






学习安装hadoop
环境:
hadoop3.1.3
jdk1.8
CentOS7 2009
集群版为一主两从
说在前面
本文档为本人笔记备份,难免会有很多缺失、错误,如有疏漏请指出,见谅
day01
准备工作
- 下载centos7镜像、hadoop3.1.3、jdk1.8
- VMware安装、开启虚拟化
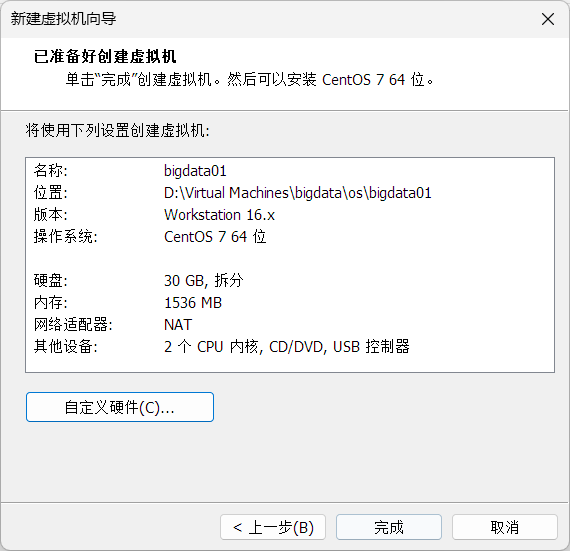
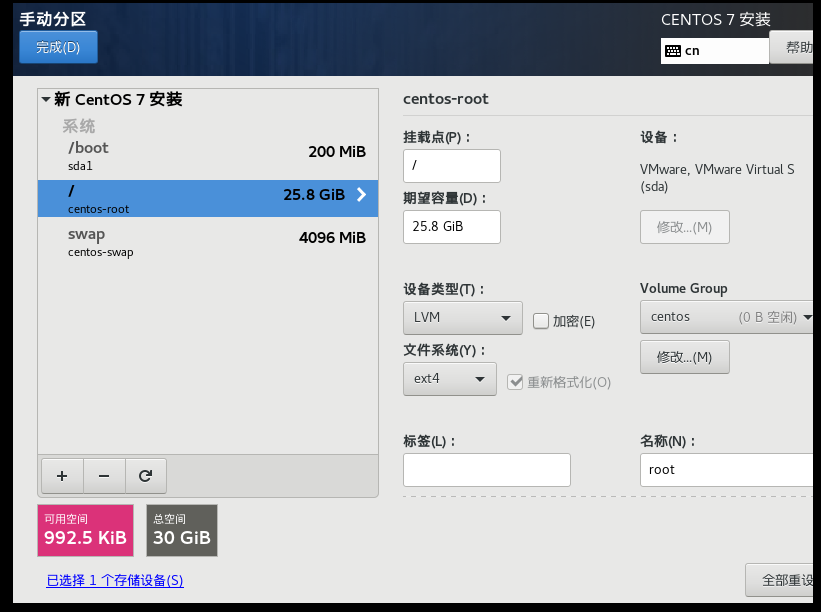
虚拟机安装centos7
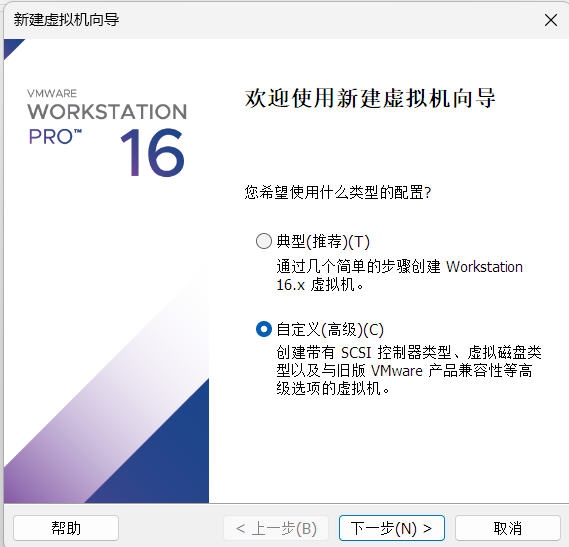
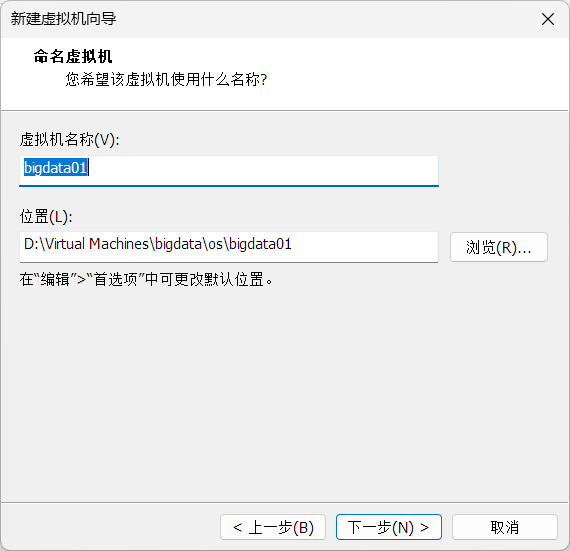
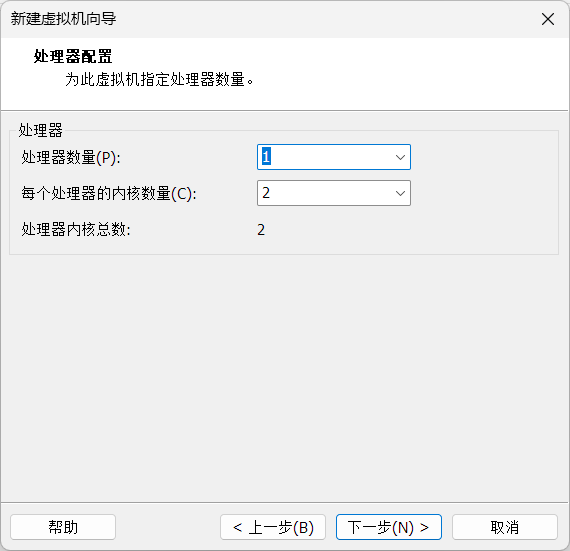
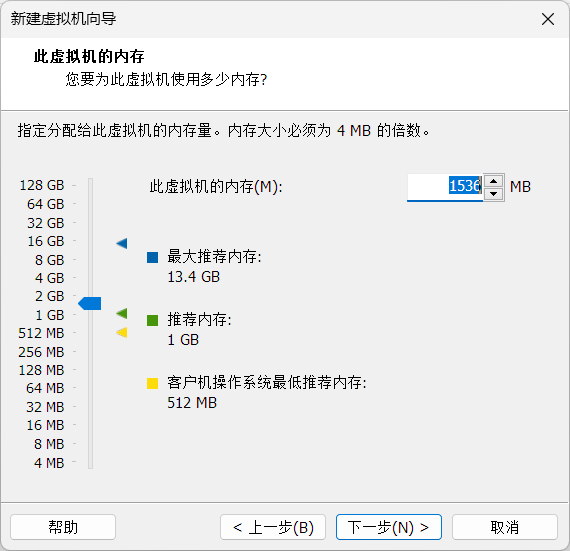
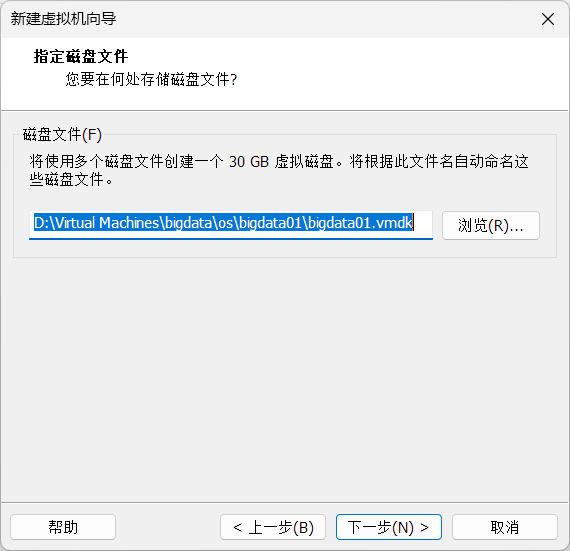
配置虚拟机网络
注意这里第三位189最好改成自己ip的第三位(后面会复制成三个虚拟机的集群,一开始设置好是同一个网段就行)
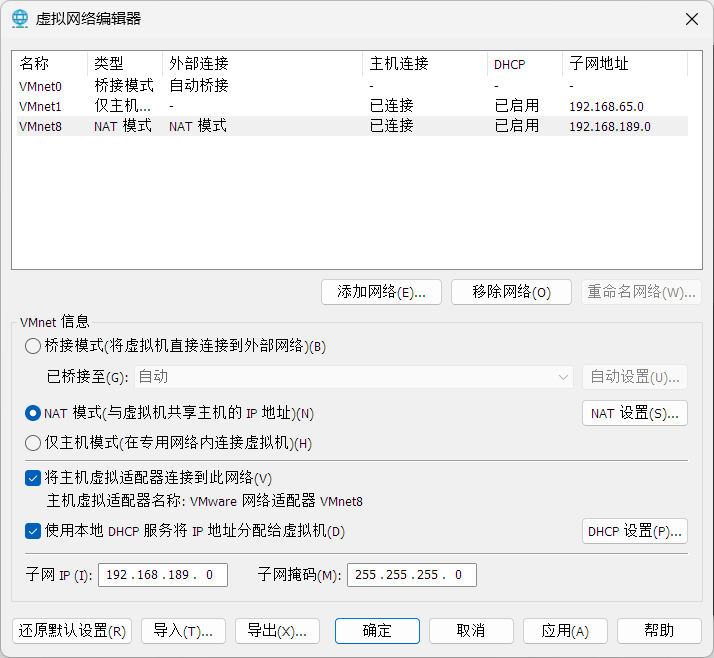
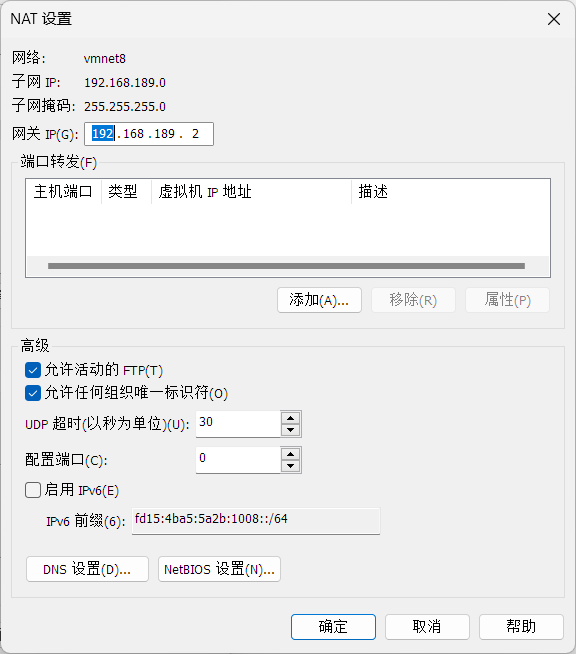
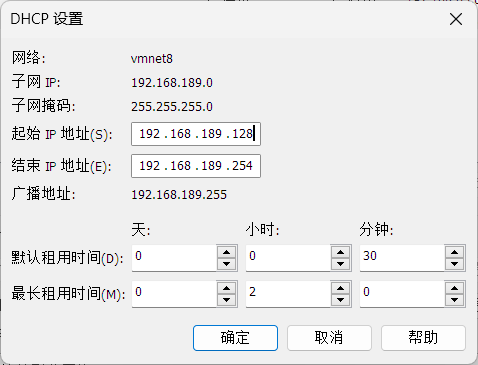
配置VMnet8虚拟网卡
这里的网卡ip的网段也和上面一样
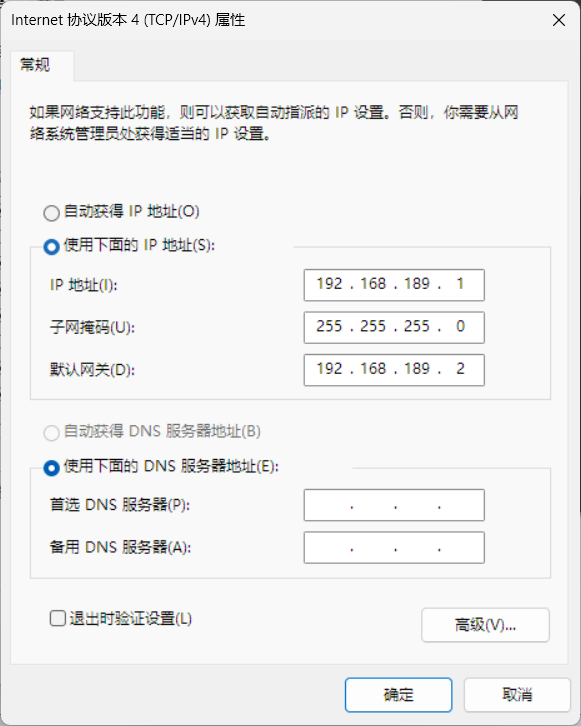
centos安装配置
打开网卡开关
安装完成
固定ip
-
在ifcfg-ens33文件中添加修改以下内容
vi /etc/sysconfig/network-scripts/ifcfg-ens33注意这里我把网段改成239了,实际上应该和上面是同一个网段(189)BOOTPROTO=static ONBOOT=yes IPADDR=192.168.239.70 NETMASK=255.255.255.0 GATEWAY=192.168.239.2 DNS1=8.8.8.8 DNS2=119.29.29.29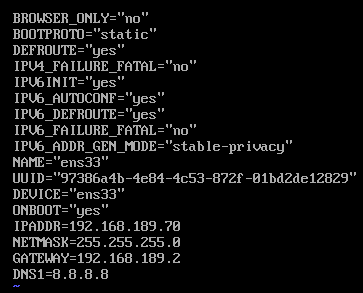
-
查看文件中的内容
cat /etc/sysconfig/network-scripts/ifcfg-ens33 -
重启网络服务
service network restart -
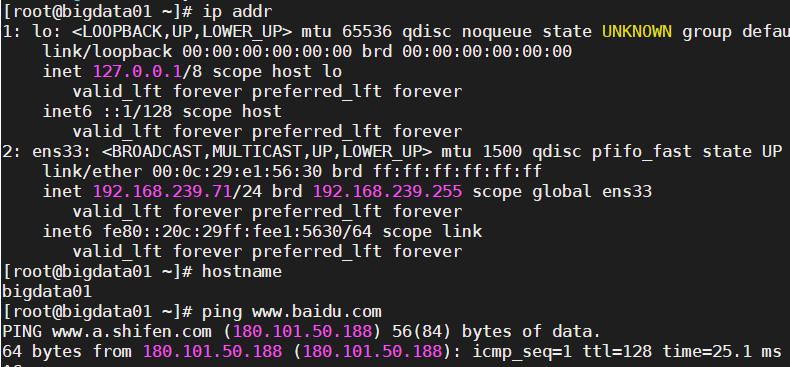
使用ping命令访问百度
ping www.baidu.com
day02
关闭NetworkManager服务、防火墙
-
查询当前虚拟机的ip地址(查看ens33中的inet)
ip addr -
关闭NetworkManager服务(只针对本次虚拟机运行时有效)
service NetworkManager stop -
禁用NetworkManager服务
chkconfig NetworkManager off -
禁用之后重启
service network restart -
查询修改当前虚拟机的主机名称
vi /etc/hostname #bigdata01 -
查询已执行的历史命令
history -
重启虚拟机
reboot -
查询、关闭、禁用防火墙
systemctl status firewalld systemctl stop firewalld systemctl disable firewalld
切换镜像
阿里源
首先是到yum源设置文件夹里
- 查看yum源信息:
yum repolist- 定位到base reop源位置
cd /etc/yum.repos.d- 下载wget
yum install -y wget- 接着备份旧的配置文件
mv CentOS-Base.repo CentOS-Base.repo.bak- 下载阿里源的文件
wget -O CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo- 清理缓存
yum clean all- 重新生成缓存
yum makecache- 再次查看yum源信息
yum repolist
-
安装必要的软件
yum install -y epel-release yum install -y net-tools yum install -y vim
同步时间
首先查看是不是东八区
date -R删除自带的localtime
