






 本文详细探讨了Transformer在计算机视觉(CV)领域的应用优势及关键技术,包括捕获长期依赖关系、统一模型、依赖样本计算等,并对比CNN的不同之处。重点介绍了Transformer、ViT(Vision Transformer)和Swin Transformer三种模型,解析它们如何解决序列处理难题,实现图像特征的有效提取。
本文详细探讨了Transformer在计算机视觉(CV)领域的应用优势及关键技术,包括捕获长期依赖关系、统一模型、依赖样本计算等,并对比CNN的不同之处。重点介绍了Transformer、ViT(Vision Transformer)和Swin Transformer三种模型,解析它们如何解决序列处理难题,实现图像特征的有效提取。
Transformer类
transformer在CV霸榜了,那么视觉中transformer比CNN的优势在哪里呢?总结一下:
(1)捕获长期依赖关系:大数据适配能力强(2)统一美:和NLP统一模型。(3)依赖样本计算:attention不仅仅关注loacl信息,更多的是学到的feature彼此之间的相互关系,普适性更好,不完全依赖于数据本身,不依赖value,(4)参数动态
并不是CNN就没有优势了。CNN可以学习平移不变性,尺寸不变性,扭曲不变性;常规transformer不具备,所以很多transformer的改进就是围绕这这个性质。
