







文章目录
1.背景
最近在研究翻译模型中,小数据集的问题,看了几篇有代表性的文章,因此分享一下。
总所周知,一个成功的翻译模型,需要大量的语料,让模型能够有效学习到两个语种之间的内在联系。但针对小数据集的翻译模型,除了数据集过少导致模型不能够提取重要特征之外,还使得模型在效果降低,不能成熟应用到工业界中。
前人的这个小数据集的问题,包括了以下几种方法:
- 迁移学习
- 对偶学习
- Meta-Learning(元学习)
- 多任务学习
下文,分别介绍几种方法中的代表性论文。
2. 迁移学习
2.1《Transfer Learning for Low-Resource Neural Machine Translation》

- 以X和Y的翻译任务为例,首先训练X和Z之间的NMT模型,之后在训练X和Y的翻译模型。
- 预先在high-resource语言上进行训练,然后在迁移到low-resource中进行训练
NMT模型通常比串到树统计模型(string-to-tree statistical MT)要好。
论文主要的方法为:首先利用高资源的数据集,训练一个parent model,然后利用这个parent模型,初始化约束训练低资源的数据集。French-English 作为parent model,其他语言作为child model进行训练。
在大量双语数据上训练的父模型可以被认为是一个锚点,作为模型空间中的先验分布的峰值。在法语-英语到乌兹别克语-英语的例子中,作为初始化的结果,来自父模型的英语embedding被复制,但乌兹别克语词最初被映射到随机法语embeddings。
2.1.1 实验
parent model:French-English
child model:Hausa-English,Turkish-English,Uzbek-English,Urdu-English

- SBMT:string-to-tree static model
- NMT:随机初始化训练
- Xfer:使用迁移学习方法
- Final:迁移学习+集成学习
从实验结果来看,加入迁移学习后,每个NMT任务都有所提升。
更换parent后发现,French-English对Spanish-English效果最好,这是因为French和Spanish是相似的语言:

3. 对偶学习
《Dual Learning for Machine Translation》
- 机器翻译涉及到两个互为对偶的任务,比如从中文到英文和从英文到中文的翻译
4. Meta-Learning(元学习)
《Meta-Learning for Low-Resource Neural Machine Translation》
- few-shot在NMT任务上的应用,通过构造C-Way K-shot。会在训练集中随机抽取 C 个类别,
- 每个类别 K 个样本(总共 CK 个数据),构建一个 meta-task
5.多任务学习
5.1 《Multi-task sequence to sequence learning》
这篇文章主要介绍是那种不同的multi-task learning(MTL)多任务学习方法
- 一对多:在多个任务上,encoder参数是共享的
- 多对1,decoder被共享参数,比如在翻译和图片主题任务上
- 多对多,多个encoder和decoder被贡献,通常用在无监督目标和翻译任务
论文中还探索了两个无监督任务:序列自编码、skip-thought vectors
5.1.2 具体任务
-
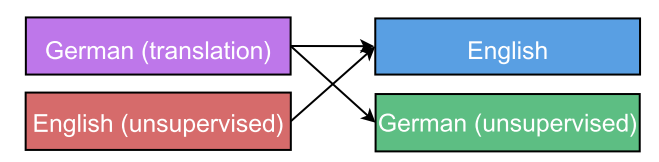
一对多任务:一个encoder,多个decoders。其中encoder的参数是共享的,如下图:

encoder的输入是English 单词输入。decoder有三个:语法解析,德语翻译,英文自编码 -
多对一任务:多个encoder,一个decoder进行共享参数

此外,从机器翻译的角度来看,这种设置可以受益于目标端的大量单语数据,这是机器翻译系统中的标准做法。 -
多对多任务:多个encoder和多个decoder
5.1.3 无监督学习任务
autoencoders:自编码模型,使输出能够还原为输入
skip-thought vectors: 这种无监督任务,最开始应用于有序句子之间进行预测,也既是段落里预测下一个句子。由于翻译任务中,不存在段落结构,因此论文中把每个句子分成两部分,使用一半句子来预测下一半句子。
5.1.4 学习过程
实验中,采用混合比例
α
i
\alpha_i
αi,来定义更新哪个任务,每个任务都是独立更新的。
比如有三个任务,他们被选择的概率为
α
1
,
α
2
,
α
3
\alpha_1,\alpha_2,\alpha_3
α1,α2,α3,这个值表征更新该任务参数的概率。
5.1.5 实验结果
一对多任务中:

- 翻译任务的 α = 1.0 \alpha=1.0 α=1.0,当PTB解析任务的 α = 0.1 \alpha=0.1 α=0.1,则说明每训练100次翻译任务,则有1次训练PTB解析任务。
- 从实验中看,当PTB解析任务的 α = 0.1 \alpha=0.1 α=0.1时,两个任务的效果都有所提升。
无监督多任务学习:

- skip-thought任务会比自编码任务取得更好的效果
- 作者认为:
(a)理想的目标应该与重点关注的监督任务兼容,例如,自动编码器可以被视为一种特殊情况 翻译任务
(b)使用更多无监督数据,内在和外在指标都可以得到有效的改进;
















 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











