







 本文详细介绍了如何在Ubuntu16.04环境下搭建Hadoop单节点,并配置Hadoop完全分布式集群。包括安装JDK、SSH无密码登录、Hadoop安装及配置等多个步骤。
本文详细介绍了如何在Ubuntu16.04环境下搭建Hadoop单节点,并配置Hadoop完全分布式集群。包括安装JDK、SSH无密码登录、Hadoop安装及配置等多个步骤。
一、Hadoop单个节点初始配置
环境:
Win10系统装虚拟机: 虚拟机VMware-workstation-full-10.0.0-812388.exe
Linux系统 : Ubuntu16.04
JDK : openjdk-8-jre openjdk-8-jdk或者其它版本
搭建步骤:
1. 首先在win10系统装虚拟机,执行VMware-workstation-full-10.0.0-812388.exe;
2. 在虚拟机上装Ubuntu16.04;
3. 创建hadoop用户:
相关命令:
useradd -m hadoop -s /bin/bash
passwd hadoop //接着使用如下命令设置密码,可简单设置为 hadoop
adduser hadoop sudo //可为 hadoop 用户增加管理员权限,方便部署
sudo shutdown –r now //最后命令重启- 安装完成Ubuntu16.0.4之后,需要安装JDK,下面是安装jdk的具体步骤:
方法一:
a. 从sun公司网站www.sun.com下载linux版本的jdk, 将jdk复制到/usr目录下,然后进入/usr目录cd /usr
5. 安装完成Ubuntu16.0.4之后,需要安装JDK,下面是安装jdk的具体步骤:
b. 从sun公司网站www.sun.com下载linux版本的jdk, 将jdk复制到/usr目录下,然后进入/usr目录cd /usr
c. 添加执行权限
chmod +x jdk-6u7-linux-i586.bind. 执行安装命令./jdk-6u7-linux-i586.bin
d.安装成功会在/usr目录下生成jdk1.6.0_45目录,就是jdk的安装目录重启电脑,打开终端,输入java –version如图。

4.安装完JDK后我们需要对jdk进行一些配置,步骤如下:
a.进入/etc目录,对profile配置文件进行一些修改,输入命令:nano profile
b.最后面添加如下内容
export JAVA_HOME=/home/hadoop/jdk1.6.0_45 #将“JDK安装路径”改为上述命令得到的路 $
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar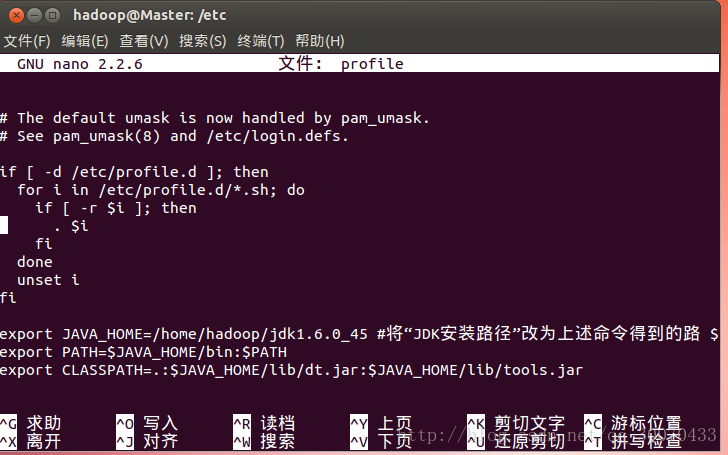
配置完成之后输入命令:source /etc/profile执行配置文件,
e. 配置完成之后,重启,下面需要进行验证。
输入命令查看环境变量:echo $PATH
如图所示,jdk配置完毕。

注意!ubantu在配置完profile之后需要重启一下,不然切换窗口命令行后环境变量无法实时更新!
