







结合视频第四集和笔记:https://zhuanlan.zhihu.com/p/21462488?refer=intelligentunit
简介

生物动机与连接

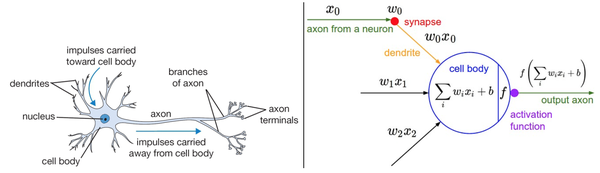
输入x与权重w做内积 —-> 内积结果输入激活函数 —> 从激活函数输出信号
一个神经元前向传播的实例代码:
class Neuron(object):
# ...
def forward(inputs):
""" 假设输入和权重是1-D的numpy数组,偏差是一个数字 """
cell_body_sum = np.sum(inputs * self.weights) + self.bias
firing_rate = 1.0 / (1.0 + math.exp(-cell_body_sum)) # sigmoid激活函数
return firing_rate生物神经元的树突可以进行复杂的非线性计算。突触并不就是一个简单的权重,它们是复杂的非线性动态系统,所以这个只是一个粗糙模型。
作为线性分类器的单个神经元

常用激活函数
1.sigmoid 和 tanh
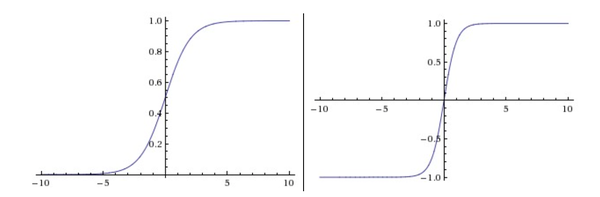
左边是Sigmoid非线性函数,将实数压缩到[0,1]之间。右边是tanh函数,将实数压缩到[-1,1]。
Sigmoid函数有两个缺点:
- Sigmoid函数饱和使梯度消失
- Sigmoid函数的输出不是零中心的
tanh解决了Sigmoid函数输出不是零中心的问题。并且

2.ReLu
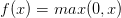
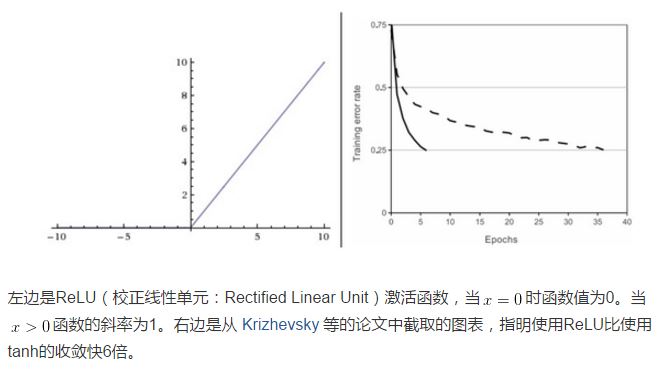

