






Ollama本地部署
Ollama下载网址:https://ollama.com/download
选择Download for Windows (Preview) 下载安装包:
安装成功后会出现命令行提示:
此时,在命令行中输入“ollama run [模型标准名称]”,即可运行模型,开始对话:
(如果是第一次运行,则会自动下载模型后运行)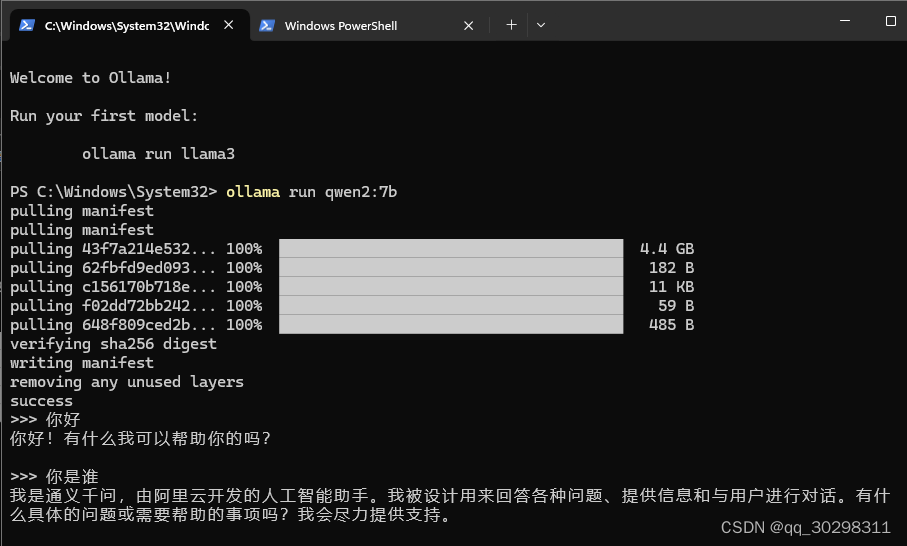
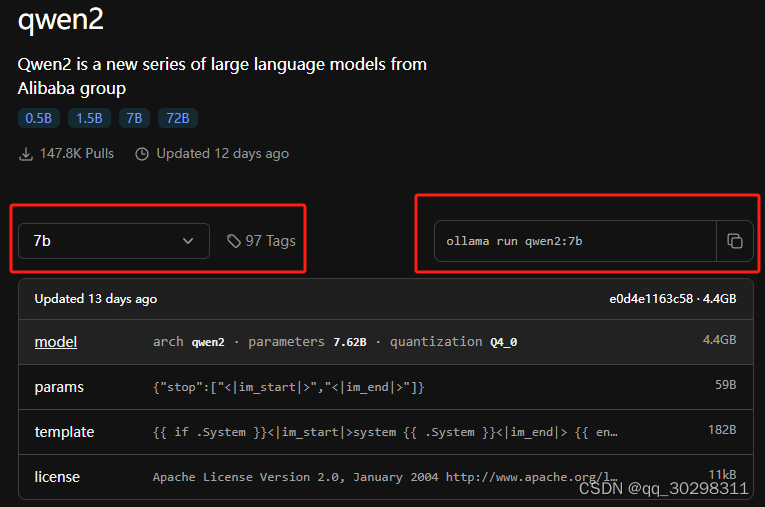
模型的标准名称可去ollama官方的library中查看,如:library (ollama.com),只要ollama的library中有的模型,都能用这种方式运行。
在模型详情页面,如:qwen2 (ollama.com),左边是模型选择下拉框,右边是ollama命令行中对应的模型运行语句,里面包含正确的模型标准名称。
注意:模型默认是Q4_0量化的,若要指定其他规格的模型,需在左边的下拉框中选择,然后使用右边变化后的ollama运行语句。
Ollama后端运行模式1:利用OpenAI库
Ollama可开启后端服务,通过服务网址来调用在本地部署的模型。OpenAI库就可以通过Ollama调用地部署的模型。
Ollama开启后端服务的默认端口是11434,在OpenAI库中调用需要加后缀/v1,如:http://localhost:11434/v1
调用方式如下:
class OpenAI_API:
def __init__(self):
self.client = OpenAI(
api_key="sk-11111111", # api_key不能为空,随便填