一. Transformer
提出问题:RNN:(1)并行化难。上一步的输出是下一步的输入,这种固有的顺序性质影响了训练的并行化。(2)长程依赖问题。
解决方案:提出了一种新的简单网络结构,即Transformer,它完全基于注意机制,完全不需要递归和卷积。
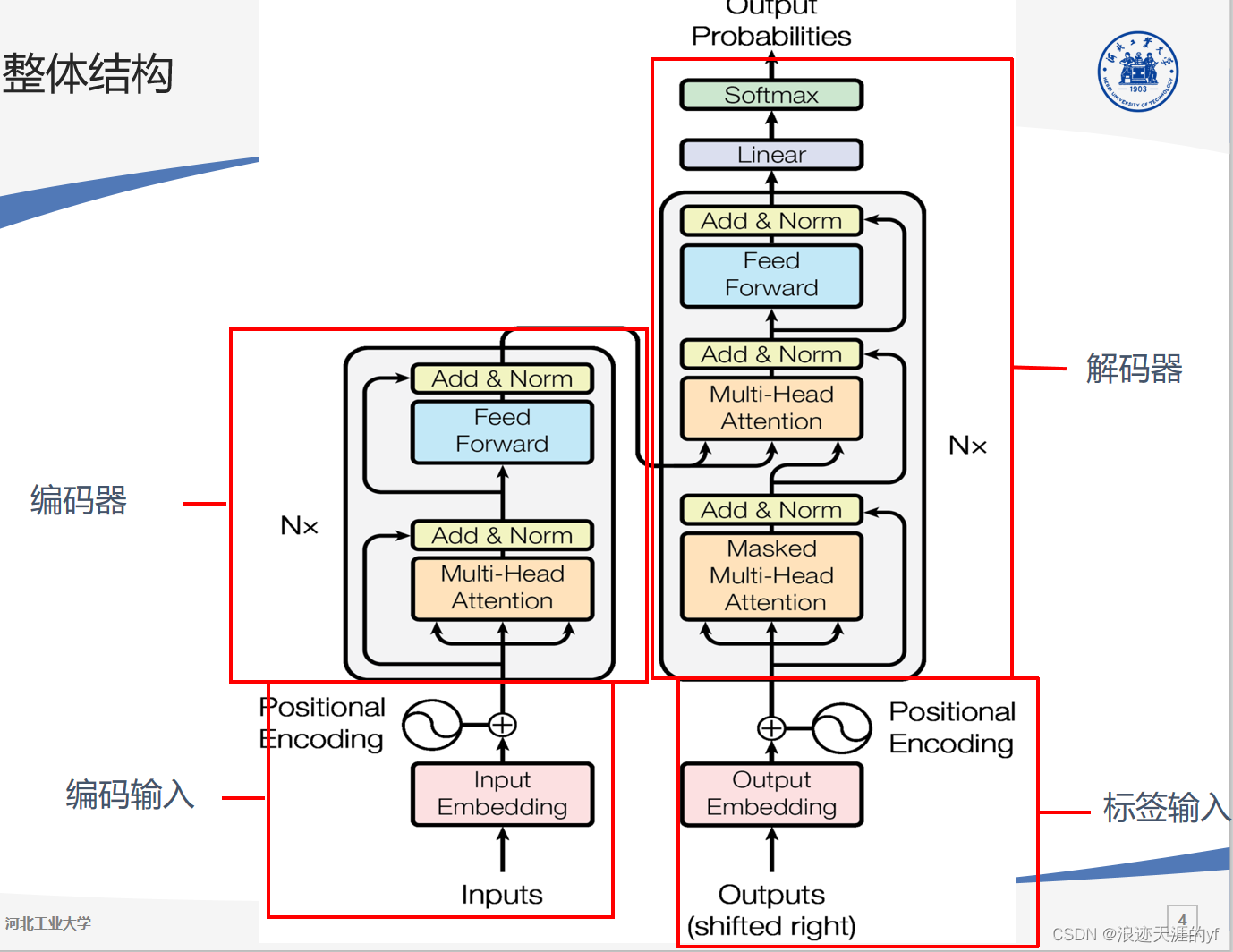
位置编码:

Transformers不像LSTM具有处理序列排序的内置机制,它将序列中的每个单词视为彼此独立。 所以使用位置编码来保留有关句子中单词顺序的信息。作用:它可以提升模型对位置信息的感知能力,弥补了Self Attention机制中位置信息的缺失(Self Attention机制中是没有位置信息的,而每个token是有先后顺序的,所以要有位置编码)。
为什么用sin,cos交替而不是1,2,3... ?
(1)1,2,3表示模型可能遇见比训练时所用的序列更长的序列。不利于模型的泛化
(2)1,2,3表示模型的位置表示是无界的。随着序列长度的增加,位置值会越来越大。 (3)有归一化作用,且相邻位置的间距一样(如果直接归一化到[0,1],不同序列长度间距不同)。(4)位置编码需要的是一个连续有界函数,sin刚好符合,但是sin是周期函数,所以分母上除以了,缩小频率。 (5)sin,cos交替是为了让不同的位置向量是可以通过线性转换得到的,这样不仅有绝对位置,还可以有相对位置信息。sin(a+b)=sinacosb+sinbcosa。
多头Self-Attention:
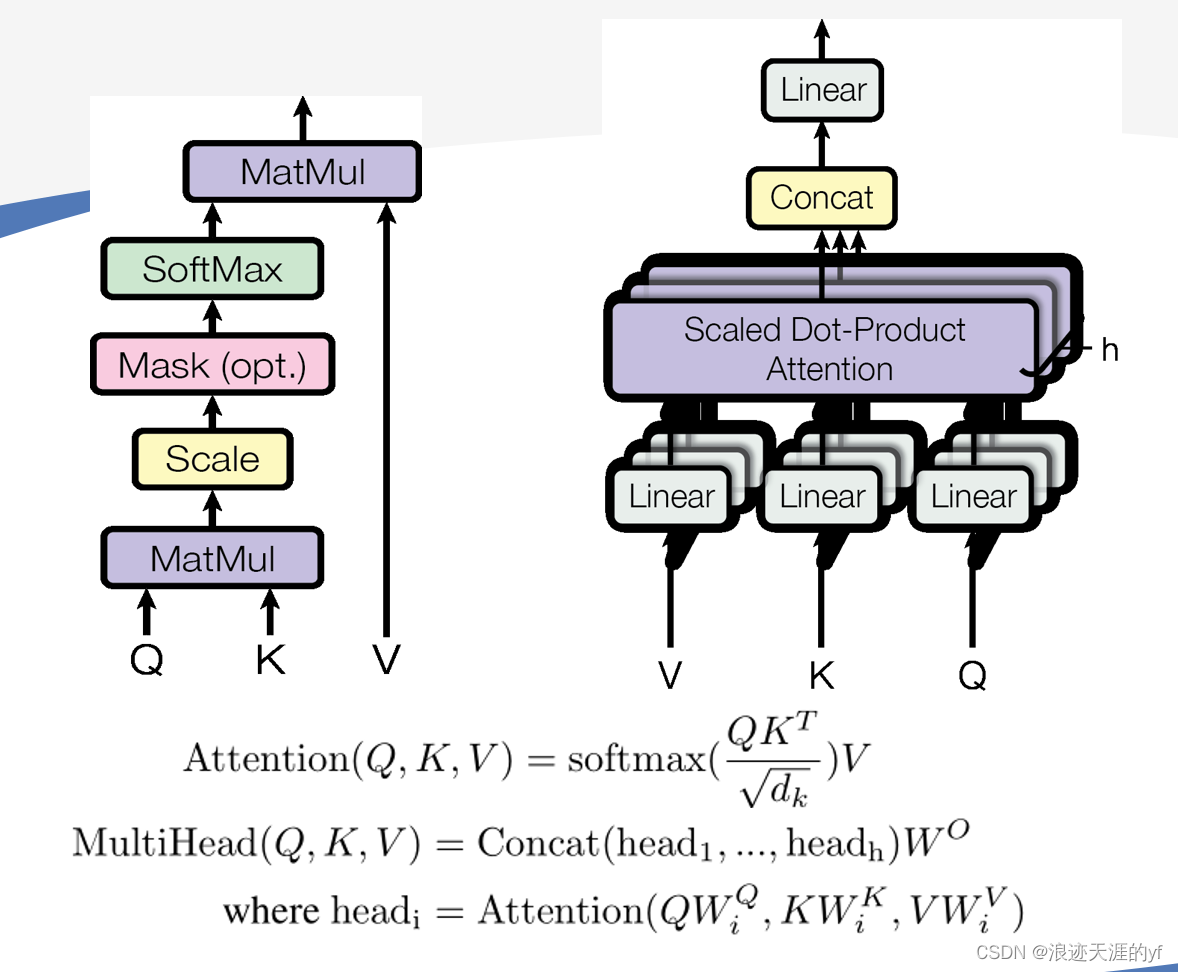
 (1)Q(query),K(key),V(value)是啥?
(1)Q(query),K(key),V(value)是啥?
如右图所示,qkv都是来自输入的X,可以理解为是分别通过的三个注意力矩阵得到的,首先看字面意思 Q: 要查询的信息 K: 被查询的向量 V: 查询得到的值。怎么理解?!每一个token都有自己的三个属性,它要和其他的token进行匹配。q就是它查询其他token有没有这个属性,k是自己的属性,用于被查询。v就是查询的结果,记录了和它匹配的token。
(2)除以dk的原因:点积得到的结果维度很大,使得结果处于softmax函数梯度很小的区域,除以一个缩放因子,可以一定程度上减缓这种情况。
(3)什么是多头:
Multi-Head Attention就是在self-attention的基础上,对于输入的embedding矩阵,self-attention只使用了一组来进行变换得到Query,Keys,Values。而Multi-Head Attention使用多组