3.Leaky ReLU
Leaky ReLU是为解决“ReLU死亡”问题的尝试。ReLU中当x<0时,函数值为0。而Leaky ReLU则是给出一个很小的负数梯度值,比如0.01。所以其函数公式为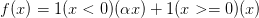
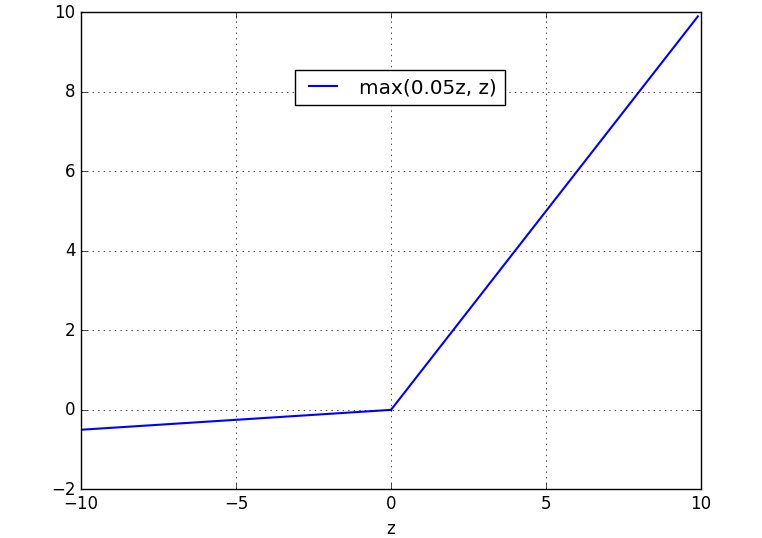
4.指数线性单元(Exponential Linear Units, ELU)
ELU的公式为:
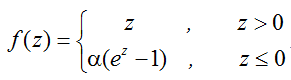
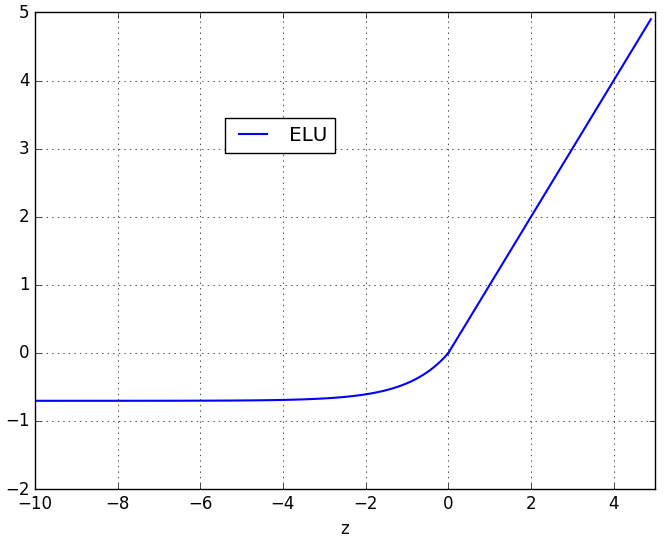
ELU除了具有LReLu的优点外,还有输出结果接近于0均值的良好特性;但是,计算复杂度会提高。
—> ps: 通常我们在神经网络中只使用一种激活函数。
5.Maxout

神经网络的结构(ps: 这里指前馈(feedforward)神经网络,网络中是没有回路的,信息总是向前传播,不反向回馈),神经网络通常有如下结构:
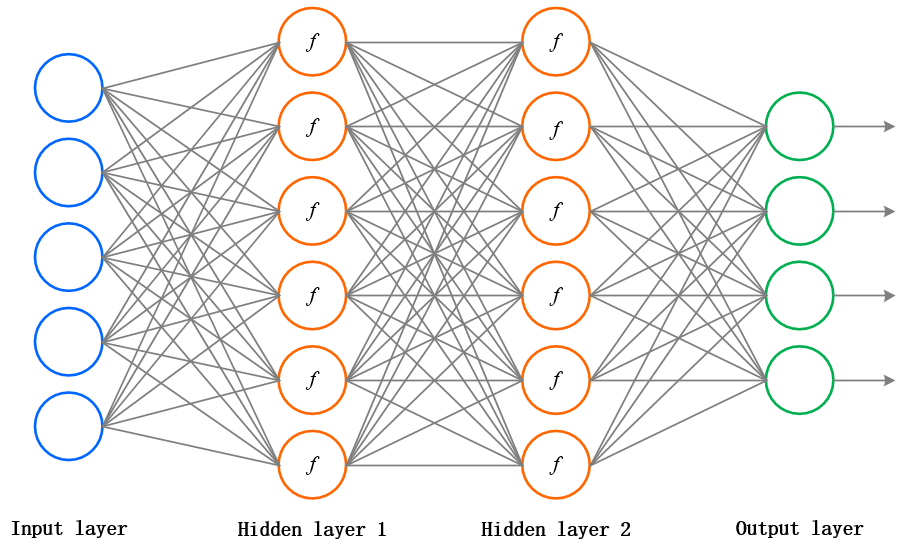
上图是一个含有两个隐藏层的3-layer神经网络,层与层之间是全连接(fully-connected)的。输入层是图像数据(经过预处理后的),即该层的神经元数量等于输入图片的维数;神经网络的隐藏层可以是一层或多层,多层神经网络我们称为人工神经网络(ANN),其实最后一层隐藏层,我们可以看成是输入图像的特征向量;输出层神经元的数量等于需要分类的图像数据的类别数,输出值可以看成是在每个类别上的得分。
对于分类任务而言,根据损失函数(SVM loss function or softmax loss function)选择的不同,神经网络的输出层也可以看作是SVM层或Softmax层。神经网络的激活函数是非线性的,所以神经网络是一个非线性分类器。
—> (ps: 神经网络的输出层神经元不含激活函数f)
神经网络的多层结构给它带来了非常强大的表达能力(层越深,神经元数量越多,表达能力越强),换句话说,神经网络可以拟合任意函数!具体的可视化证明可以移步这里。但是,隐藏层或神经元数量越多,越容易出现过拟合(overfitting)现象,这时我们需要使用规则化(L2 regularization, dropout等等)来控制过拟合。

