







翻译笔记:https://zhuanlan.zhihu.com/p/21462488?refer=intelligentunit
1.Sigmoid
Sigmoid函数将实数压缩到[0,1]之间,如下图左所示。现在sigmoid函数已经不太受欢迎,实际很少使用了,这是因为它有两个主要缺点:
Sigmoid函数饱和使梯度消失 ,当神经元的激活在接近0或者1时会饱和,在这些区域,梯度几乎为0,这样,在反向传播过程中,局部梯度就会接近0,这会有效地“杀死”梯度。
Sigmoid函数的输出不是零中心的如果输入神经元的数据总是正数(比如在 f=wTx+b 中每个元素都 x>0 ),那么关于w的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数(具体依整个表达式f而定)。这将会导致梯度下降权重更新时出现z字型的下降。
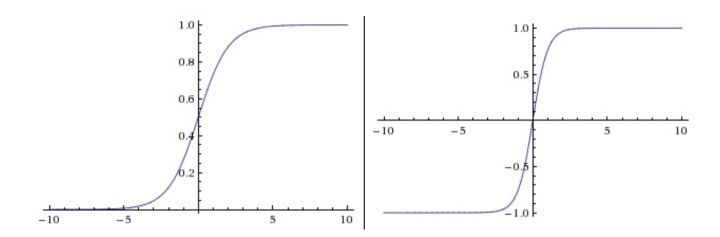
2.Tanh
tanh非线性函数图像如上图右边所示。它将实数值压缩到[-1,1]之间。和sigmoid神经元一样,它也存在饱和问题,但是和sigmoid神经元不同的是,它的输出是零中心的。因此,在实际操作中,tanh比sigmoid更受欢迎。注意tanh神经元是一个简单放大的sigmoid神经元,具体说来就是: tanh(x)=2σ(2x)−1 。
3. ReLu
下图左侧为ReLu函数的图像。换句话说,这个激活函数就是一个关于0的阈值
优点:
- 相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用( Krizhevsky 等的论文指出有6倍之多,如下图右侧)。据称这是由它的线性,非饱和的公式导致的。
- sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。

缺点:
- 在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。例如,如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。
4. Leaky ReLU
其中 α 是一个小的常量。Leaky ReLU是为解决“ReLU死亡”问题的尝试。ReLU中当x<0时,函数值为0。而Leaky ReLU则是给出一个很小的负数梯度值,比如0.01。
5. Maxout
Maxout是对ReLU和leaky ReLU的一般化归纳。ReLU和Leaky ReLU都是这个公式的特殊情况(比如ReLU就是当 w1,b1=0 的时候)。这样Maxout神经元就拥有ReLU单元的所有优点(线性操作和不饱和),而没有它的缺点(死亡的ReLU单元)。然而和ReLU对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。
总结:
如果用ReLU非线性函数,注意设置好学习率,或许可以监控你的网络中死亡的神经元占的比例。如果单元死亡问题困扰你,就试试Leaky ReLU或者Maxout,不要再用sigmoid了。也可以试试tanh,但是其效果应该不如ReLU或者Maxout。















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