得到多组Query,Keys,Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接。
(3)Why Self-Attention:
一个是每层的计算复杂度,另一个是可并行的计算量,用必要序列操作的最小数量来衡量。第三个是神经网络的长距离依赖长度。长距离依赖是很多序列转换任务的关键挑战,影响学习这种依赖的其中一个关键因素是网络中前向和后向信号必须经过的路径长度。输入和输出序列中位置的任意组合之间的这些路径越短,学习远程依赖关系就越容易。
二. ViT (Vision Transformer)
提出问题:如何将transformer从nlp迁移到CV,而且不使用卷积操作。
解决方案:提出ViT
这篇文章可以说是transformer在CV领域的首做,尽管之前是也有与卷积一起用在CV领域,但是这篇文章特点就是使用卷积结构。而是使用Transformer的注意力机制提取特征。

数据输入:ViT的输入部分是将完整的图片切分成多个PxP大小的图片,将这些小图片一起喂入网络,在喂入时,会给每个位置进行位置编码,来识别其每个图片在原图中的位置在输入时,还会加一个分类信息,如上图的0好编码。
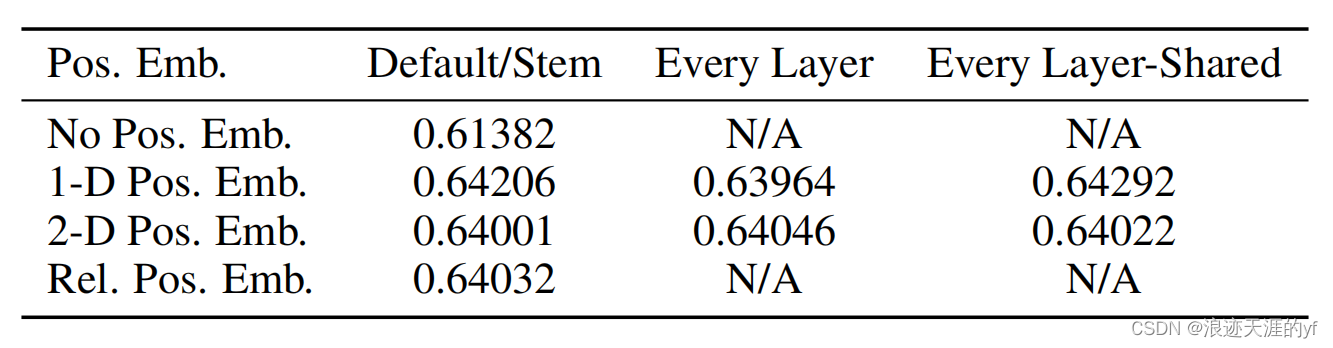