rm -rf /etc/localtime创建软链接到localtime
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime安装ntpdate
yum install -y ntpdate同步北京时间
ntpdate -u ntp.api.bz
ntpdate ntp1.aliyun.com
-
创建目录
mmkdir <目录>-
当前处于/opt目录中时,使用相对路径创建子目录
mkdir install_packages mkdir softs -
在任意目录下,可以使用绝对路径创建目录
mkdir /opt/install_packages mkdir /opt/softs
-
安装jdk8
-
传输压缩包到虚拟机中
-
解压命令
tar -zxvf jdk-8u111-linux-x64.tar.gz -C <要解压到的位置> tar -zxvf jdk-8u111-linux-x64.tar.gz -C /opt/softs/z:操作类型是.tar.gz
x:解压操作
v:显示解压过程详情
f:指定文件名(要放在属性最后面)
C:指定要解压到的目录 -
移动、重命名命令
mv <要改名(移动)的文件目录> <重命名(移动)后的文件目录> # 最好用绝对路径 mv /opt/softs/jdk1.8.0_111/ /opt/softs/jdk1.8.0 -
配置环境变量
vim操作:G移动到最底部
vim /etc/profile #JAVA_HOME export JAVA_HOME=/opt/softs/jdk1.8.0 export PATH=$PATH:$JAVA_HOME/bin使环境变量立即生效
source /etc/profile验证JAVA_HOME路径
echo $JAVA_HOME
克隆虚拟机
修改hostname
bigdata01
修改ifcfg-ens33
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.239.71
完成后:
安装单机版hadoop3.1.3
-
传输压缩包到虚拟机
tar -zxvf hadoop-3.1.3.tar.gz mv hadoop-3.1.3/ /opt/softs/hadoop3.1.3/ -
编辑profile
#JAVA_HOME export JAVA_HOME=/opt/softs/jdk1.8.0 #HADOOP_HOME export HADOOP_HOME=/opt/softs/hadoop3.1.3 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
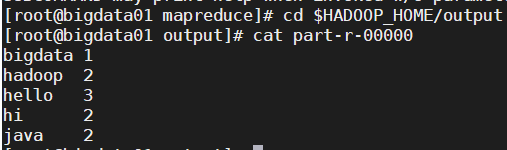
执行自带的exmaple计算txt中指定单词数
mkdir /opt/softs/hadoop3.1.3/input touch /opt/softs/hadoop3.1.3/input/words.txt cd $HADOOP_HOME/share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /opt/softs/hadoop3.1.3/input /opt/softs/hadoop3.1.3/outputwords.txt
hello java
hi bigdata hello hadoop
hi java
hello hadoop
day03
hadoop伪分布式配置
-
hadoop.env.sh
export JAVA_HOME=/opt/softs/jdk1.8.0 -
core-site.xml
<configuration> <!-- 指定NameNode的地址和端口 --> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata01:8020</value> </property> <!-- 指定hadoop数据的存储目录,该目录安装时不需要提前创建 --> <property> <name>hadoop.tmp.dir</name> <value>file:/opt/softs/hadoop3.1.3/data</value> </property> </configuration> -
hdfs-site.xml
