







一、SSA-LSTM
长短期记忆网络的出现有效解决了长期依赖问题,但是在训练过程中,LSTM神经网络仍存在网络结构难以确定以及最优参数如何选择的问题。为了解决上述问题,本文利用SSA对LSTM进行优化,构建基于SSA的LSTM模型结构。
二、麻雀搜索算法
1.算法介绍
麻雀搜索算法是近两年提出的新兴群智能优化算法,具备算法原理简单、收敛速度快等优势。该算法基于麻雀种群的社会行为将麻雀个体分为发现、加入者以及警戒者,发现者能力较强可以找到食物并为同类指明方向,公式为:

式中:t和T分别为算法当前以及最大更新次数,∝为随机数,其取值范围为1,1;Q同样为随机数,但服从正态分布;L为所有元素都是1的行短阵,其列数由待求解问题维度确定;R2为大于0小于1的预警值,ST为大于0.5小于1的安全值。
加入者则通过观察发现者的食物来源以便取而代之,公式为:

式中:Xp(t+1)为所有发现者中位置更新后的最佳位置;A+ = AT(AAT)-1其中,A为所有元素随机取值为1或-1的行矩阵,列数为求解问题维度;Xworst为当前种群中的最劣位置;n为种群中麻雀数量.
警戒者需要时刻留意当前环境,以便发现危险立即飞往安全环境。位置更新公式为:

式中:Xbest为当前种群中的最佳位置;β为随机数且遵循标准正态分布;fi, fg, fw分别为目前个体、当前种群最优、最劣的适应度值;k在-1,1范围内随机取值,E的作用是防止分母为0.
2.部分代码
代码中包括了参数设置,提供数据以及如何讲代码中的数据更改为您自己的数据。
代码如下(示例):
clc;
clear
close all
%% 单一的LSTM预测
tic
disp('…………………………………………………………………………………………………………………………')
disp('单一的LSTM预测')
disp('…………………………………………………………………………………………………………………………')
geshu=200;%训练集的个数
%读取数据
data = xlsread('Data1.xlsx');
shuru = data(:,1:end-1);
shuchu = data(:, end);
nn = randperm(size(shuru,1));%随机排序
% nn=1:size(shuru,1);%正常排序
input_train =shuru(nn(1:geshu),:);
input_train=input_train';
output_train=shuchu(nn(1:geshu),:);
output_train=output_train';
input_test =shuru(nn((geshu+1):end),:);
input_test=input_test';
output_test=shuchu(nn((geshu+1):end),:);
output_test=output_test';
%样本输入输出数据归一化
[aa,bb]=mapminmax([input_train input_test]);
[cc,dd]=mapminmax([output_train output_test]);
[xTrain,inputps]=mapminmax('apply',input_train,bb);
[yTrain,outputps]=mapminmax('apply',output_train,dd);
%% 创建LSTM回归网络,序列预测,因此,输入24维,输出一维
numFeatures = size(xTrain,1);
numResponses = 1;
%% 基础LSTM测试
numHiddenUnits = 68;
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits)
fullyConnectedLayer(numResponses)
regressionLayer];
%指定训练选项
options = trainingOptions('adam', ...
'MaxEpochs',35, ...
'ExecutionEnvironment' ,'cpu',...
'GradientThreshold',1, ...
'InitialLearnRate',0.001, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',30, ...
'LearnRateDropFactor',0.2, ...%指定初始学习率 0.005,在 125 轮训练后通过乘以因子 0.2 来降低学习率
'L2Regularization',0.0001,...
'Verbose',0);
%训练LSTM
net = trainNetwork(xTrain,yTrain,layers,options);
net = resetState(net);% 网络的更新状态可能对分类产生了负面影响。重置网络状态并再次预测序列。
[~,Ytrain]= predictAndUpdateState(net,xTrain);
test_simu=mapminmax('reverse',Ytrain,dd);%反归一化
%测试集样本输入输出数据归一化
inputn_test=mapminmax('apply',input_test,bb);
[net,an]= predictAndUpdateState(net,inputn_test);
test_simu1=mapminmax('reverse',an,dd);%反归一化
error1=test_simu1-output_test;%测试集预测-真实
disp('')
disp('训练集误差指标:')
[mae1,rmse1,mape1,error1]=calc_error(output_train,test_simu);
fprintf('\n')
disp('测试集误差指标:')
[mae2,rmse2,mape2,error2]=calc_error(output_test,test_simu1);
fprintf('\n')
toc
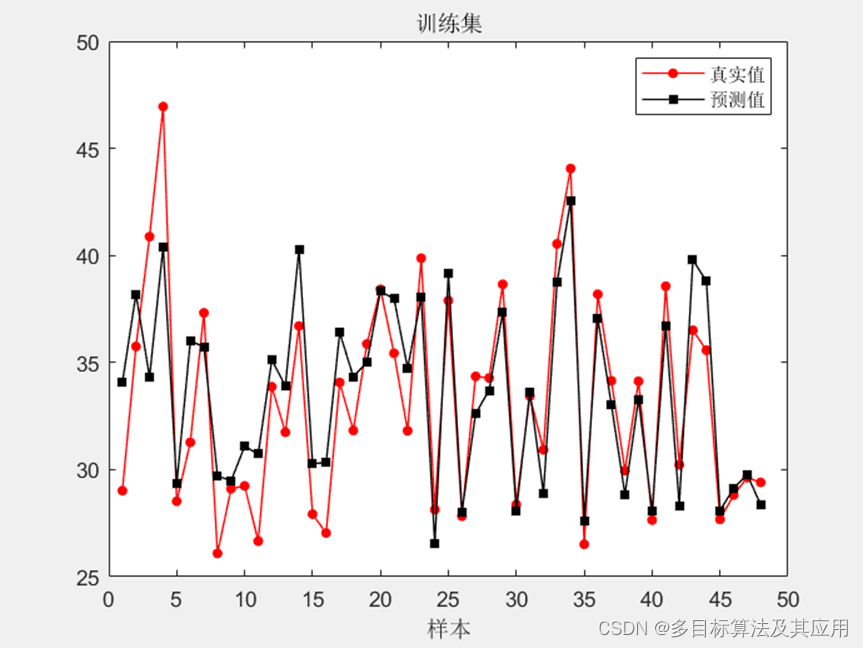
figure
plot(output_test,'r-o','Color',[255 0 0]./255,'linewidth',0.8,'Markersize',4,'MarkerFaceColor',[255 0 0]./255)
hold on
plot(test_simu1,'-s','Color',[0 0 0]./255,'linewidth',0.8,'Markersize',5,'MarkerFaceColor',[0 0 0]./255)
hold off