方法二:
直接用命令安装ubantu自带的OpenJDK 8即可
相关下载命令:sudo apt-get install openjdk-8-jre openjdk-8-jdk
配置环境变量:
修改~/.bashrc
在开头加上
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar至此,jdk配置完毕
5、1. 安装ssh服务,命令如下
:sudo apt-get install ssh openssh-server相关命令:
ssh localhost
cd ~/.ssh/
ssh-keygen -t rsa # 一直按enter键就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权安装完成SSH后,可以使用命令查看SSH是否启动:ps -e|grep ssh

安装SSH服务完成后就需要配置无密码登录,见相关命令。
注意:
测试连接本地ssh时如果
出现ssh: connect to host localhost port 22: Connection refused时
解决方法:``` sudo apt-get purge openssh-server sudo apt-get install openssh-server ```- 安装hadoop2
相关命令:
sudo tar -xvzf hadoop-2.6.0.tar.gz -C /usr/local/ # 解压到/usr/local中
cd /usr/local/
sudo mv hadoop-2.6.0 ./hadoop # 改文件名
sudo chown -R hadoop ./hadoop # 修改所属用户与所属用户组Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息。
相关命令:
cd /usr/local/hadoop
bin/hadoop version如图所示,hadoop2已经安装完毕

在安装完ssh,hadoop,jkd,之后,下面进行第二部分步骤:
二、Hadoop完全分布式配置
拓扑图如下:
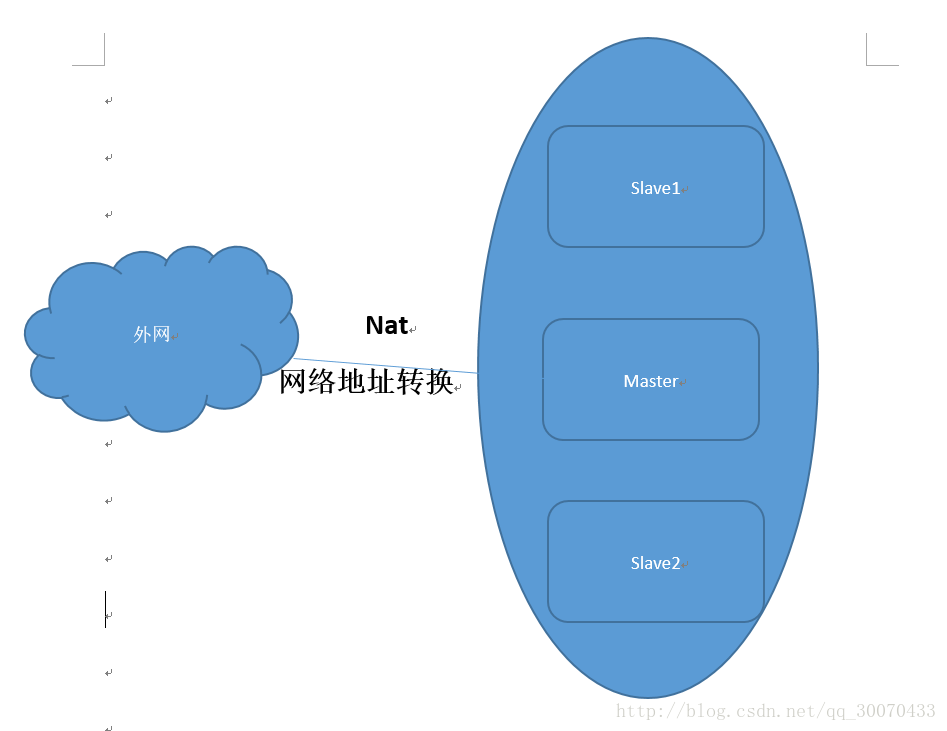
在安装完单个节点Master(控制节点)的基本软件之后,关闭虚拟机,复制镜像文件作为另外两个节点Slave1和Slave2,下面我们对着三个节点进行分别配置。
第一步:hostname配置:
相关命令:
sudo nano /etc/hostname保存完毕后,重启Slave1和Slave2节点,值得配置生效。
重启后如图所示:
保存完毕后,重启Slave1和Slave2节点,值得配置生效。
重启后如图所示:


第二步:net配置:
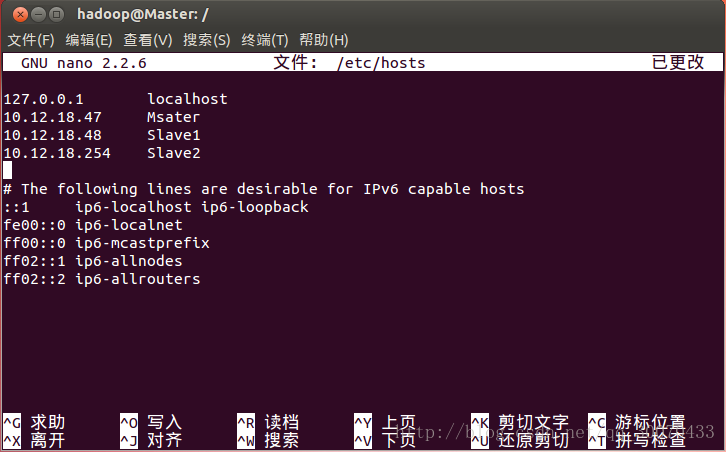
使用ifconfig命令查看IP地址和网关
对三个节点的/etc/hosts文件都配上所查到的IP地址
如图所示:
**第三步:配置/etc/network/interfaces,配置如下:
Master节点:
interfaces(6) file used by ifup(8) and ifdown(8)
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto ens33 #网卡名
iface ens33 inet static #静态配置
address 10.12.18.47
netmark 255.255.255.0
gateway 10.12.18.2#网关Slave1节点:
interfaces(6) file used by ifup(8) and ifdown(8)
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto ens33 #网卡名
iface ens33 inet static #静态配置
address 10.12.18.48
netmark 255.255.255.0
gateway 10.12.18.2#网关Slave2节点:
interfaces(6) file used by ifup(8) and ifdown(8)
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto ens33 #网卡名
iface ens33 inet static #静态配置
address 10.12.18.49
netmark 255.255.255.0
gateway 10.12.18.2#网关第四步:配置DNS(如果不需要联网可以跳过此步骤!)
相关命令
sudo vim /etc/resolvconf/resolv.conf.d/base添加如下内容
nameserver 114.114.114.114第五步:SSH相关配置
相关命令:
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys
tar -czvf aaa * //打包发送使使各点内容同步
scp sss hadoop@Slave1:/home/hadoop#通过SCP远程服务把Master打包的ssh秘钥发送到Slave1节点上
scp sss hadoop@Slave2:/home/hadoop#通过SCP远程服务把Master打包的ssh秘钥发送到Slave2节点上Slave1和Slave2节点操作:
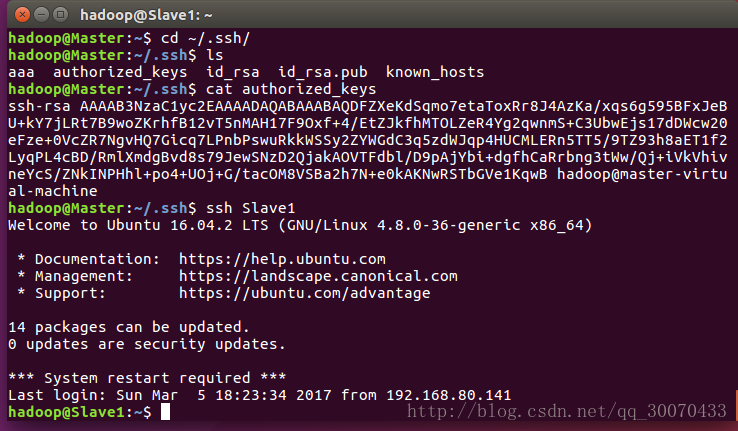
首先创建一个文件夹:mkdir ~/.ssh
把在home/hadoop目录下的接受的sss文件解压到~/.ssh上
相关命令:
mv aaa ~/.ssh
cd ~/.ssh
tar -xzvf aaa如图所示,ssh 已经可以实现无密码传输
最后一步:hadoop相关操作:
但当我们进入/user/local/hadoop/etc/hadoop/目录下我们可以看到如图:
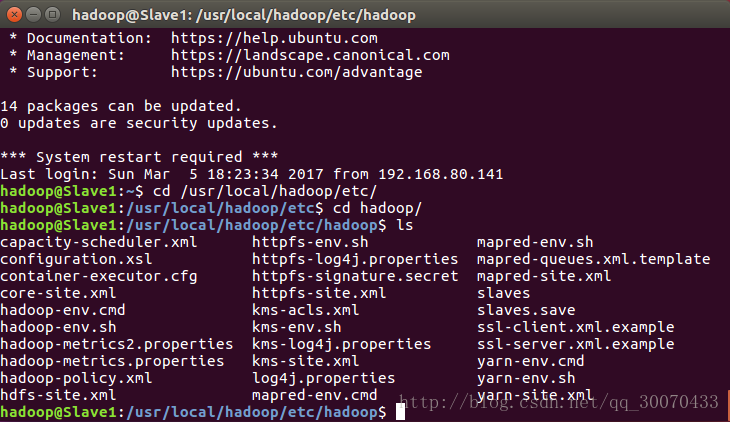
下面,我们需要进行一些文件的修改
a.slaves需要文件配置关联数据节点注册:
相关命令:`sudo nano slaves