<configuration> <!-- HDFS数据副本数 --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- namenode数据的存储目录 --> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/softs/hadoop3.1.3/data/dfs/name</value> </property> <!-- datanode数据的存储目录 --> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/softs/hadoop3.1.3/data/dfs/data</value> </property> </configuration> -
workers
# 删除localhost bigdata01 -
初始化namenode
hdfs namenode -format
-
想重新初始化
删除logs、data文件夹,重新执行初始化
-
启动hdfs
start-dfs.sh会显示报错没有配置以下文件路径:
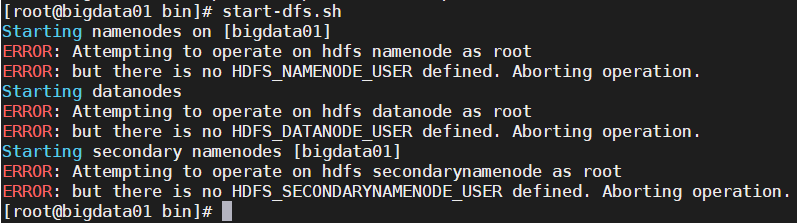
修改添加到/etc/profile
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root立即生效
source /etc/profile
配置ssh免密登录
cd ~/.ssh/
# 若没有该目录,先执行一次ssh localhost
# 生成免密登录的公钥和私钥
ssh-keygen -t rsa
# 会有提示,都按回车就可以
# 将公钥发送给需要免密登录的虚拟机上
ssh-copy-id bigdata01
# cat ./id_rsa.pub >> ./authorized_keys
配置主机名与ip映射
vim /etc/hosts
# 添加
192.168.239.71 bigdata01
测试
ssh localhost
#不提示输入密码即成功
-
启动hdfs
# 启动 start-dfs.sh # 关闭 stop-dfs.sh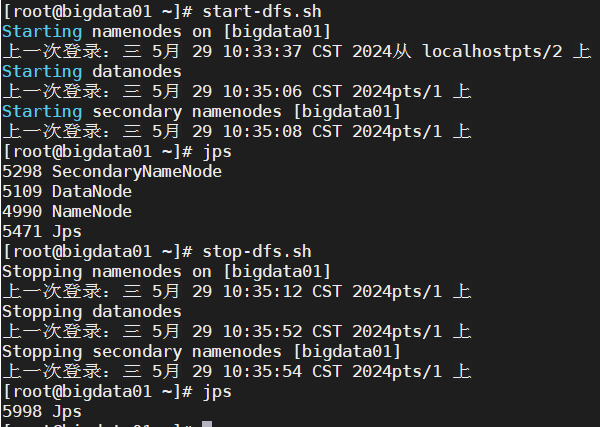
直接关机器而不提前关闭hdfs会进入保护模式
(话是这么说,好像我还没遇到过,应该是关机时没有在执行任务吧)
hadoop分布式配置
-
传输压缩包到虚拟机,修改文件夹名称
tar -zxvf hadoop-3.1.3.tar.gz mv hadoop-3.1.3/ /opt/softs/hadoop3.1.3/ -
编辑profile环境变量
#JAVA_HOME export JAVA_HOME=/opt/softs/jdk1.8.0 #HADOOP_HOME export HADOOP_HOME=/opt/softs/hadoop3.1.3 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 立即生效 source /etc/profile -
配置主机名与ip映射
vim /etc/hosts # 添加 192.168.239.71 bigdata01 192.168.239.72 bigdata02 192.168.239.73 bigdata03 -
将hosts配置发送到另外两台机器上
远程传输命令
scp <要远程传输的文件> <目标主机的用户名>@<目标主机的ip或hostname>:<文件远程传输的位置> scp /etc/hosts root@bigdata02:/etc/ -
ssh免密
cd ~/.ssh/ # 若没有该目录,先执行一次ssh localhost # 生成免密登录的公钥和私钥 ssh-keygen -t rsa # 会有提示,都按回车就可以 # 将公钥发送给需要免密登录的虚拟机上 ssh-copy-id bigdata02 ssh-copy-id bigdata03 # 在其他机器上重复该步骤 # cat ./id_rsa.pub >> ./authorized_keys -

-
集群规划时有两个注意点:
-
HDFS中的NameNode和SecondaryNameNode不要安装在同一个节点上
-
YARN中的ResourceManager不要和NameNode,SecondaryNameNode在同一个节点上
-
配置hadoop环境
-
hadoop.env.sh
export JAVA_HOME=/opt/softs/jdk1.8.0 -
core-site.xml
<configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata01:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/softs/hadoop3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为root --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration> -
