







 本文介绍了物流中心选址问题的数学模型,重点探讨了麻雀搜索算法,包括算法原理、角色分工和更新机制。提供了部分代码示例,展示了如何应用该算法寻找最优的物流中心配置。最后,概述了总算法优化的结果获取方式。
本文介绍了物流中心选址问题的数学模型,重点探讨了麻雀搜索算法,包括算法原理、角色分工和更新机制。提供了部分代码示例,展示了如何应用该算法寻找最优的物流中心配置。最后,概述了总算法优化的结果获取方式。
一、物流中心选址问题
物流中心选址问题模型。目标函数为物流中心到各备选点之间的距离与需求量乘积之和最小,据此,建立物流配送中心 的选址模型


二、麻雀搜索算法
1.算法介绍
麻雀搜索算法是近两年提出的新兴群智能优化算法,具备算法原理简单、收敛速度快等优势。该算法基于麻雀种群的社会行为将麻雀个体分为发现、加入者以及警戒者,发现者能力较强可以找到食物并为同类指明方向,公式为:
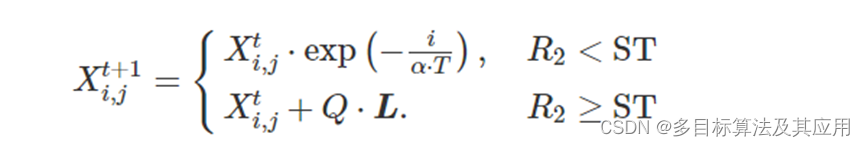
式中:t和T分别为算法当前以及最大更新次数,∝为随机数,其取值范围为1,1;Q同样为随机数,但服从正态分布;L为所有元素都是1的行短阵,其列数由待求解问题维度确定;R2为大于0小于1的预警值,ST为大于0.5小于1的安全值。
加入者则通过观察发现者的食物来源以便取而代之,公式为:
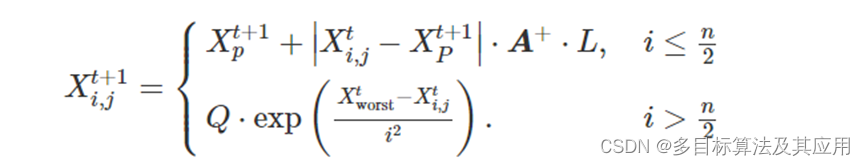
式中:Xp(t+1)为所有发现者中位置更新后的最佳位置;A+ = AT(AAT)-1其中,A为所有元素随机取值为1或-1的行矩阵,列数为求解问题维度;Xworst为当前种群中的最劣位置;n为种群中麻雀数量.
警戒者需要时刻留意当前环境,以便发现危险立即飞往安全环境。位置更新公式为:
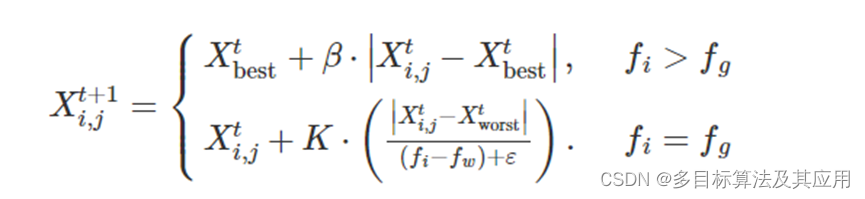
式中:Xbest为当前种群中的最佳位置;β为随机数且遵循标准正态分布;fi, fg, fw分别为目前个体、当前种群最优、最劣的适应度值;k在-1,1范围内随机取值,E的作用是防止分母为0.
2.部分代码
代码如下(示例):
clear all
clc
rng('default');
%% 载入数据
[data.node,data.node0,data.node1]=xlsread('节点经纬度.xlsx',1);
data.D1=xlsread('物流节点到需求点距离.xlsx',1);
data.D2=xlsread('物流节点到产地距离.xlsx',1);
data.demand=xlsread('需求.xlsx',1);
data.noC=find(data.node(:,3)==1);
data.noD=find(data.node(:,3)<3);
data.noP=find(data.node(:,3)==3);
data.numC=length(data.noC);
data.numD=length(data.noD);
data.numP=length(data.noP);
data.numSelected=6;
for i=1:data.numD
for j=1:data.numC
D=distance(data.node(data.noD(i),2),data.node(data.noD(i),1),data.node(data.noC(j),2),data.node(data.noC(j),1)); % distance看matlab help
pi=3.1415926;
dx=D*6371*2*pi/360;
data.D1(i,j)=dx;
%data.D1(i,j)=norm(data.node(data.noD(i),1:2)-data.node(data.noC(j),1:2));
end
end
for i=1:data.numC
for j=1:data.numP
D=distance(data.node(data.noC(i),2),data.node(data.noC(i),1),data.node(data.noP(j),2),data.node(data.noP(j),1)); % distance看matlab help