位置编码:位置编码就是将每个小图片进行编号,作者使用的时1维位置编码,就是直接当作一个序列输入进去,不用2维编码原因时作者说2维编码和1维效果差不多,如下图所示,Rel是相对编码。
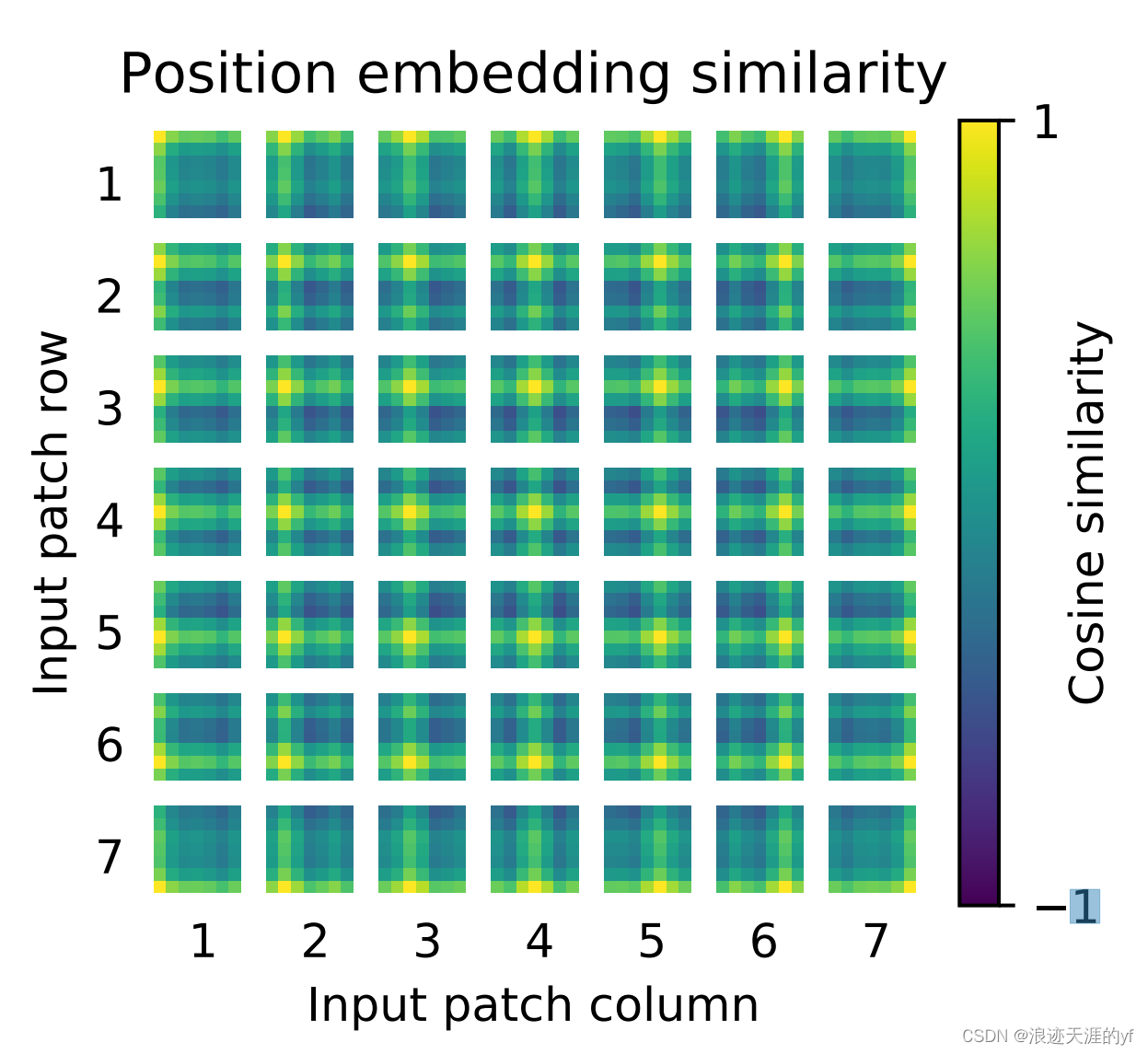
下图是学习到的位置信息,我们可以看到位置学习的还是不错的。
Transformer Encoder:这部分和 Transformer相同,使用了L个Encoder进行堆叠。L好像是6。后面接了一个MLP。
MLP(多层感知机):transformer 唯一不同的是,transformer 利用了所有的输出 token ,但是 ViT 只是进行分类,在这里只需要 [class] token 对应位置进行输出就可以。
三. Swin Transformer
提出问题:将Transformer从语言调整到视觉的挑战来自两个领域之间的差异:
1.视觉实体的大小差异很大,NLP对象的大小是标准固定的。
2.图像中的像素与文本中的单词相比具有很高的分辨率,而CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。
解决方案:
提出了a hierarchical Transformer ,其表示是用滑窗操作计算的。