hdfs-site.xml
<configuration> <!-- HDFS数据副本数 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- namenode数据的存储目录 --> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/softs/hadoop3.1.3/data/dfs/name</value> </property> <!-- datanode数据的存储目录 --> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/softs/hadoop3.1.3/data/dfs/data</value> </property> <!-- NameNode web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>bigdata01:9870</value> </property> <!-- SecondaryNameNode web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>bigdata02:9868</value> </property> </configuration> -
mapred-site.xml
<configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
yarn-site.xml
<!-- 指定mapreduce走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata03</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://bigdata03:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> -
workers
# 删除localhost bigdata01 bigdata02 bigdata03 -
传输目录到其他节点
scp -r <要远程传输的目录> <目标主机的用户名>@<目标主机的ip或hostname>:<文件远程传输的目录位置> scp -r /opt/softs/hadoop3.1.3/ root@bigdata02:/opt/softs/ scp -r /opt/softs/hadoop3.1.3/ root@bigdata03:/opt/softs/ -
格式化
hdfs namenode -format -
01节点启动hdfs
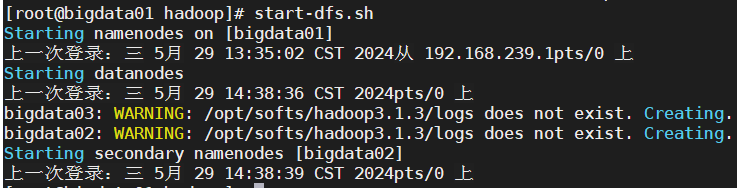
-
03节点启动yarn
先在每个节点的/etc/profile中添加
export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root启动完成
bigdata01 bigdata02 bigdata03 HDFS NameNode,DataNode SecondaryNameNode,DataNode DataNode YARN NodeManager NodeManager ResourceManager,NodeManager -
01节点
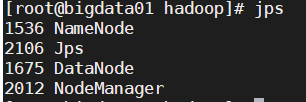
-
02节点
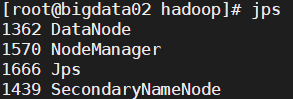
-
03节点
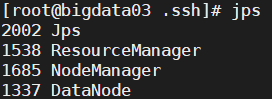
-
-
查看滚动日志
查看日志的最新500行
tail -500f <日志路径> tail -500f /opt/softs/hadoop3.1.3/logs/<要查看的log> -
最后关闭集群
# 03节点 stop-yarn.sh # 01节点 stop-dfs.sh #每个节点查看关闭情况 jps
day04
-
启动集群
# 01节点 start-dfs.sh # 03节点 start-yarn.sh # 03节点,开启任务历史服务 mapred --daemon start historyserver -
修改window中的hosts