base_url="http://localhost:11434/v1" # 若不在本机调用,需修改为部署机器的ip
)
def stream_response(self, messages):
response = self.client.chat.completions.create(
model="qwen2:7b", # model为Ollama中的标准模型名称
messages=messages,
stream=True
)
...... # 根据实际情况补充代码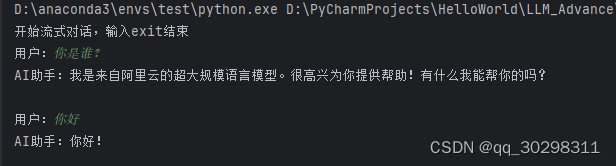
Ollama后端运行模式2:利用LLM开发工具和平台
目前有很多LLM开发工具和平台,在支持使用在线模型api导入的同时,也支持Ollama部署的本地模型,如LobeHub。
安装LobeHub
通过Docker Compose部署LobeHub:通过 Docker Compose 部署 LobeChat · Lobe... · LobeHub
安装完成后,通过 http://localhost:3210/ 进入网页
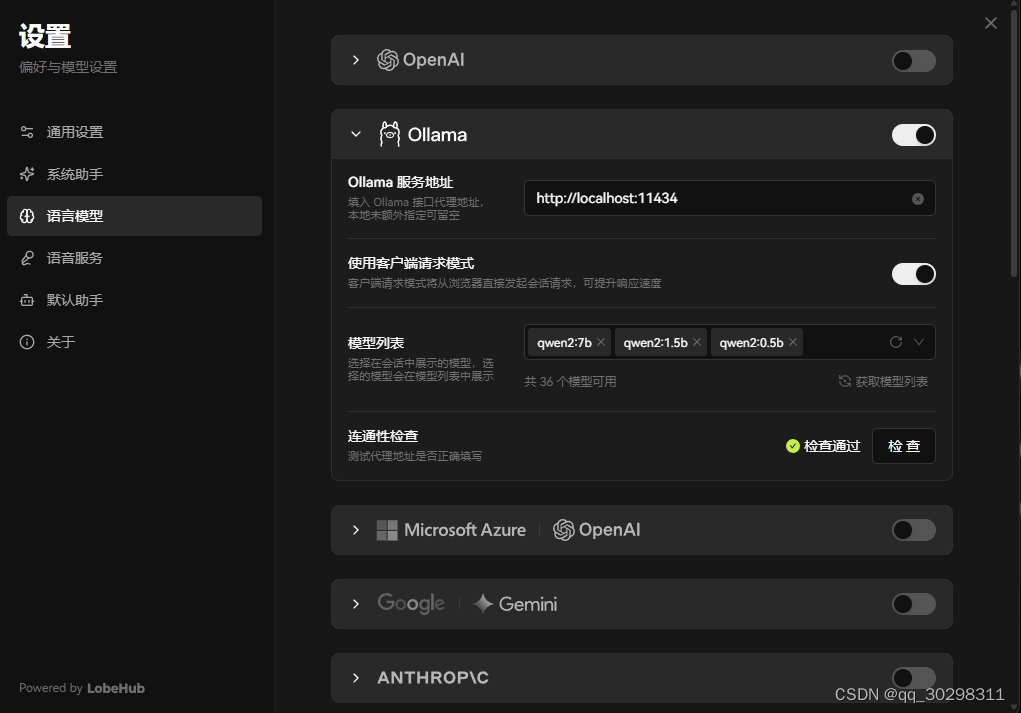
Lobehub接入Ollama服务
在设置中,选择模型为Ollama模式。填入服务地址和模型列表,模型列表要改为Ollama中的标准模型名称。
如下图所示:
在模型选择处,选择你自己部署的其中一个模型,即可开始调用。
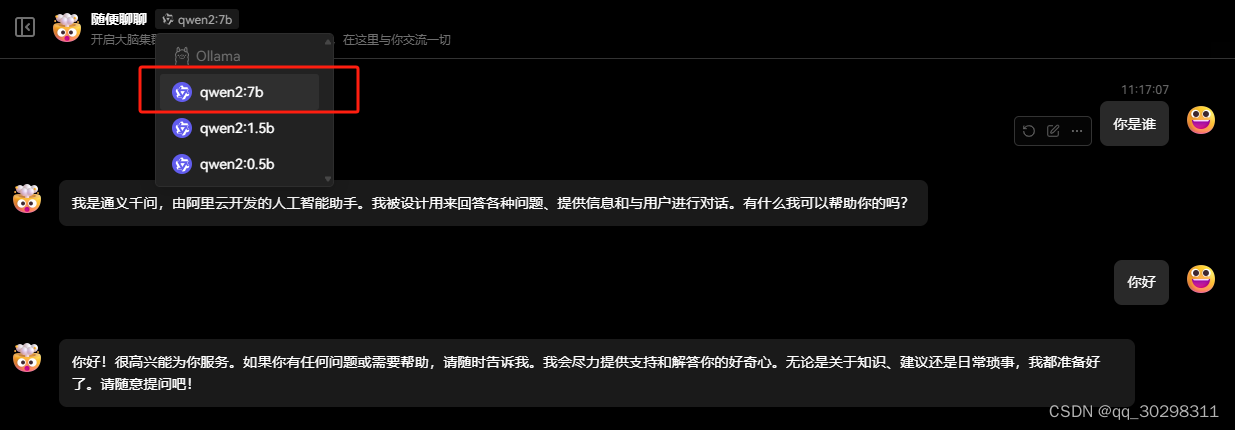
【bug】若Ollama原本可以调用gpu进行推理,偶尔出现只调用cpu,不调用gpu的情况,重启Ollama服务即可解决。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