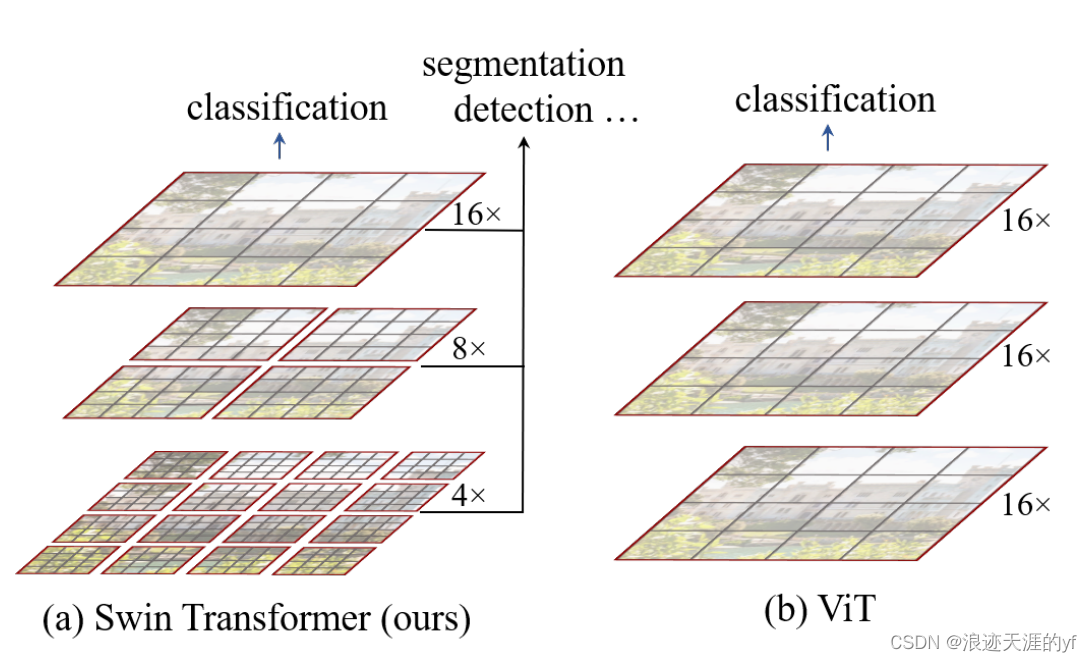
如上图左边所示,ViT是将图片下采样成16倍输入网络中,以整张图片为载体,去检测整张图片特征。而Swin transformer是将图像划分成多个window,window内部进行注意力计算。这样就大大减小了运算量。
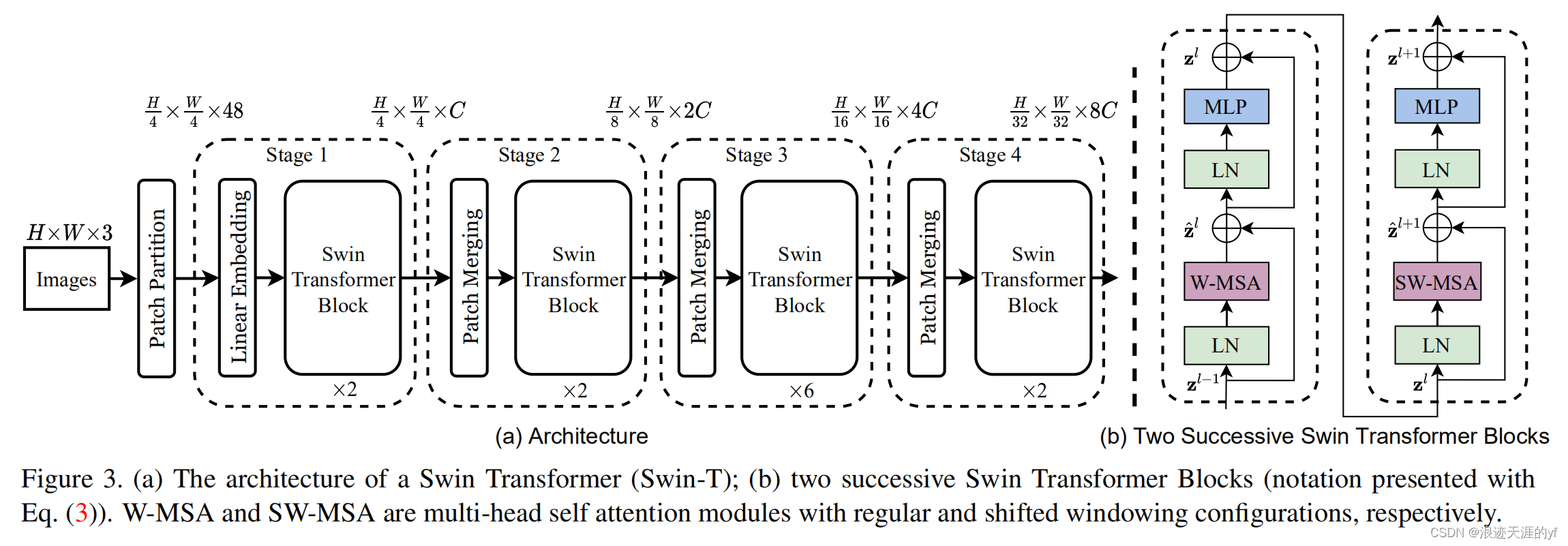
Patch parition目标是将图片序列化,分成16个小块(和vit一样)每个小块通道是3,所以总共48通道。
Linear Embedding 会经过一个Layer Norm将通道变成C。
Patch Merging是一个下采样操作,H、W变为1/2,C翻倍,操作其实就是 Patch parition和Linear Embedding的结合。
Swin Transformer Black都是偶数个,因为他是两个模块一起的,如上图右图所示。其他部分和vit一样,唯一不同的是W-MSA和SW-MSA。
W-MSA
举个例子(真实并不是这样计算,但原理一样,这里就是单纯为了理解):正常的MSA(Multi-head Self-Attention)是对图像每个像素点求QKV如上图所示,会有8X8个QKV,因为在transformer中每个Q会和每个K进行乘积运算,计算量就是(8X8)X(8X8)=4096