# C:\Windows\System32\drivers\etc\hosts 192.168.239.71 bigdata01 192.168.239.72 bigdata02 192.168.239.73 bigdata03 -
访问Web服务
-
NameNode
bigdata01:9870
-
Yarn
bigdata03:8088
-
JobHistory
bigdata03:19888/jobhistory
-
HDFS命令行
命令行操作有两种格式:
hadoop fs -具体命令 要操作的目录/文件
hdfs dfs -具体命令 要操作的目录/文件
1. 对于目录的操作
1.1 对目录的查询
# 使用ls命令列出hdfs上的目录
# 查询hdfs上的根目录
hadoop fs -ls /
hdfs dfs -ls /
# 使用R参数进行递归查询,列出目标目录下的所有子目录
hdfs dfs -ls -R /
1.2 创建目录
# 使用mkdir命令创建目录
# 创建单级目录
hdfs dfs -mkdir /test
# 创建多级目录
hdfs dfs -mkdir -p /file/input
1.3 删除目录/文件
# 使用rm命令删除目录/文件
# 删除文件
hdfs dfs -rm /test
# r递归,目标目录下的子目录也会被删除
hdfs dfs -rm -r /file
2. 对于文件的操作
2.1 创建空白文件
# 使用touch或touchz命令创建空白文件
# 创建/file/touch.txt
hdfs dfs -touch /file/touch.txt
2.2 上传文件
# 使用put命令将本地linux文件上传到hdfs
hdfs dfs -put <本地文件路径> <hdfs路径>
# 将本地/opt/file/test.txt上传到hdfs的/file
hdfs dfs -put /opt/file/test.txt /file
# 使用moveFromLocal命令也可以将本地文件上传到hdfs上
# move会将文件移动到hdfs,本地不会保留,会被删除
# put不会删除本地文件
hdfs dfs -moveFromLocal <本地文件路径> <hdfs路径>
# 将本地/opt/file/a.txt上传到hdfs的/file
hdfs dfs -moveFromLocal /opt/file/a.txt /file
2.3 查看文件内容
# 使用cat命令可以查看hdfs上的文件内容
hdfs dfs -cat <hdfs中的文件路径>
# 查看hdfs中/file/test.txt文件中的内容
hdfs dfs -cat /file/test.txt
# cat命令可以查看多个文件中的内容
# 展示的内容会合并在一起
hdfs dfs -cat /file/test.txt /file/a.txt
2.4 下载文件
# 使用get命令可以将hdfs上的文件下载到本地linux
hdfs dfs -get <hdfs中的文件路径> <要下载到的本地路径>
# 将hdfs中/file/a.txt 下载到本地的/opt目录下
hdfs dfs -get /file/a.txt /opt
2.5 文件的改名和目录调整
# 使用cp命令可以将hdfs上的文件拷贝复制到其他hdfs目录中,在复制过程中可以修改文件名,拷贝完成后,文件在源路径中依然保留
hdfs dfs -cp <文件在hdfs上的源路径> <文件在hdfs上的新路径>
# 将/file/a.txt复制到/b.txt
hdfs dfs -cp /file/a.txt /b.txt
# 使用mv命令可以将hdfs上的文件剪切移动到其他hdfs目录中,在剪切过程中可以修改文件名,移动完成后,文件在源路径中会被删除
hdfs dfs -mv <文件在hdfs上的源路径> <文件在hdfs上的新路径>
# 将/file/test.txt移动到/test1.txt
hdfs dfs -mv /file/test.txt /test1.txt
2.6 对文件的赋权
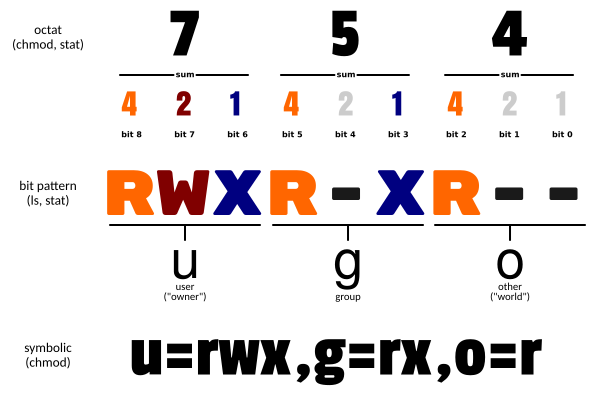
-
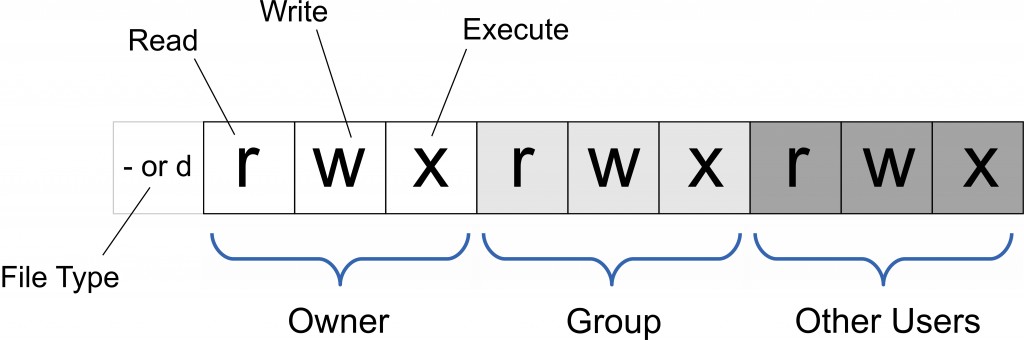
linux中文件权限管理
drwxr-xr-x. 2 root root 4096 5月 30 15:08 file
-rw-r–r–. 1 root root 35 5月 30 15:01 test.txt
rw-r–r–
-
rw-:代表test.txt文件所属用户root对该文件的权限
- r:read,有查看访问权限
