







hadoop伪分布式系统搭建
centos安装docker
把yum包更新到最新
[root@ecs-kc1-large-2-linux-20200802175157 ~]# yum update
卸载旧版本(如果安装过旧版本的话)
[root@ecs-kc1-large-2-linux-20200802175157 ~]# yum remove docker docker-common docker-selinux docker-engine
安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
[root@ecs-kc1-large-2-linux-20200802175157 ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
设置yum源
[root@ecs-kc1-large-2-linux-20200802175157 ~]# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
安装Docker,
[root@ecs-kc1-large-2-linux-20200802175157 ~]# yum install docker-ce
加入开机启动,
[root@ecs-kc1-large-2-linux-20200802175157 ~]# systemctl start docker
[root@ecs-kc1-large-2-linux-20200802175157 ~]# systemctl enable docker
验证安装是否成功(有client和service两部分表示docker安装启动都成功了)

配置伪分布式系统
前期准备
拉取centos7镜像
[root@ecs-kc1-large-2-linux-20200802175157 yum.repos.d]# docker pull centos:7
我因为是在华为云主机的服务器上利用docker搭建的分布式系统,所以遇到了一个小的坑,这里jdk需要选用arm64框架的
如下图

1,下载好jdk后通过fxtp上传到宿主机的一个目录中

之后通过如下代码将jdk安装文件上传到docker启动的一个centos容器中(这里事先要启动一个centos容器,1b指的是事先启动的容器id)
[root@ecs-kc1-large-2-linux-20200802175157 centos-ssh-root-jdk-hadoop]# docker cp jdk-8u261-linux-arm64-vfp-hflt.tar.gz 1b:/opt/
进入到centos容器中
docker exec -it 1b /bin/bash
之后开始配置jdk 进入到jdk文件所在目录之后解压
tar -zxvf jdk名字
配置环境变量信息
vi /etc/profile
文件最后添加如下信息:
export JAVA_HOME=/opt/java/jdk1.8.0_261#这里写jdk的路径
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
按 esc 退出插入模式,之后再输入 :wq 保存当前修改
通过如下命令使其立即生效
source /etc/profile
之后可以通过java -version测试是否安装成功
然后配置hadoop
上传hadoop文件如上文一样,之后进入容器内hadoop文件路径解压文件
tar -zxf hadoop-2.7.3.tar.gz
配置hadoop的环境变量
vi ${hadoop安装路径}/etc/hadoop/hadoop-env.sh
将jdk的路径添加到java_home

这样一个容器就配置好了之后通过commit将这个容器变为镜像
[root@ecs-kc1-large-2-linux-20200802175157 centos-ssh-root-jdk-hadoop]# docker commit 1b centos7-hadoop
之后启动三个这个镜像的容器
[root@ecs-kc1-large-2-linux-20200802175157 centos-ssh-root-jdk-hadoop]# docker run -it --name hadoop0 --hostname hadoop0 -d -P -p 50070:50070 -p 8088:8088 centos7-hadoop
docker run -it --name hadoop1 --hostname hadoop1 -d -P centos7-hadoop
docker run -it --name hadoop1 --hostname hadoop1 -d -P centos7-hadoop^C
分别进入三个容器中执行
source /etc/profile
保存配置
这样三个,容器就配置好了。
伪分布式配置
给这三台容器设置固定IP
1:下载pipework
下载地址:https://github.com/jpetazzo/pipework.git
2:把下载的zip包上传到宿主机服务器上,解压,改名字
unzip pipework-master.zip
mv pipework-master pipework
cp -rp pipework/pipework /usr/local/bin/
3:安装bridge-utils
yum -y install bridge-utils
4:创建网络
brctl addbr br0
ip link set dev br0 up
ip addr add 192.168.2.1/24 dev br0
5:给容器设置固定ip
pipework br0 hadoop0 192.168.2.10/24
pipework br0 hadoop1 192.168.2.11/24
pipework br0 hadoop2 192.168.2.12/24
验证一下,分别ping三个ip,能ping通就说明没问题
配置hadoop集群
先连接到hadoop0上,
使用命令
docker exec -it hadoop0 /bin/bash
下面的步骤就是hadoop集群的配置过程
1:设置主机名与ip的映射,修改三台容器:vi /etc/hosts
添加下面配置
192.168.2.10 hadoop0
192.168.2.11 hadoop1
192.168.2.12 hadoop2
2:在hadoop0上修改hadoop的配置文件
进入到/usr/local/hadoop/etc/hadoop目录
修改目录下的配置文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.3/data/tmp</value>
#要事先创建tmp文件
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml:修改文件名 mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
格式化
进入到/usr/local/hadoop目录下
1、执行格式化命令
bin/hdfs namenode -format
注意:在执行的时候会报错,是因为缺少which命令,安装即可
执行下面命令安装
yum install -y which
启动伪分布hadoop
sbin/start-all.sh

输入jps查看是否成功
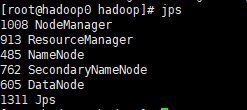
这样伪分布式就搭建成功















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