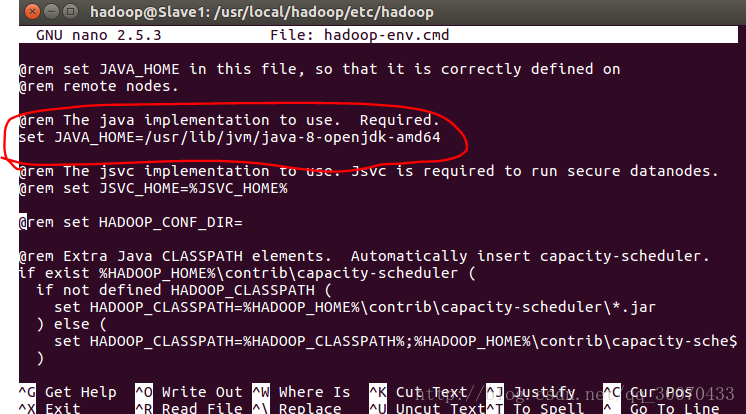
b.配置hadoop-env.cmd 文件
相关命令:
sudo nano hadoop-env.cmd 如图
c.配置mapred-site.xml 文件!默认文件名为 mapred-site.xml.template.在这一步要注意的是要先改名
相关命令:mv mapred-site.xml.template mapred-site.xml
改完名之后在这个文件添加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master(主机名):10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>d.配置hdfs-site.xml文件
添加如下内容:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>e.配置yarn-site.xml文件
添加如下内容:
configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>#这边注意的是Master就是主机名
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>f.配置core-site.xml,用于启动nameNode进程。
配置如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value> //master即为控制节点的主机名,
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>最后在Master节点配置完毕之后打包起来发送到Slave1和Slave2节点
相关命令:
sudo tar -cvzf ~/hadoop.master.tar.gz ./hadoop # 压缩复制
cd ~
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