- w:write,有写权限
-
r–:代表test.txt文件所在用户组root对该文件的权限
- r:read,有查看访问权限
-
r–:代表其他用户对该文件的权限
- r:read,有查看访问权限
-
-
对文件的权限进行修改
# 使用chmod命令对文件或目录进行权限控制 r:4 w:2 x:1 rw-r--r--: 644 # 调整a.txt的权限 让所有用户对a.txt拥有读写权限 chmod 666 /opt/a.txt -rw-rw-rw-. 1 root root 23 5月 30 21:41 a.txt # 调整a.txt的权限 让所有用户对a.txt拥有读写执行权限 chmod 777 /opt/a.txt -rwxrwxrwx. 1 root root 23 5月 30 21:41 a.txt
-
hdfs中文件目录权限控制
当前/file/a.txt权限为644

修改成777
hdfs dfs -chmod 777 /file/a.txt

3. 判断操作
# 使用test命令进行判断操作
3.1 判断文件目录是否存在于hdfs
hdfs dfs -test -e /file/a.txt
# 获取返回值
# 0是正常返回结果,文件存在;1文件不存在
echo $?
3.2 判断是否为目录
hdfs dfs -test -d /file/a.txt
echo $?
3.3 判断文件是否为空
hdfs dfs -test -z /file/a.txt
# 0内容为空,1不为空或文件目录不存在
echo $?
4. 其他操作
手动关闭保护模式
hadoop dfsadmin -safemode leave
作业
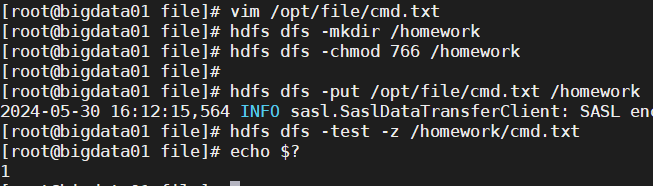
在linux本地创建/opt/file/cmd.txt文件,文件中的内容自定义
在hdfs上创建目录/homework,将该目录的权限调整为root用户拥有读写执行权限 其他用户拥有读写权限
将/opt/file/cmd.txt上传到/homework下,并判断该文件是否为空
vim /opt/file/cmd.txt
hdfs dfs -mkdir /homework
hdfs dfs -chmod 766 /homework
hdfs dfs -put /opt/file/cmd.txt /homework
hdfs dfs -test -z /homework/cmd.txt
echo $?

day05
配置win hadoop
1. 将linux中的hadoop3.1.3下载到win
删除share再下,能节省很多时间
2. 替换bin下的可执行文件
替换后,复制hadoop.dll到C:\Windows\System32下
双击winutils.exe,若窗口一闪而过就没什么问题
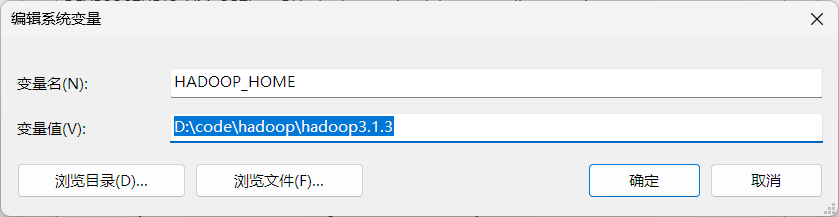
3. 配置环境变量
HADOOP_HOME:D:\code\hadoop\hadoop3.1.3
JAVA_HOME:E:\Java\jdk1.8.0_301

<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
-
附:maven配置本地仓库、阿里云镜像
<!-- D:\code\maven\apache-maven-3.9.7\conf\setting.xml --> <!-- 配置本地仓库 --> <localRepository>D:\code\maven\repository</localRepository> <!-- 配置阿里云镜像 --> <mirrors> <mirror> <id>aliyunmaven</id> <mirrorOf>central</mirrorOf> <name>阿里云公共仓库</name> <url>https://maven.aliyun.com/repository/central</url> </mirror> <mirror> <id>repo1</id> <mirrorOf>central</mirrorOf> <name>central repo</name> <url>http://repo1.maven.org/maven2/</url> </mirror> <mirror> <id>aliyunmaven</id> <mirrorOf>apache snapshots</mirrorOf> <name>阿里云阿帕奇仓库</name> <url>https://maven.aliyun.com/repository/apache-snapshots</url> </mirror> </mirrors>
