







Extracting, transforming and selecting features
这部分将会讲到特征的算法,粗略的分为一下几个部分:

特征的提取
TF-IDF
词条频率-逆向文件频率是一种被广泛使用在文本提取的向量化特征的方法,反映了一个词条对一篇语料库中的文章的重要性。条目表示为t,一篇文档表示为d,语料库表示为D,词条频率TF(td)是词条t出现在文档d中的次数,而文档频率DF是包含这个词条的文档数目,简而言之就是多少篇文档包含这个词条。如果我们仅仅用词条频率来估量重要程度,很容易偏重词条经常出现但只有很少信息的文档,比如“a”,”the”,和”of”,如果一个词条经常出现在预料库中,这意味着这个条目没有特殊意义对于一个文档。反向文档频率是队一个词条所携带的信息量做数字化估量的方法:
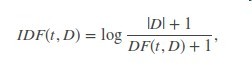















 1956
1956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









