







简单的举例:
下图是高斯分布的概率密度函数曲线

可以见到中间的任意小区间的概率大于两边的小区间的概率。
要生成这个概率密度函数f(x)的数据
(1)以x轴等长的将定义域分解成很多小区间,如分解为100个区间。
(2)以同样概率随机的选一个小区间,利用f(x)的积分计算这个小区间的概率值
(3)取一个均值分布0-1随机一个数,若这个数小于刚刚计算的概率,那么就把这个数据留下来。否则就不留。
不断的重复就可以得到符合这个分布的X。
原理
以相同的概率选取X的值或X一个邻域。
因为选了一个邻域后,这个邻域有概率值,表示X取这个区间内的值的概率Pi。因此再选一个均匀分布Y,随机一个数,若这个数小于Pi,那么Pi这个点就通过了。
这样的话概率密度大的区间最后得到的点就会多,而概率密度小的点或区间得到的点就会少。
依照以上的原理可以得到公式:

Fx(x)是已知概率分布函数。任取一个x的值,若FX(x)的值大于一个均匀分布,那么就留下,这个思路和这个公式相符。假如这样取的话,这个分布就是目标分布。
又因为:
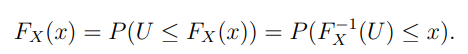
所以FX^-1(U)和X的分布一样。
参考
具体的数学分析可以看:
http://www3.eng.cam.ac.uk/~ss248/G12-M01/Week1/ITM.pdf















 101
101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









