







机器学习之KNN
本文主要介绍K近邻(KNN)模型,KNN在机器学习中是很常见的:
- 1、KNN模型介绍
- 2、KNN数学原理
- 3、算法及Python实现
- 4、小结
1、KNN模型介绍
k近邻法(k-nearest neighbor, k-NN)是一种基于分类与回归方法,这里只讨论分类问题中的k近邻法。k近邻假定给定一个训练数据集,其中实例类别已定,分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻不具有显示的学习过程,k值的选择、距离度量及分类决策规则是k近邻的三个基本要素。
2、KNN数学原理
k近邻中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定输入实例的类。
多数表决规则(majority voting rule)有如下解释:如果分类的损失函数为0-1损失函数,分类函数为
那么误分类的概率是
对给定的实例 x∈X x ∈ X ,其最近邻的k个训练实例点构成的集合 Nk(x) N k ( x ) 。如果涵盖 Nk(x) N k ( x ) 的区域类别是 cj c j ,那么误分类率是
要使误分类率最小即经验风险最小,就要使 ∑xi∈Nk(x)I(yi=cj) ∑ x i ∈ N k ( x ) I ( y i = c j ) 最大,所以多数表决规则等价于经验风险最小化。
3、算法及python实现
k-近邻算法如下:
对未知类别的属性数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别出现的频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
下面是python代码:(其中用到的数据集下载地址为digits.zip)
import operator
import os
from numpy import *
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#用当前点的坐标减去数据集中所有点的坐标得到欧式距离
diffMat = tile(inX,(dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances =sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = os.listdir('digits/trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('digits/trainingDigits/%s'%fileNameStr)
testFileList = os.listdir('digits/testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('digits/testDigits/%s'%fileNameStr)
classifierResult = classify0(vectorUnderTest,trainingMat,hwLabels,3)
print("the classifier came back with: %d,the real answer is: %d"%(classifierResult,classNumStr))
if(classifierResult != classNumStr):
errorCount += 1.0
print("\n the total number of errors if:%d" %errorCount),
print("\n the total error rate is: %f"%(errorCount/float(mTest)))
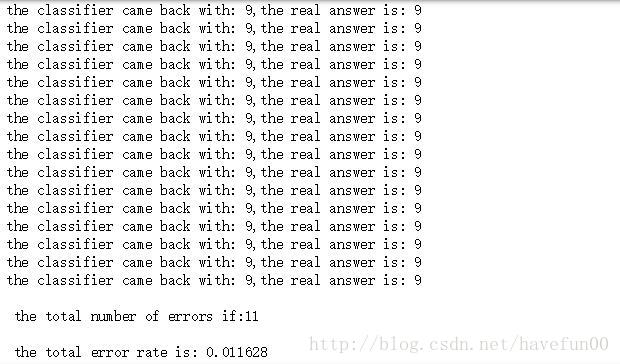
handwritingClassTest()运行结果截图如下
4、小结
k-近邻算法是分类数据最简单有效的算法,但在训练时必须保存全部数据集,如果训练数据集很大,会占用大量的存储空间。此外,由于必须对数据集中每个数据计算距离,实际使用可能非常耗时。使用距离进行进行分类并不能作为普遍的特征,因此KNN具有一定的局限性。















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









