







一、写在前面
之前,我们介绍了Sklearn包以及Boost辈的各种分类模型,这些模型都很经典了,实际上也很强大,比如说Xgboost。
然而,近期随着ChatGPT的大火,其底层框架Transformer也逐渐火了,现在大家朝着通用人工智能的方向靠拢。因此,我在想,尝试使用Transformer框架做一做临床诊断/预后问题(本质上就是分类问题),看看效果如何。
首先使用GPT简单科普Transformer框架:

二、尝鲜过程
实际上,我对于Transformer框架一概不知。所以,无脑求助GPT。
(1)用TA提供一个基础代码:
咒语:我有一个<临床数据>,其中“X1”列表示病人的预后(0表示生存,1表示死亡),其余列“X3”至“X19”表示临床自变量。
我需要写一个Transformer框架做分类的代码,使用“X3”至“X19”这17个自变量去预测“X1”,请用python帮我写出代码。
数据格式如下:
<
X1 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 X13 X14 X15 X16 X17 X18 X19
0 0 0 0 0 0 0 2.17 22 6.5 295 1.16 0.08 3.52 224 0.33 0 82.6
0 1 0 0 0 1 0 1.17 23 24.3 261 0.79 0.04 3.75 59 0.27 0.02 53.3
0 0 0 0 0 0 0 1.82 63.99 3.9 460.67 1.2 0.05 4.8 21 0.07 0 38.3
1 0 0 0 1 1 0 2.13 63.99 15.7 401.3 1.24 0.12 5.1 147 0.9 0.01 80.84
>
回复如下:
首先得安装PyTorch,具体安装教程就不说了。算了,还是说一下:
(a)打开Anaconda Prompt;
(b)打开Pytorch官网(https://pytorch.org/)寻找安装命令代码,根据自己的需求选择安装条件,比如我的LOW电脑没有GPU,只能用CPU;
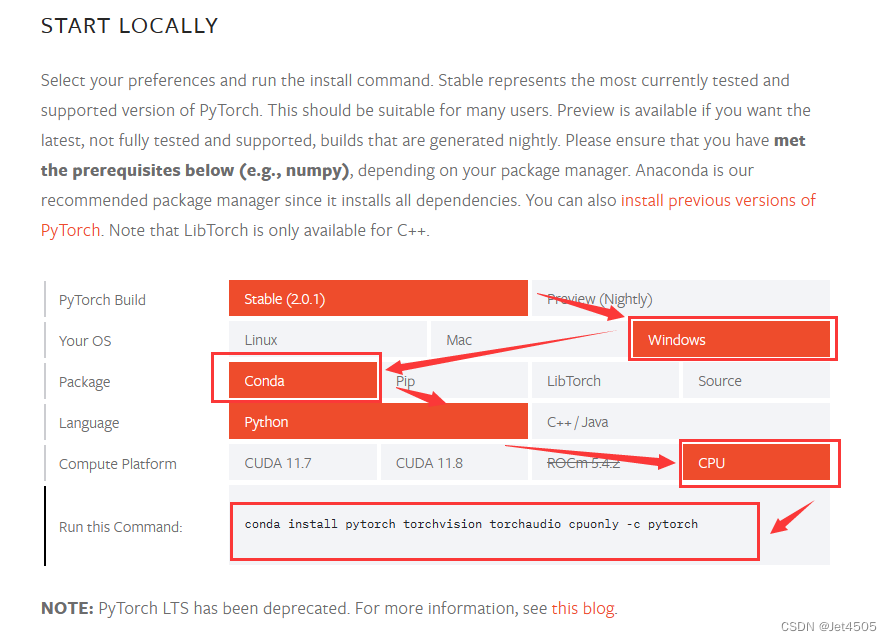
(c)在Anaconda Prompt输入代码安装(记得切换好安装环境):
conda install pytorch torchvision torchaudio cpuonly -c pytorch回车安装即可。
再附上GPT给的代码:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
# 加载数据
data = pd.read_csv('your_data.csv') # 请用您数据的实际路径替换 'your_data.csv'
X = data.loc[:, 'X3':'X19'].values
y = data['X1'].values
# 数据预处理
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建PyTorch数据加载器
train_data = torch.utils.data.TensorDataset(torch.Tensor(X_train), torch.Tensor(y_train))
test_data = torch.utils.data.TensorDataset(torch.Tensor(X_test), torch.Tensor(y_test))
train_loader = torch.utils.data.DataLoader(train_data, batch_size=32, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=32, shuffle=True)
# 定义设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 创建Transformer模型
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, nhead=1):
super(TransformerModel, self).__init__()
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=input_dim, nhead=nhead),
num_layers=3
)
self.classifier = nn.Linear(input_dim, output_dim)
def forward(self, x):
x = self.encoder(x)
x = self.classifier(x)
return x
# 初始化模型和优化器
model = TransformerModel(input_dim=X.shape[1], output_dim=2).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 训练模型
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels.long())
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1} / 100: Average Loss: {loss.item()}')(2)模型需要计算性能参数
写咒语:我还需要做得出模型在训练集和测试集上的性能指标,包括灵敏度、特异度和AUC值,帮我更新代码。
TA又更新了代码(只显示更新的部分):
# 训练模型
for epoch in range(20):
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels.long())
loss.backward()
optimizer.step()
# 验证模型
model.eval()
with torch.no_grad():
# 训练集
predictions = []
truths = []
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
output = model(inputs)
_, predicted = torch.max(output.data, 1)
predictions += predicted.tolist()
truths += labels.tolist()
tn, fp, fn, tp = confusion_matrix(truths, predictions).ravel()
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
auc = roc_auc_score(truths, predictions)
#print(f'Epoch {epoch+1} / 100, Training: Sensitivity: {sensitivity}, Specificity: {specificity}, AUC: {auc}')
# 测试集
predictions = []
truths = []
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
output = model(inputs)
_, predicted = torch.max(output.data, 1)
predictions += predicted.tolist()
truths += labels.tolist()
tn, fp, fn, tp = confusion_matrix(truths, predictions).ravel()
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
auc = roc_auc_score(truths, predictions)
print(f'Epoch {epoch+1} / 100, Testing: Sensitivity: {sensitivity}, Specificity: {specificity}, AUC: {auc}')把数据带进去运行试试:

可以看到,应该还是有一些过拟合的现象。
(3)继续施咒,如何改善过拟合。
施咒:上述的代码运行后出现过拟合,如何改善?

总体的挺到位的。我们来看看:
数据量就不考虑了,我也想要更多数据。更简单的模型,说的有道理,不过现在是测试这个面模型的性能。早停法也不适合,因为从20次迭代来看,都是过拟合的,你怎么样TA停,同样,交叉验证也是不可行。所以,试试其他的办法。
(4)增加正则化。
咒语:如何在代码中增加正则化项,请帮我改写相关代码段。

然后我加进去了,没啥效果。这是L2正则化,然后又问了L1正则化:

同样效果也不明显。
(5)减少模型复杂度。
咒语:如何做到“减少编码器层的数量、减少自注意力机制的头数或降低前馈神经网络的隐藏单元数量”,请分别修改代码段展示。
GPT注意给了回复,这里我一起展示:
# 创建Transformer模型
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, nhead=1):
super(TransformerModel, self).__init__()
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=input_dim, nhead=nhead),
num_layers=int(0.5 * input_dim) # 减少层数
)
self.norm = nn.BatchNorm1d(input_dim) # 添加批归一化层
self.classifier = nn.Linear(input_dim, output_dim)
self.dropout = nn.Dropout(1) # 添加一个dropout层 然后,效果也是不明显。
看来过拟合不好解决,同时我们可以看到,Sensitivity都是比Specificity要小的,这也可以理解,因为这是一个不平衡数据(正比负是1:3),下一步考虑从这一点入手。
(6)处理不平衡数据。
咒语:Sensitivity远远比Specificity要小,请问如何改进代码?

