







什么是end to end ?
端到端指的是输入是原始数据,输出是最后的结果,只关心输入和输出,中间的步骤全部都不管。原来输入端不是直接的原始数据,而是在原始数据中提取的特征.
faster RCNN:
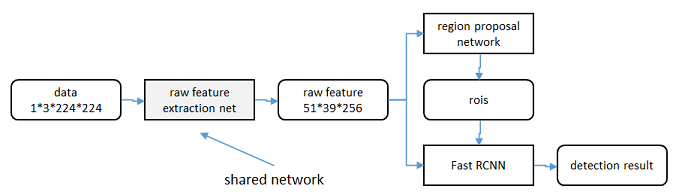 理解3个问题:
理解3个问题:
-
如何设计区域生成网络
-
如何训练区域生成网络
-
如何让区域生成网络和fast RCNN网络共享特征提取网络

RPN输入是feature map。

feature map的每一个点对应9个anchor,分别代表不同大小,不同长宽比的anchor,不同大小不同长宽比的anchor用来预测和该anchor最匹配的物体,因为一张图片里面会有不同大小不同形状的anchor。
那么,凭什么大的anchor就会去预测大的物体,小的anchor就会去预测小的物体?
主要就是在训练阶段利用IOU来设置不同box的标签,每个物体对应那些与其ground truth的 IOU 最大的anchor。这样只有与物体最匹配的anchor,它们之间的IOU才会最大。
缺点:
单尺度目标检测框架。

上面Faster RCNN用的是一个VGG卷积网络,经过五层卷积网络,最后的feature map 是 7 × 7 × 512 7 \times 7 \times 512 7×7×512的维度,可以看到相对于原图的 224 × 224 × 3 224 \times 224 \times 3 224×224×3的维度,已经缩小很多倍,变得很抽象,其实这对对于图像分类是很有利的,但是它损失了很多细节的信息,对于目标检测是不利的,不利于检测细微的物体。这里的单尺度的意思就是只使用了第五层卷积网络输出的 7 × 7 × 512 7 \times 7 \times 512 7×7×512的feature map。多尺度就是要同时使用前面卷积层产生的feature map。

如何实现多尺度?
(a)图像金字塔:给出不同尺度的图像,都输入到卷积网络中这种方式会使得计算量变大。
(b)单尺度:就是Faster RCNN中使用的,只使用最后一层卷积层的输出feature map
(c)多尺度:SSD中用到的,同时使用多层卷积网络层的输出feature map,不仅利用最后一层卷积网络的输出feature map,也利用浅层的卷积网络输出的feature map,其细节比较多,可以用于精确预测物体的位置,但是不利于语义分割,不利于分类。
(d)多尺度:使用最后一层卷积网络层的输出feature map,然后对其进行上采样,扩大其feature map的维度,同时加入浅层卷积网络输出的feature map,进行一个特征融合,这样不仅有很强的语义信息,用于分类,也有很强的位置信息用于位置检测。
一般上采样方式有:双线性插值和反卷积。
FPN:
Feature Pyramid Network (FPN)则是一种精心设计的多尺度检测方法,FPN结构中包括自下而上,自上而下和横向连接三个部分,如下图所示。这种结构可以将各个层级的特征进行融合,使其同时具有强语义信息和强空间信息

FPN实际上是一种通用架构,可以结合各种骨架网络使用,比如VGG,ResNet等。Mask RCNN文章中使用了ResNNet-FPN网络结构。如下图:
ResNet中用到了FPN:

ResNet-FPN包括3个部分,自下而上连接,自上而下连接和横向连接。下面分别介绍:
自下而上
从下到上路径。可以明显看出,其实就是简单的特征提取过程,和传统的没有区别。具体就是将ResNet作为骨架网络,根据feature map的大小分为5个stage。stage2,stage3,stage4和stage5的卷积层分别为conv2,conv3,conv4和conv5,它们的输出分别定义为: C 2 , C 3 , C 4 , C 5 C_{2}, C_{3}, C_{4}, C_{5} C2,C3,C4,C5,他们相对于原始图片的stride是{4,8,16,32}。需要注意的是,考虑到内存
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