scp ./hadoop.master.tar.gz Slave2:/home/hadoop在Slave1和Slave2解压hadoop.master.tar.gz放在和Master节点相同的目录
最后的最后,还要配置三个节点的hadoop的环境变量
输入命令:sudo nano~/.bashrc
在里面的最前面添加如下内容
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:/usr/local/hadoop/bin:/usr/local/hadoop/sbin改完之后执行一下:source ~/.bashrc
三运行前的准备
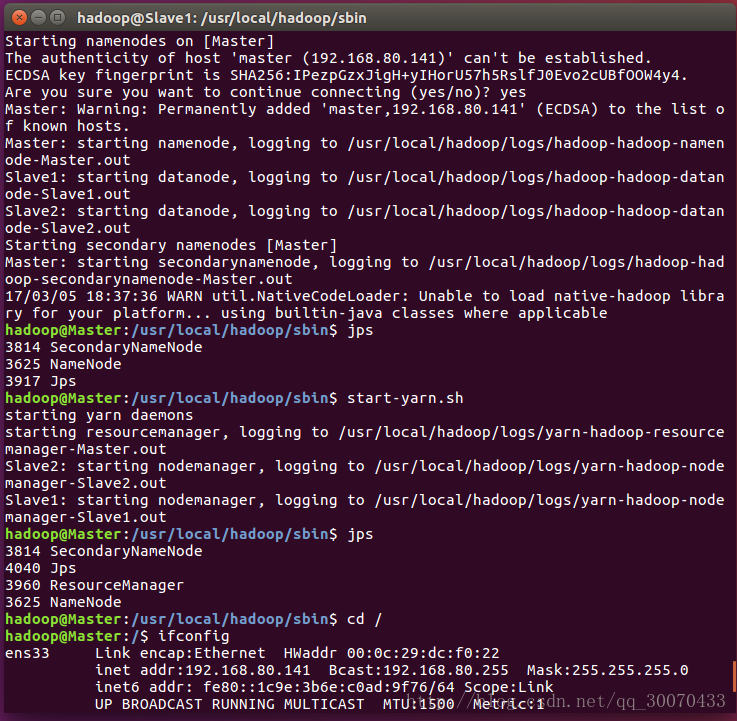
首先使用命令:hdfs namenode -format //初始化(#只能执行一次),用来建立hdfs结构来存元数据。
下面进入目录:hadoop@Master:/usr/local/hadoop/sbin$ 下运行hadoop
相关命令:
开启hadoop 的命令是:start-*.sh
关闭hadoop 的命令是:stop-*.sh注意的是开启和关闭的过程会比较慢,稍微等一下
开启之后,发现开启了6个进程,用jps命令查看jdk下的进程如图
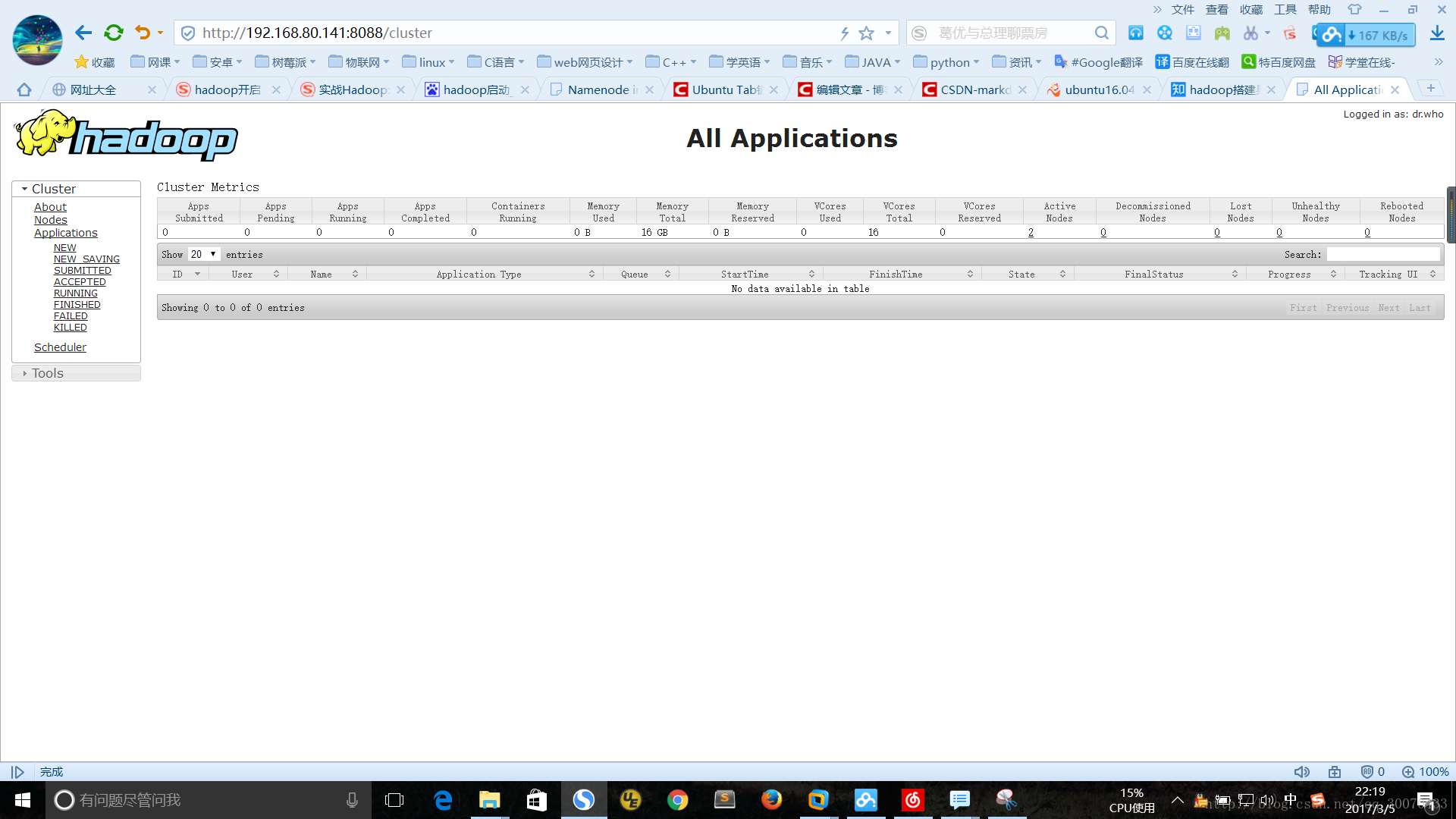
网页输入网址如图:
http://ip地址:8088/cluster
http://IP地址:50070/dfshealth.html#tab-overview
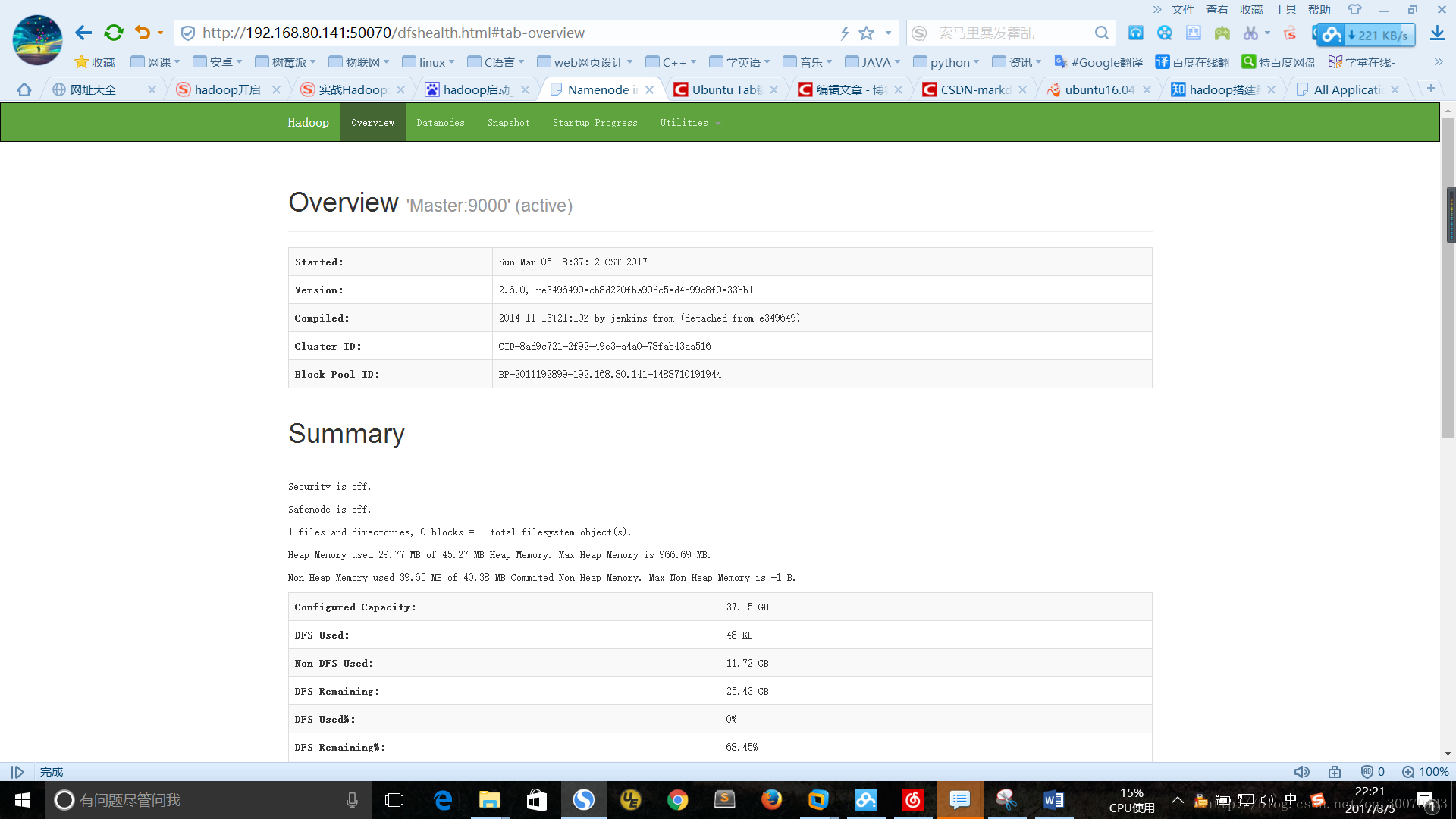
遇到的问题!
问题1:如果出现虚拟机上hadoop已经成功开启,但是Windows系统上的浏览器打不开端口?
解决方案:
打开“网络和共享中心”->“更改适配器设置”中查看VM服务是否开启,如果被禁用了,启动服务即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









