







前言
终于把常见的ML分类模型介绍完了,回顾一下:逻辑回归、K-NN、决策树、随机森林、AdaBoost、GBDT、Stacking、Xgboost、LightGBM、Catboost、支持向量机和朴素贝叶斯,数数一共12个。希望大家都能把他们的大概原理和代码从头到尾都过了一遍。
然后我们来到第二阶段,机器学习分类的实战环节。这个阶段主要介绍ML的建模流程,说直白点就是一篇ML文章如何生产出来的,需要做哪些图等等。
一般来说ML建模分为六个步骤:数据收集——数据清洗——特征工程——构建模型——模型性能评价——误判数据分析。
我们简单来看看:
第一步:数据收集
没啥好说的,就是拿到数据,其实吧,这一步才是最难的,懂的都懂。这一部分在文章一般会有个流程图,数据的纳入排除标准,或者一个高大上的技术路线:
(1)比如纳入排除标准:
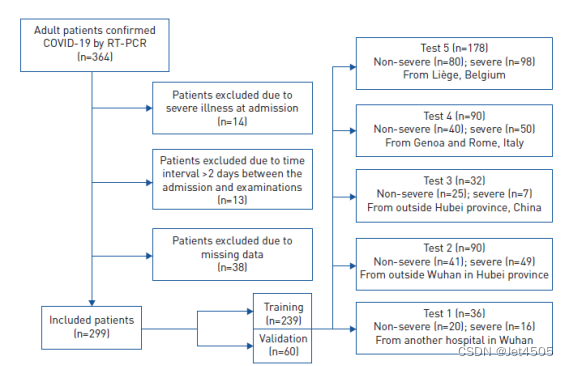
(2)高大上的技术路线:
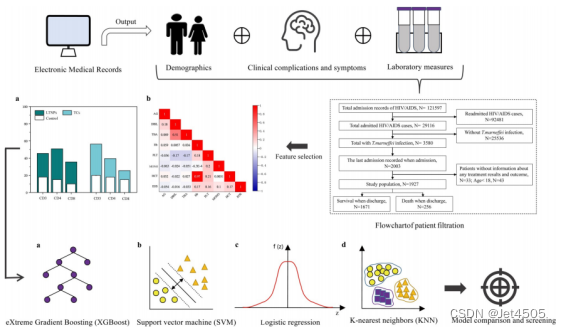
第二步:数据清洗
数据清理意味着过滤和“修改”数据(注意,这个修改不是那个修改),使其更易于探索、理解和建模。过滤是指去掉不想要或不需要的部分,这样就不需要查看或处理它们。“修改”是指数据的的格式不是我们需要的,需要修正。
常见的有:缺失值处理、离群值、坏数据、重复数据、不相关的特征、归一化和标准化等等。
数据清洗是ML工作流的非常重要的一步,做不好这一步,到建模的时候,可能会得到很多匪夷所思的结果,或者无限报错,可以让你无限返工到绝望。
这一步在文章中不需要图表体现,算是默默无闻的一步。
第三步:特征工程
终于又有可以换说这句话了:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
看到了吧,数据很重要,特征也很重要,所以怎么选择特征,选择什么特征来建模,已经上升到“工程”的高度。
因此,特征工程目的是最大限度地从原始数据中提取特征以供构建模型使用。
这一步一般是通过差异分析初步筛选有显著性差异的特征(有一点流统的思维了),接着结合相关性矩阵,重要性评分再剔除一些特征。会有几个高大上的图表展示:
(1)t检验弄一个表:
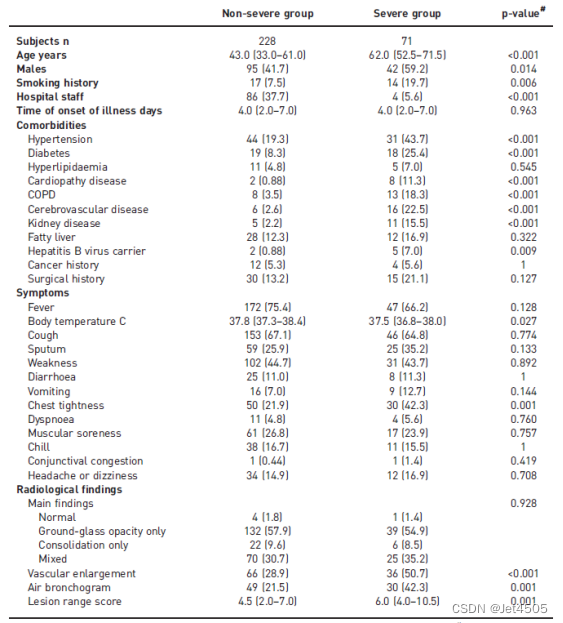
(2)t检验弄一个图:
(3)或者卡方检验弄一个图:
(4)然后搞一个相关矩阵,看看变量之间的相关性(其实就是为了好看):
(5)然后再来个什么特征重要性排名(雷达图,为了非主流):
特征工程大概就这样了,不过呢,同一种图可以有很多种表现形式,这个就看大家发挥了。