使用W-MSA,QKV个数是一样的但是每个Q不需要对每个K进行乘积运算,而是之和窗口里的进行运算。这样计算量就是(4X4)X(4X4)X4=1024。所以计算量会减少。
文章给出的计算量公式为(至于怎么得到的可以看下原文,或者其他博客,太长了,不写了):
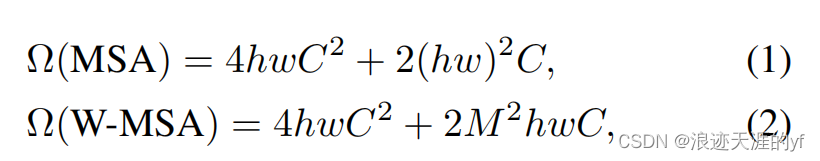
SW-MSA (Shifted Windows-MSA)
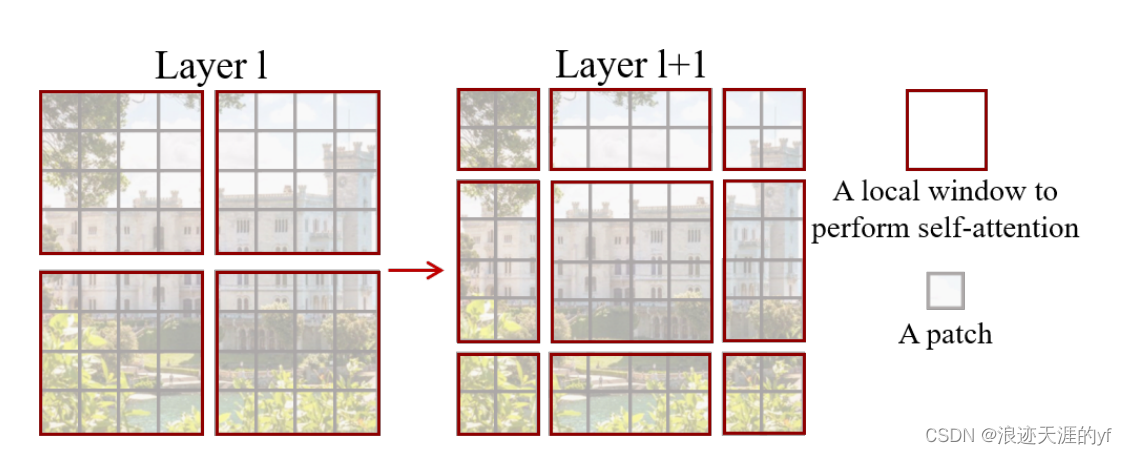
W-MSA有一个致命的缺点就是窗口和窗口之间的信息没有交互,解决方案就是用了窗口偏移。左图和右图的区别是右图分割界限往右下平移了两个格子。这样各自之间在下一层就有交互了,例如右图中间大正方形,会有上一层四个格子的部分信息。但是这样会有一个缺点就是格子变多了,如右图变成了9个。作者的解决方案是将多个小的格子拼成一个大的,比如四个角上的可以拼成一个大的,这样其实还是4个大格子。这样只是为了方便计算,但是左上和右下显然不是同一个区域,所以在计算单独一个时,其他的会打上掩码,将得分变成0.

















 3737
3737


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








