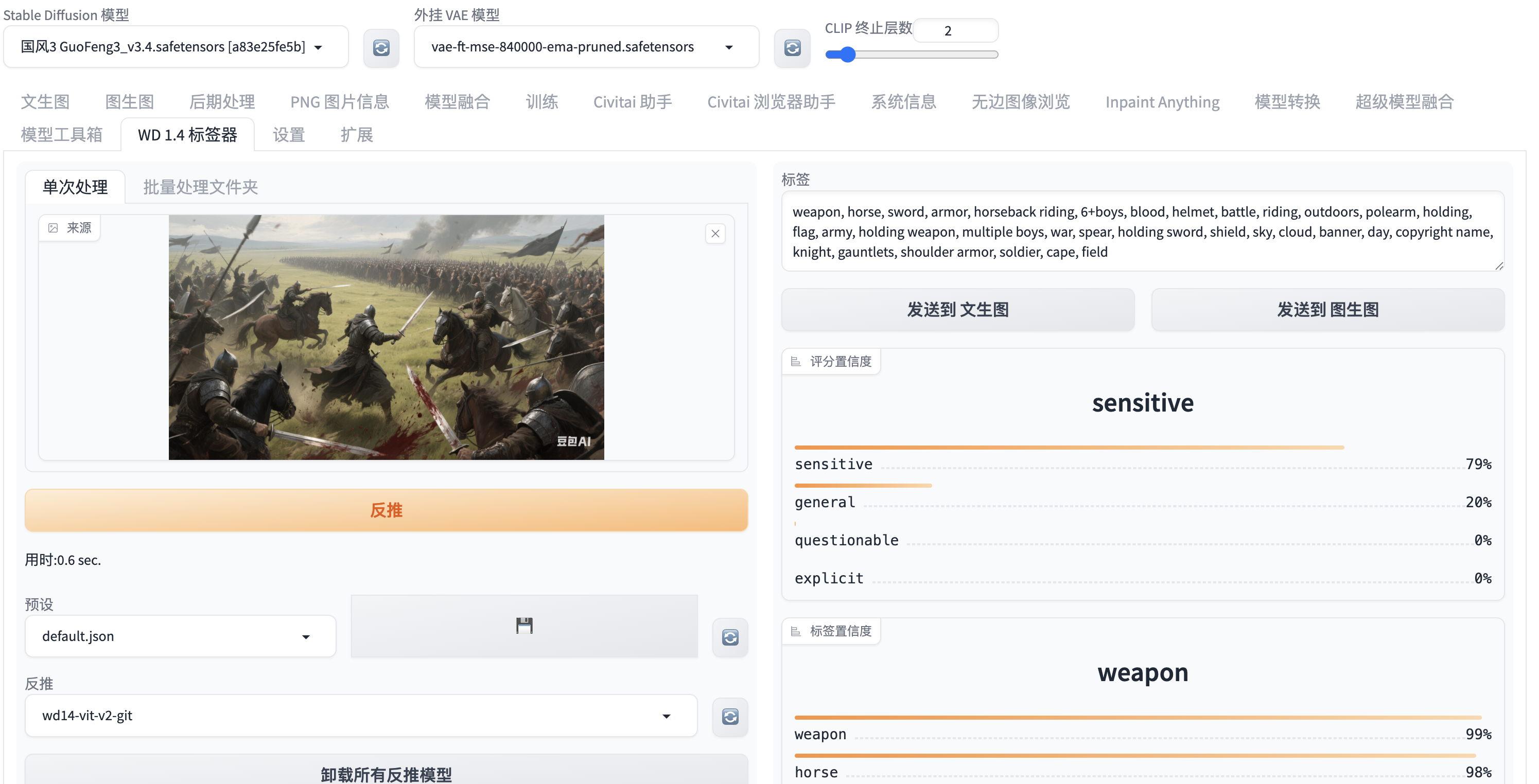
21. ultimate-upscale-for-automatic1111
功能:采用高级算法放大图像,减少失真。
效果:放大后的图像细节更清晰,无明显锯齿,适合老照片修复、低分辨率素材高清化、动漫风格放大。。
下载地址:
https://github.com/Coyote-A/ultimate-upscale-for-automatic1111
总结
这些插件涵盖了 模型管理、图像修复、动画生成、提示词优化、高清放大 等多个方面,能极大提升 Stable Diffusion WebUI 的使用体验。建议根据自己的需求选择性安装,避免插件过多影响性能。
如果你有特别感兴趣的插件,可以访问对应的 GitHub 页面查看详细教程和演示效果!也可以关注公众号 仗剑浮生 ,获取更多AI资料哦! 🚀


















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