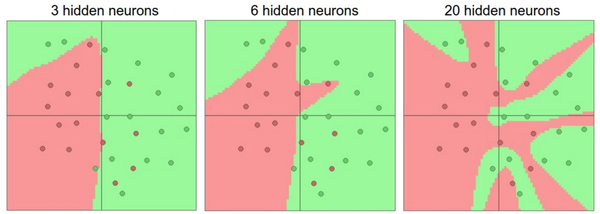
在上图中,可以看见有更多神经元的神经网络可以表达更复杂的函数。然而这既是优势也是不足,优势是可以分类更复杂的数据,不足是可能造成对训练数据的过拟合。过拟合(Overfitting)是网络对数据中的噪声有很强的拟合能力,而没有重视数据间(假设)的潜在基本关系。举例来说,有20个神经元隐层的网络拟合了所有的训练数据,但是其代价是把决策边界变成了许多不相连的红绿区域。而有3个神经元的模型的表达能力只能用比较宽泛的方式去分类数据。它将数据看做是两个大块,并把个别在绿色区域内的红色点看做噪声。在实际中,这样可以在测试数据中获得更好的泛化(generalization)能力。
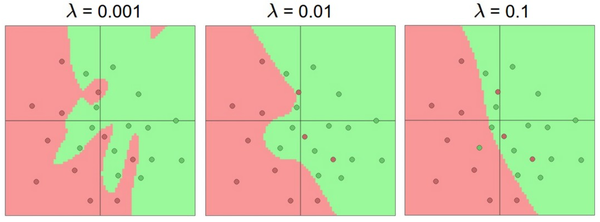
不同正则化强度的效果:每个神经网络都有20个隐层神经元,但是随着正则化强度增加,它的决策边界变得更加平滑。需要记住的是:不应该因为害怕出现过拟合而使用小网络。相反,应该进尽可能使用大网络,然后使用正则化技巧来控制过拟合。
补充:
梯度消失问题:
以sigmoid为例:
之前我们已经介绍了sigmoid函数,但是在实际应用中,我们基本不会使用它,因为它的缺陷较多。先看下σ的导数:

sigmoid导数值在0到0.25之间。在进行反向传播的时候,σ′会和梯度相乘,前面层的梯度值等于后面层的乘积项,那么越往前梯度值越小,慢慢趋近于0,这就是梯度消失问题(vanishing gradient problem)。为了便于理解梯度为什么会消失,我们给出一个每层只有一个神经元的4-layer简化模型:

其中,C表示代价函数,aj = σ(zj)(注意,a4 = z4),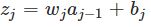
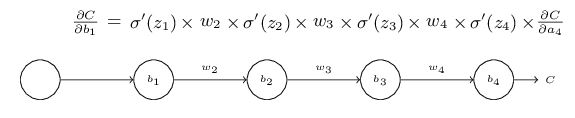
推导过程:
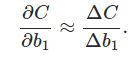
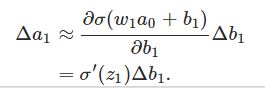
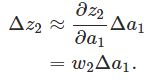

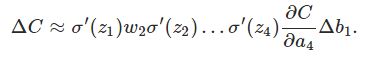
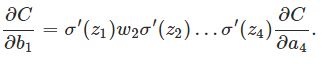
σ′是σ函数的导数,
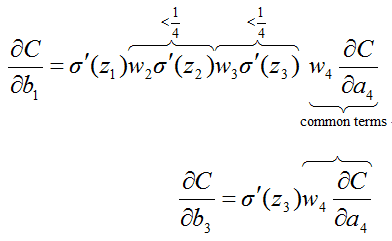
我们看出∂C/∂b1会是∂C/∂b3的1/16 或者更小,这其实就是梯度消失的本质原因。这会导致深层神经网络前面的隐藏层神经元学习速度慢于后面隐藏层神经元的学习速度,而且越往前越慢,最终无法学习。
—> ps: 对于这个问题,不论使用什么样的激活函数,都会出现,但是有些激活函数可以减轻这一问题。说到这里,不得不提一下Batch Normalization,http://arxiv.org/abs/1502.03167。这一方法在很大程度上缓解了梯度消散问题。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









