




 本文详细介绍了如何解决TensorFlow与CUDA、cuDNN版本不匹配的问题,确保GPU能够正常工作,并分享了在循环中调整参数时避免RNN实例重复使用的调试经验。
本文详细介绍了如何解决TensorFlow与CUDA、cuDNN版本不匹配的问题,确保GPU能够正常工作,并分享了在循环中调整参数时避免RNN实例重复使用的调试经验。
人不可能两次踩进同一个坑,如果发生了,那我是真的菜!
ValueError: Variable word_rnn/bidirectional_rnn/fw/cell_fw/kernel already exists, disallowed. Did you mean to set reuse=True or reuse=tf.AUTO_REUSE in VarScope? Originally defined at:
想用一个for循环改变batch_size,epochs等参数来看看其对实验结果的影响,但问题应该是循环的时候用的是同一个RNN,那么就没有重新训练的效果,程序也会报错,所以每次循环开始前都要重置RNN
在用tensorflow前加入这一句,重置作用
tf.reset_default_graph()
(至于如果要同时训练多个RNN模型,可能也会有这种错误,遇到时再debug吧)
CUDA,cuDNN,tensorflow,tensorflow-gpu版本问题
我用的是CUDA 10.0,cuDNN 7.4.1,Ubuntu查看命令如下:
查看CUDA版本:
cat /usr/local/cuda/version.txt
查看cuDNN版本:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
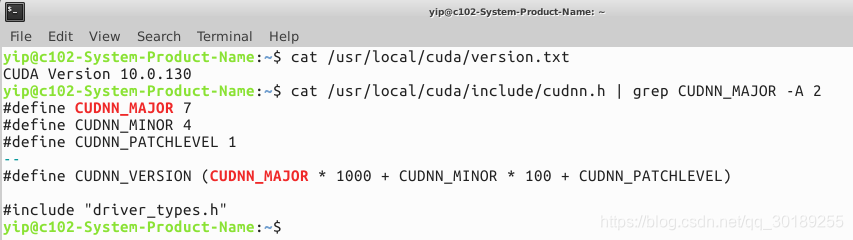
一定要找到这两个版本对应的tensorflow-gpu版本,不然用不了gpu
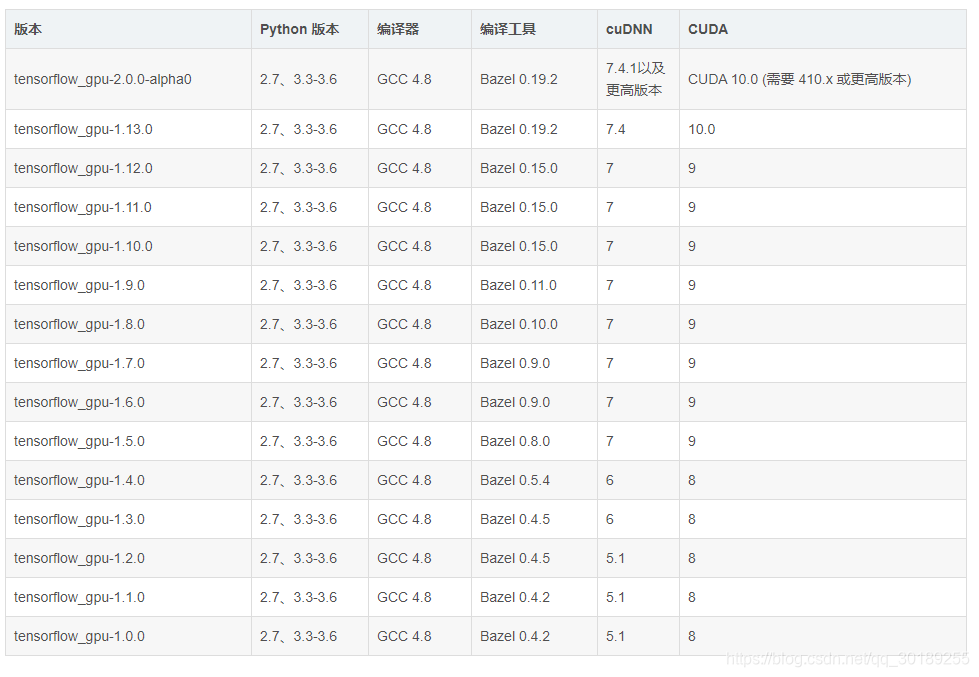
所以我对应的tensorflow-gpu版本用的是1.13.0的,但是现在好像没有1.13.0了,所以我用了1.13.1
用以下命令安装:
sudo pip install -i http://mirrors.aliyun.com/pypi/simple tensorflow-gpu==1.13.1
(用阿里镜像会快很多,因为tensorflow-gpu的库有300+M,阿里下载速度能上10M,我用其他镜像只有几十KB)
下载好之后测试能不能使用gpu
import tensorflow as tf
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
ps:下载了tensorflow-gpu就可以把tensorflow给卸载掉了,然后调用的时候直接写
import tensorflow as tf
程序会自动识别的,还有就是卸载之后可能出现没有成功调用到包,大概是路径问题,解决起来很烦,找到一个最快的方法是增加多一个解析环境,等包传过去就可以了

tensorflow使用GPU
在import后面加入这一句
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # choose GPU 0
如果要使用两块
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" # choose GPU 0
然后看一下GPU使用情况,美滋滋
watch -n 1 nvidia-smi


















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









