






CPU register的速度一般小于1ns,主存的速度一般是65ns左右。当CPU试图从主存中load/store 操作时,由于主存的速度限制,CPU不得不等待这漫长的65ns时间。
为解决CPU与主存的速度匹配可采用cache存储器。cache存储器是位于CPU和主存储器DRAM之间,规模较小,但速度很高的存储器,通常由静态存储器组成。当CPU试图从主存中load/store数据的时候, CPU会首先从cache中查找对应地址的数据是否缓存在cache 中。如果其数据缓存在cache中,直接从cache中拿到数据并返回给CPU。
Cache根据地址映射方式分为直接映射、全相联映射、组相联映射。
1.直接映射
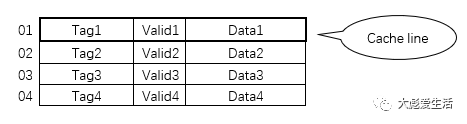
如表中所示,一个Cache line包括tag(地址标签),valid(有效位),还有data(数据)。
首先以直接映射的cache组成方式进行分析:
以物理内存地址7bit举例,可以将内存地址分为以下几段:

将内存地址中的Tag位域与cache line中的Tag对应,将内存地址中的Index与cacheline的地址对应,将Block Offset与cache line的DATA偏移对应。
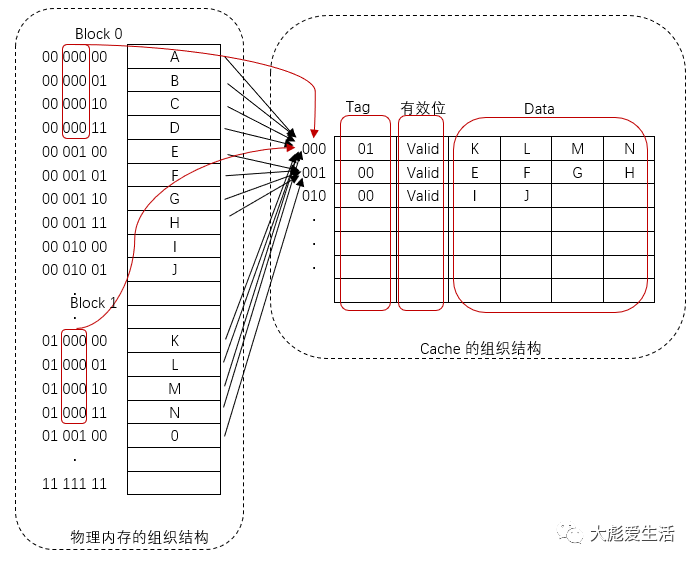
由于Block Offset是两位,那么对应着一个cache line的data字段包含2²=4个字节的数据;index为3位,说明cache共包含2³=8个组(对于直接映射的cache,也称为8个行); 上图中物理内存可以分为2^2 = 4块(Block ),每个块都有由Index选择可以映射到cache line的数据块,也就是说共有4个数据块竞争使用同一cache line,此时通过Tag字段的比较来辨别是不是我们要取数据的地址,如果不是的话,也就是发生了cache的缺失,此时进一步定量分析的话,cache的命中率为25%。
2.全相联映射
将内存地址分为两部分,将内存地址中的Tag位域与cache line中的Tag对应,将BlockOffset与cache line的DATA偏移对应。
全相联映射中,根据地址中的tag部分和所有的cache line对应的tag进行比较(硬件上可能并行比较也可能串行比较)。哪个tag比较相等,就意味着命中某个cache line。因此,在全相连缓存中,任意地址的数据可以缓存在任意的cache line中。所以,这可以最大程度的降低cache颠簸的频率。但是硬件成本上也是更高。
3.组相联映射
组相联映射实际上是直接映射和全相联映射的折中方案。主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。也就是说,将Cache分成u组,每组v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。
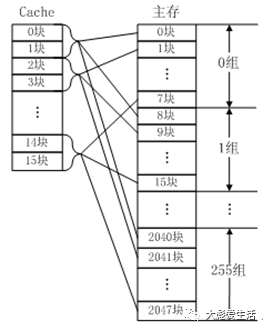
例如,主存分为256组,每组8块,Cache分为8组,每组2块。
常采用的组相联结构Cache,每组内有2、4、8、16块,称为2路、4路、8路、16路组相联Cache。组相联结构Cache是前两种方法的折中方案,适度兼顾二者的优点,尽量避免二者的缺点,因而得到普遍采用。
4.实例列举
以Intel处理器的CPU cache举例,Core 2的L1 cache访问方式如下:
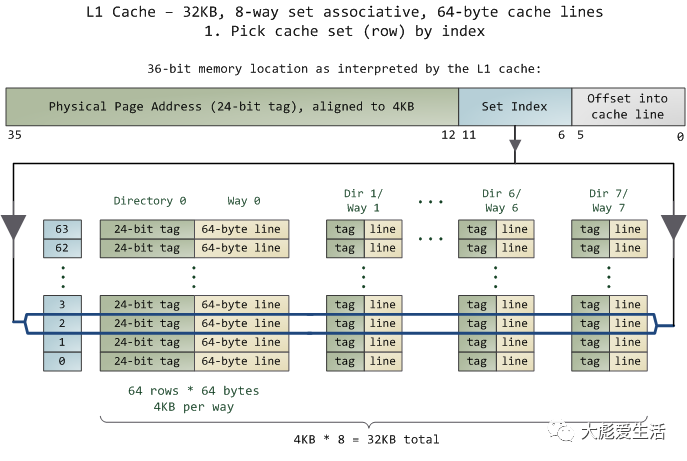
L1 cache – 32KB,8路组相联,64字节缓存线。
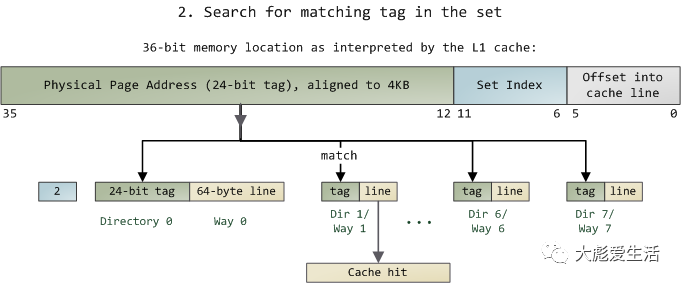
由于只需要去查看某一组中的8路,所以查找匹配标记是非常迅速的;事实上,从电学角度讲,所有的标记是同时进行比对的。如果此时正好有一条具有匹配标签的有效缓存线,就获得一次缓存命中(cache hit)。否则,这个请求就会被转发的L2 cache,如果还没匹配上就再转发给主系统内存。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