legend(["真实值" "预测值"])
xlabel("样本")
title("训练集")
%% VMD-SSA-LSTM预测
tic
disp('…………………………………………………………………………………………………………………………')
disp('VMD-SSA-LSTM预测')
disp('…………………………………………………………………………………………………………………………')
pop=10; % 麻雀数量
Max_iteration=20; % 最大迭代次数
dim=3; % 优化lstm的3个参数
lb = [40,40,0.001];%下边界
ub = [200,200,0.03];%上边界
fobj = @(x) fun(x,numFeatures,numResponses,xTrain,yTrain,input_test,output_test);
%基础麻雀算法
[Best_pos,Best_score,SSA_curve]=SSA(pop,Max_iteration,lb,ub,dim,fobj); %开始优化
%% 绘制进化曲线
figure
plot(SSA_curve,'r-','linewidth',3)
xlabel('进化代数')
ylabel('均方误差MSE')
legend('最佳适应度')
title('SSA-LSTM的进化收敛曲线')
disp('')
disp(['最优隐藏单元数目为 ',num2str(round(Best_pos(1)))]);
disp(['最优最大训练周期为 ',num2str(round(Best_pos(2)))]);
disp(['最优初始学习率为 ',num2str((Best_pos(3)))]);
disp(['最优L2正则化系数为 ',num2str((Best_pos(2)))]);
% SSA优化后的LSTM做预测 对每个分量建模
[xTest,inputps]=mapminmax('apply',input_test,bb);
[yTest,outputps]=mapminmax('apply',output_test,dd);
%% 创建LSTM回归网络,序列预测,因此,输入24维,输出一维
numFeatures = size(xTest,1);
numResponses = 1;
%% 基础LSTM测试
numHiddenUnits = round(Best_pos(1));
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits)
fullyConnectedLayer(numResponses)
regressionLayer];
%指定训练选项
options = trainingOptions('adam', ...
'MaxEpochs',round(Best_pos(2)), ...
'ExecutionEnvironment' ,'cpu',...
'GradientThreshold',1, ...
'InitialLearnRate',Best_pos(3), ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',round(0.8*Best_pos(2)), ...
'LearnRateDropFactor',0.2, ...%指定初始学习率 0.005,在 125 轮训练后通过乘以因子 0.2 来降低学习率
'L2Regularization',0.0001,...
'Verbose',0);
%训练LSTM
net = trainNetwork(xTrain,yTrain,layers,options);
%测试集测试
numTimeStepsTrain = size(xTest,2);
net = resetState(net);% 网络的更新状态可能对分类产生了负面影响。重置网络状态并再次预测序列。
[net,an] = predictAndUpdateState(net,xTest,'ExecutionEnvironment','cpu');
% 反归一化
test_simu2=mapminmax('reverse',an,dd);%反归一化
%% 模型测试集结果绘图对比
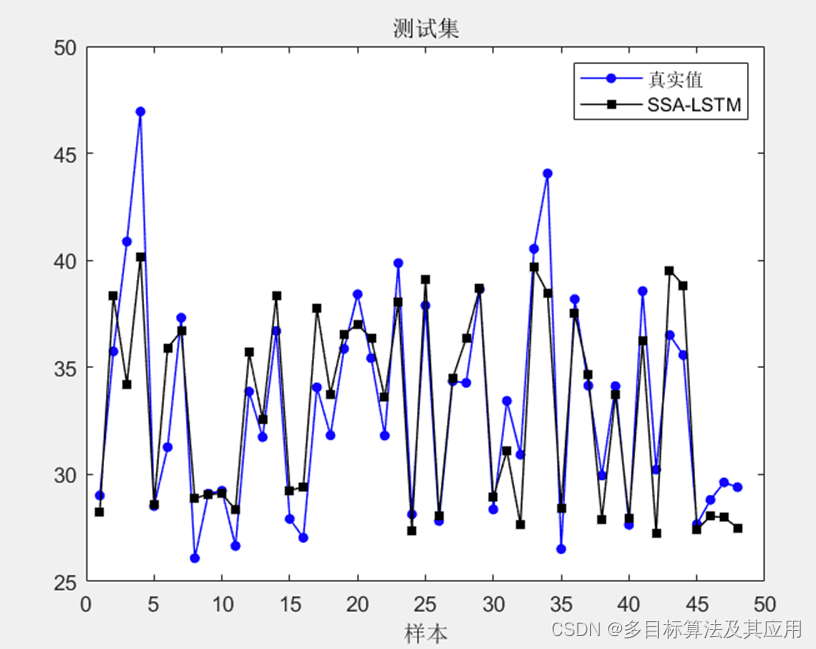
figure
plot(output_test,'-o','Color',[0 0 255]./255,'linewidth',0.8,'Markersize',4,'MarkerFaceColor',[25 0 255]./255)
hold on
plot(test_simu2,'-s','Color',[0 0 0]./255,'linewidth',0.8,'Markersize',5,'MarkerFaceColor',[0 0 0]./255)
hold off
legend(["真实值" "SSA-LSTM"])
xlabel("样本")
title("测试集")
disp('测试集误差指标:')
[mae2,rmse2,mape2,error2]=calc_error(output_test,test_simu2);
fprintf('\n')
三、总算法优化结果
原始LSTM:

改进后的SSA-LSTM:


















 4208
4208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