我们来分析下:重采样就算了,尽量不要动原始数据。第三个看不懂。所以,试试改变阈值。
(7)改变阈值。
咒语:改代码中如何改变阈值?请修改相应代码段。
代码如下:
# 验证模型
model.eval()
with torch.no_grad():
# 测试集
predictions = []
truths = []
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
output = model(inputs)
# 将输出结果用 softmax 函数转换为概率
probabilities = torch.nn.functional.softmax(output, dim=1)
# 调整阈值,例如设定阈值为 0.3
threshold = 0.3
predicted = (probabilities[:, 1] > threshold).long()
predictions += predicted.tolist()
truths += labels.tolist()
tn, fp, fn, tp = confusion_matrix(truths, predictions).ravel()
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
auc = roc_auc_score(truths, predictions)
print(f'Epoch {epoch+1} / 100, Testing: Sensitivity: {sensitivity}, Specificity: {specificity}, AUC: {auc}')当然值变动了测试集,我们来试试效果,阈值改成0.3:
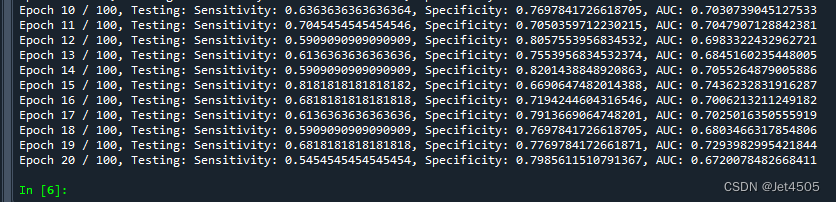
可以看到,特异度的份额被分到了灵敏度了,总体的AUC值变化不大。因此,性能基本上也就这样了。
最终的代码:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, roc_auc_score
import pandas as pd
import numpy as np
# 加载数据
data = pd.read_csv('Entry model3.csv') # 请用您数据的实际路径替换 'your_data.csv'
X = data.loc[:, 'X3':'X19'].values
y = data['X1'].values
# 数据预处理
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2338)
# 创建PyTorch数据加载器
train_data = torch.utils.data.TensorDataset(torch.Tensor(X_train), torch.Tensor(y_train))
test_data = torch.utils.data.TensorDataset(torch.Tensor(X_test), torch.Tensor(y_test))
train_loader = torch.utils.data.DataLoader(train_data, batch_size=32, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=32, shuffle=True)
# 定义设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 创建Transformer模型
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, nhead=1):
super(TransformerModel, self).__init__()
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=input_dim, nhead=nhead),
num_layers=int(0.5 * input_dim) # 减少层数
)
self.norm = nn.BatchNorm1d(input_dim) # 添加批归一化层
self.classifier = nn.Linear(input_dim, output_dim)
self.dropout = nn.Dropout(1) # 添加一个dropout层
def forward(self, x):
x = self.encoder(x)
x = self.classifier(x)
return x
# 初始化模型和优化器
model = TransformerModel(input_dim=X.shape[1], output_dim=2).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.0001, weight_decay=1e-5)
criterion = nn.CrossEntropyLoss()
# 训练模型
for epoch in range(20):
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels.long())
# 添加L1正则化
#l1_lambda = 0.001
#l1_norm = sum(p.abs().sum() for p in model.parameters())
#loss = loss + l1_lambda * l1_norm
loss.backward()
optimizer.step()
# 验证模型
model.eval()
with torch.no_grad():
# 训练集
predictions = []
truths = []
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
output = model(inputs)
_, predicted = torch.max(output.data, 1)
predictions += predicted.tolist()
truths += labels.tolist()
tn, fp, fn, tp = confusion_matrix(truths, predictions).ravel()
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
auc = roc_auc_score(truths, predictions)
#print(f'Epoch {epoch+1} / 100, Training: Sensitivity: {sensitivity}, Specificity: {specificity}, AUC: {auc}')
# 测试集
predictions = []
truths = []
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
output = model(inputs)
# 将输出结果用 softmax 函数转换为概率
probabilities = torch.nn.functional.softmax(output, dim=1)
# 调整阈值,例如设定阈值为 0.3
threshold = 0.3
predicted = (probabilities[:, 1] > threshold).long()
predictions += predicted.tolist()
truths += labels.tolist()
tn, fp, fn, tp = confusion_matrix(truths, predictions).ravel()
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
auc = roc_auc_score(truths, predictions)
print(f'Epoch {epoch+1} / 100, Testing: Sensitivity: {sensitivity}, Specificity: {specificity}, AUC: {auc}')三、总结
以上,Transformer框架能解决分类问题。不过在这个例子中,性能不太好,可能是因为数据量太小了吧(400多例而已)。反而,同样的数据,Xgboost略胜一筹(AUC:0.75),所以有时候,合适的模型才是最好的。
















 3269
3269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