pi=3.1415926;
dx=D*6371*1000*2*pi/360;
data.D2(i,j)=dx;
%data.D2(i,j)=norm(data.node(data.noC(i),1:2)-data.node(data.noP(j),1:2))*1000;
end
end
data.maxLoad=760; %最大能力
data.alpha=0.5;
data.ck=245; %库存成本
data.ct1=0.19; %运输成本1
data.ct2=0.26; %运输成本2
data.cb=2.45; %可变成本
figure
hold on
plot(data.node(data.noC,1),data.node(data.noC,2),'rs','LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor','g',...
'MarkerSize',10)
plot(data.node(data.noD,1),data.node(data.noD,2),'ro','LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor','r',...
'MarkerSize',10)
plot(data.node(data.noP,1),data.node(data.noP,2),'rh','LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor','b',...
'MarkerSize',10)
dim=data.numC+data.numD;
%% 画图
%%
%% 测试函数
option.dim=dim;
lb = 0;
ub = 1;
fobj = @aimFcn_1;
%% 算法设置
% Function_name='F8'; % Name of the test function that can be from F1 to F23 (Table 1,2,3 in the paper) 设定适应度函数
SearchAgents_no=20; % Number of search agents 种群数量
Max_iteration=20;
% Load details of the selected benchmark function
% [lb,ub,dim,fobj]=Get_Functions_details(Function_name); %设定边界以及优化函数
[Best_pos,Best_score,SSA_curve]=SSANew(SearchAgents_no,Max_iteration,lb,ub,dim,fobj,option,data); %开始优化
figure
hold on
plot(SSA_curve,'LineWidth',2)
legend("SSA");
title('fitness curve')
data.color=[ 0.9088 0.0875 0.8788
0.5097 0.5402 0.4341
0.0462 0.9360 0.4905
0.1753 0.4868 0.5502
0.0677 0.9388 0.9625
0.1905 0.2479 0.5507
0.5309 0.0690 0.3477
0.0219 0.9636 0.9013
0.9846 0.6979 0.1700
0.0208 0.9444 0.1282
0.4795 0.4249 0.6089
0.2570 0.1933 0.0006
0.8181 0.9768 0.7858
0.0179 0.1955 0.1252]; %一行是一个颜色, 三原色,取值0-1之间
str='SSA'
[~,result1]= fobj(Best_pos,option,data);
drawPC(result1,data,str)
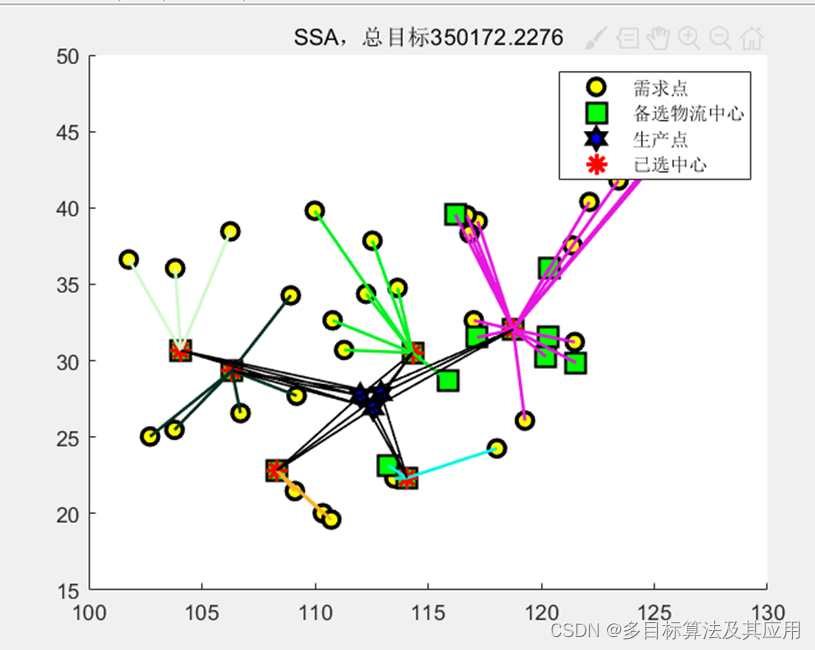
三、总算法优化结果















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