HDFS Java部分API
package com.edu.just.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.fs.permission.FsPermission;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
// 调用hdfs的API
public class HdfsApiClient {
// 文件系统操作
FileSystem fileSystem = null;
// 初始化hdfs文件系统
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 创建文件系统配置
Configuration conf = new Configuration();
// 创建文件系统对象
fileSystem = FileSystem.get(new URI("hdfs://bigdata01:8020"), conf, "root");
System.out.println("hdfs文件系统初始化完成");
}
// 创建hdfs目录
@Test
public void createPath() throws IOException {
boolean result = fileSystem.mkdirs(new Path("/hdfs_api"));
if (result) {
System.out.println("目录创建成功");
} else {
System.out.println("目录创建失败");
}
}
// 删除hdfs目录
@Test
public void deletePath() throws IOException {
Path deletePath = new Path("/hdfs_api");
// 判断hdfs上是否存在该目录
if (fileSystem.exists(deletePath)) {
// 目录存在
// 参数1:要删除的路径 参数2:是否递归子目录
boolean result = fileSystem.delete(deletePath, false);
System.out.println(result ? "删除目录成功" : "删除目录失败");
} else {
System.out.println("将删除目录不存在");
}
}
// 在hdfs上创建一个文件并写入指定内容
@Test
public void createHdfsFile() throws IOException {
// 获取数据输出流
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/api_file.txt"));
// 定义输出的文件内容
String line = "hello bigdata";
// 将指定内容写入文件
fsDataOutputStream.write(line.getBytes());
// 对数据输出流对象进行刷新
fsDataOutputStream.flush();
// 关闭输出流对象
fsDataOutputStream.close();
}
// 对hdfs上的文件修改其路径和名称
@Test
public void moveHdfsFile() throws IOException {
Path src = new Path("/api_file.txt");
Path dst = new Path("/hdfs_api/api_file_new.txt");
boolean rename = fileSystem.rename(src, dst);
System.out.println(rename ? "重命名/移动成功" : "重命名/移动失败");
}
// 读取hdfs上的文件内容
@Test
public void readHdfsFile() throws IOException {
// 获取数据输入流对象
FSDataInputStream fsDataInputStream = fileSystem.open(new Path("/hdfs_api/api_file_new.txt"));
// 通过IO工具类读取hdfs文件中的内容
// System.out代表的是PrintStream对象,该对象是OutputStream类的间接子类
IOUtils.copyBytes(fsDataInputStream, System.out, 2048, false);
