







1. 背景
论文主要在无监督翻译任务上使用Meta-learning,在学习多个任务时,使得模型能够获取到通用的参数特征。
Meta-learning在高资源的数据领域上进行学习,从而能够提升模型在低资源数据领域的表现。Meta-learning的具体算法可以参考我之前写的文章:
2.引言
以前的无监督翻译模型,在低资源的数据集上表现不好。因此这些模型往往会先在高资源数据集上进行学习,然后再到低资源数据集上进行预测。但一些研究表明,高资源数据集有一些是不通用的,学习这些领域对低资源翻译没有准确率的提高
另一种常用的方法是迁移学习,然而,由于少量的训练数据和大的领域差距,这种方法可能会遭受过度拟合和灾难性遗忘知识的出现。
最近一个新出现的方法被称为meta-learning(元学习),在大量学习不同任务的同时,能够学到通用的领域知识。在无监督模型中使用meta-leanring方法,比在有监督模型使用meta-learning要更好,因为它能够定义多个不同的无标签任务。
因此这篇文章主要提出了两个模型:meta-learning unsupervised neural machine(MetaUMT)、MetaGUMT。
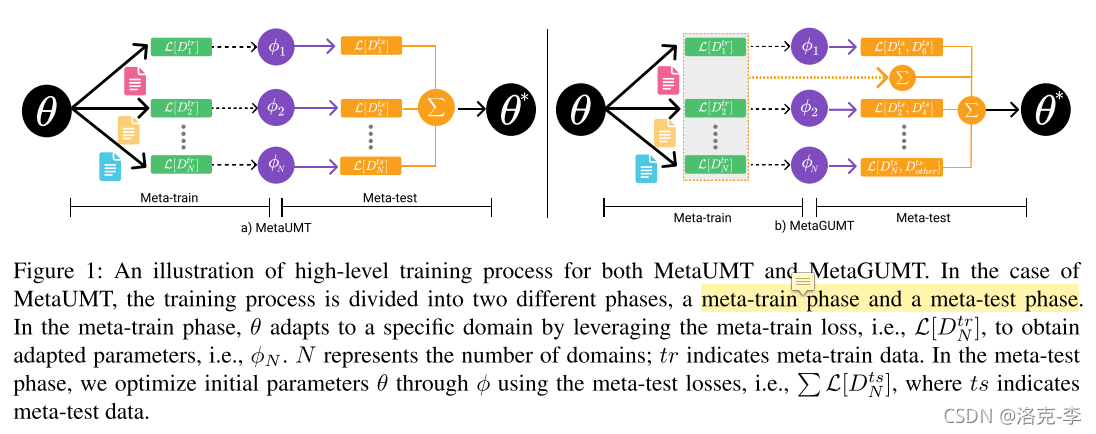
-
MetaUMT:主要是找到模型的最佳参数,来快速适应一个新的领域。如图上所示,分为meta-train,和meta-test阶段,其中meta-train使用了gradient by gradient,meta-test相当于预训练的fine-tuning阶段。
-
MetaGUMT:作者分析meta-test阶段,MetaUMT优化的参数是使用自适应参数,但是它抛弃了在不同任务上meta-train训练的参数,因此提出了新的训练方式。MetaGUMT在meta-test阶段,充分使用了不同任务的loss。这不仅鼓励模型去发现最佳的参数来快速适应目标领域,同时也鼓励其维持所有任务的公共知识:比如限定词、连词和代词,这些知识是用来适应多个不同的领域的。从下文不难发现,本质上就是结合了多个loss函数。
3.翻译模型中:无监督学习方法
主要分为两个不同的步骤:初始化(initialization),语言模型(language modeling),反向翻译(back-translation)。
首先定义了以下符号:
- S S S:源数据集
- T T T:目标数据集
- M s → s M_{s \to s} Ms→s、 M t → t M_{t \to t} Mt→t:源到源,目标到目标,也即是自编码
- - M s → t M_{s \to t} Ms→t、 M t → s M_{t \to s} Mt→s:源到目标,目标到源,也即是翻译
(1)初始化(initialization)
在无监督模型中,每个任务都是基于共享的encoder和decoder参数,所以初始化encoder和decoder是比较重要的。典型的有XLM模型等等。
(2)语言模型(language modeling)
使用denoising autoencoder(降噪自编码)来训练无监督模型。目标函数有两个:
M
s
→
s
M_{s \to s}
Ms→s、
M
t
→
t
M_{t \to t}
Mt→t的两个目标。
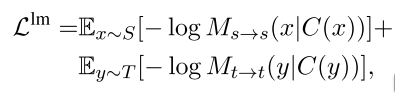