第四步:构建模型
这一步就是建模了,之前提到的模型,可以都走一遍。不过一般也不用全上,我个人喜欢用逻辑回归作为对照模型,然后上K-NN、随机森林、Xgboost、LightGBM、Catboost和支持向量机。
决策树呢,有随机森林、Xgboost等集成模型了,还要啥决策树。
朴素贝叶斯呢,太“朴素”了,我习惯不要。
GBDT呢,都有改进版本的Xgboost、LightGBM、Catboost,就不考虑了。
AdaBoost呢,可以考虑哈,毕竟是集成学习的另一种策略。
Stacking呢,自由度太高了,除非能够整出一个Stacking模型,能够秒杀上述所有模型,那可以有。
构建模型其实核心在于调参,后面我会一一介绍每个模型大概的调参策略。只能说个大概,因为这个是没有统一标准的,我个人觉得差不多就行了。不然调个死去活来,AUC就提高了0.1%,也没多大必要。
第五步:模型性能评价
这一步其实在之前已经提到过了,混淆矩阵、ROC曲线、准确率、灵敏度、特异度之类的,直接看看例子有个印象吧:
(1)训练集、测试集的ROC和AUC
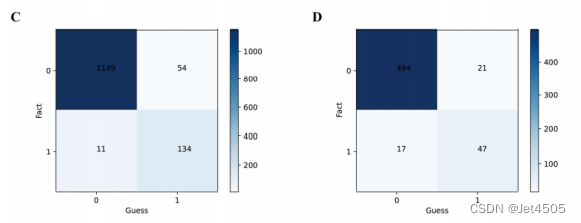
(2)训练集、测试集的混淆矩阵
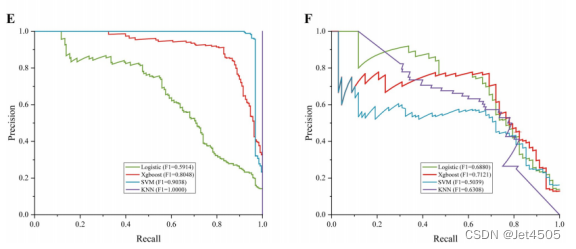
(3)训练集、测试集的PR曲线(新技能)
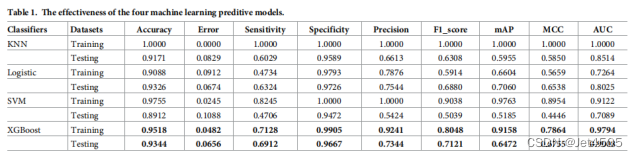
(4)训练集、测试集的性能指标(Xgboost YYDS)
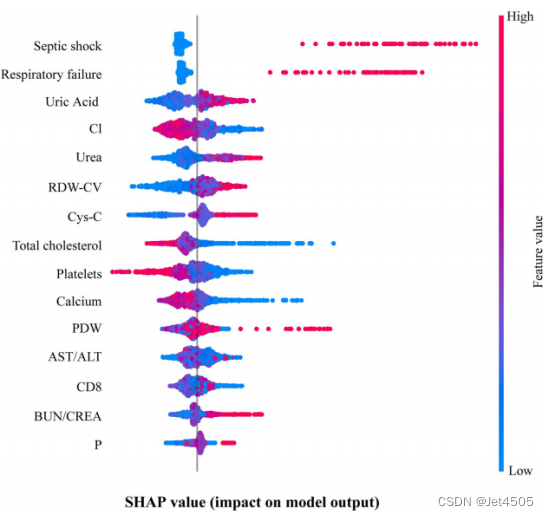
(5)在赠送一个高大上的图(新知识点)
第六步:误判数据分析
其实之前很多ML没有这一步(至少我看过的很少有),也是我突发奇想弄出来的。就是说,那些被模型误判的样本有什么特征呢?为什么它本来是0,模型预测是1?为什么它本来是1,模型预测是0?
我们可以单独把这些样本弄出来,分析它的特征,然后又多一个结果一个图,讨论还能多写一点,岂不妙哉。
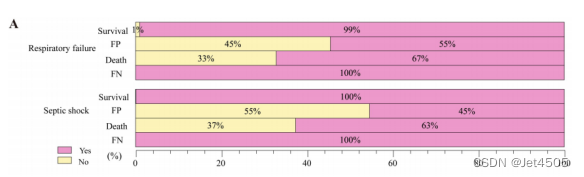
做的图大概长这样:
(1)卡方检验:
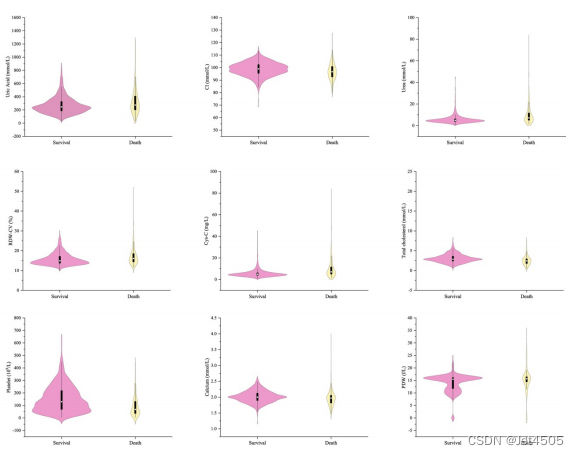
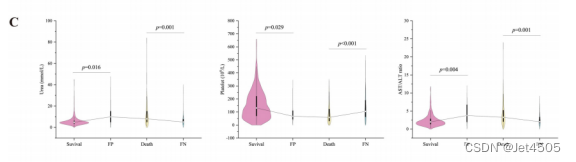
(2)小提琴图加t检验:
总结
ML建模流程大纲介绍到此,接下来便是每一步的详细介绍,各位加油哈!

















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