// 手动换行
System.out.println();
}
// 从本地上传文件到hdfs上
@Test
public void uploadFile() throws IOException {
// 文件本地路径
Path src = new Path("D:\\code\\hadoop\\words.txt");
// hdfs中的文件路径
Path dst = new Path("/hdfs_api");
// 文件上传成功后,是否删除本地文件(默认不删除)
boolean delSrc = false;
// 是否覆盖hdfs中的文件(默认覆盖)
boolean overWrite = true;
fileSystem.copyFromLocalFile(delSrc, overWrite, src, dst);
}
// 从hdfs上下载到文件系统
@Test
public void downloadFile() throws IOException {
// hdfs中的文件路径
Path src = new Path("/hdfs_api/api_file_new.txt");
// 下载后本地将保存的路径
Path dst = new Path("D:\\code\\hadoop\\api_file_new.txt");
// 是否删除hdfs中的源文件
boolean delSrc = false;
// true:下载的文件不会存在crc校验文件
boolean useRawLocalFileSystem = true;
fileSystem.copyToLocalFile(delSrc, src, dst, useRawLocalFileSystem);
}
// 查看hdfs上的文件信息
@Test
public void queryHdfsFileInfo() throws IOException {
// 查询的起始路径
Path path = new Path("/");
// 获取迭代器
RemoteIterator<LocatedFileStatus> listIterator = fileSystem.listFiles(path, true);
// 进行遍历
// 判断迭代器中是否还有需要迭代的元素
while (listIterator.hasNext()) {
// 获取迭代器中需要迭代的元素
LocatedFileStatus fileStatus = listIterator.next();
// 获取文件的路径
Path filePath = fileStatus.getPath();
System.out.println("文件的路径是:" + filePath);
// 获取文件的权限
FsPermission permission = fileStatus.getPermission();
System.out.println("文件的权限是:" + permission);
// 获取文件的所属用户
String owner = fileStatus.getOwner();
System.out.println("文件的所属用户是:" + owner);
// 获取文件的所属用户的用户组
String group = fileStatus.getGroup();
System.out.println("文件所属用户的用户组是:" + group);
// 获取文件的副本数
short replication = fileStatus.getReplication();
System.out.println("文件的副本数是:" + replication);
// 获取文件的块大小
long blockSize = fileStatus.getBlockSize();
System.out.println("文件的块大小是:" + blockSize / 1024 / 1024 + "MB");
System.out.println("-------------------------------------");
}
}
// 关闭文件系统对象
@After
public void close() throws IOException {
if (fileSystem != null) {
fileSystem.close();
System.out.println("hdfs文件系统已关闭");
}
}
}















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