(3)反向翻译(back-translation)
也就是正常的翻译模型,从源数据集翻译成目标数据集。但是构造过程于有监督的翻译模型不一样。
首先需要从源句子中,推导出一个伪目标句子,得到
y
′
=
M
s
→
t
(
x
)
y'=M_{s \to t}(x)
y′=Ms→t(x)。这样会得到一个伪对
(
x
,
y
′
)
(x,y')
(x,y′)。同理也可以得到
(
x
′
,
y
)
(x',y)
(x′,y)。用伪句子对来进行训练。目标函数如下:
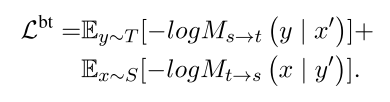
4.模型
首先把源数据集
D
o
u
t
D_{out}
Dout分割成多个领域数据集
D
o
u
t
=
{
D
o
u
t
1
,
D
o
u
t
2
,
.
.
.
,
D
o
u
t
n
}
D_{out}=\{D^1_{out},D^2_{out},...,D^n_{out}\}
Dout={Dout1,Dout2,...,Doutn}。
同理也可以把目标数据集 D i n D_{in} Din分割成多个领域数据集 D i n = { D i n 1 , D i n 2 , . . . , D i n n } D_{in}=\{D^1_{in},D^2_{in},...,D^n_{in}\} Din={Din1,Din2,...,Dinn}。
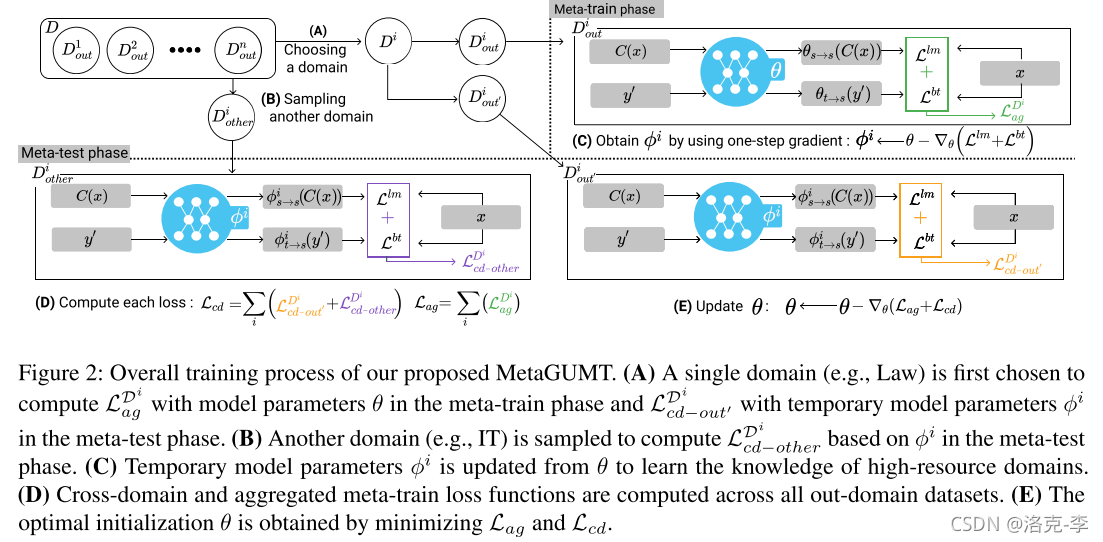
首先分析MetaUMT模型:
-
meta-train阶段:利用一步梯度(one-step gradient)更新每个任务的参数 ϕ i \phi^i ϕi,这部分用到的是上面提到的自编码损失函数 L l m L^{lm} Llm和反向翻译的损失函数 L b t L^{bt} Lbt。
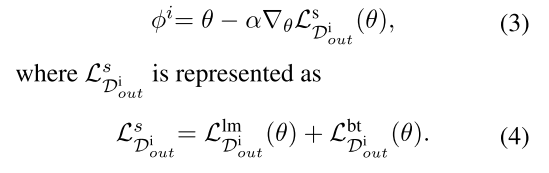
-
meta-test阶段:使用不同任务来更新meta模型的参数 θ \theta θ,这里的损失函数和上面的构造一样,包含自编码损失函数 L l m L^{lm} Llm和反向翻译的损失函数 L b t L^{bt} Lbt:
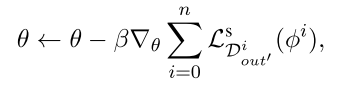
再分析MetaGUMT模型: -
meta-train阶段:和上面MetaUMT模型的一样
-
meta-test阶段:新增加了一个其他领域的损失函数,作者称为cross-domain loss,也即是把其他领域任务的loss函数来过来一起更新:
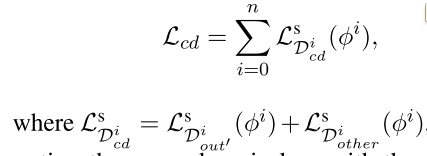
5.实验结果

- epoch表明模型的收敛迭代次数,可以看到MetaGUMT模型的收敛次数要明显少于其他模型。
- 实验中,每次区分了三个领域进行训练,在效果上也比其他模型要好
参考文章
- 从代码上解析Meta-learning
- 《Unsupervised Neural Machine Translation for Low-Resource Domains via Meta-Learning
Cheonbok》


















 869
869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











