







KNN算法的原理很简单,主要是根据每个测试实例计算训练集中所有训练实例到该实例的距离,然后选择出前K个最小距离,得到它们的类别之后,采取投票原则,对测试集中的实例进行分类。
调用了sklearn库中的KNN算法,通过对比,发现自己编写的算法在性能上和sklearn库中KNN性能一直。在具体实现上有一些编程处理的小细节,在以下代码中将会体现到。本代码作为一个学习KNN的一个参考。KNN选取的K值可以动态设定,方便调用。
看一下运行的性能,本代码以sklearn.datasets.iris数据集为例,分析性能(默认设置的K=3),如下图所示:
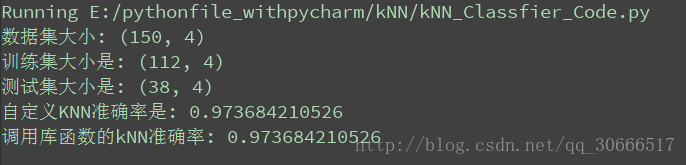
可以看到性能一致,欢迎交流!!!
源码如下:
# !/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: wsw
# 简单实现KNN分类器
import heapq
import numpy as np
from collections import Counter
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 构造KNN分类器
class KNN:
def __init__(self, k_neighbors=3):
"""
:param k_neighbors: 近邻K的大小,默认设置为3
"""
self.__K = k_neighbors
# 训练函数
def fit(self, train_data, test_data, train_label):
"""
:param train_data: 表示训练数据
:param train_label: 表示训练数据类别标记
:param test_data: 表示测试数据
:return: 返回每个测试实例的类别
"""
# 得到训练集实例的个数
train_nums = train_data.shape[0]
# 得到测试集实例的个数
test_nums = test_data.shape[0]
# 得到最后每个测试实例的类别,初始化为0
test_class = np.zeros(test_nums)
# 保存每个测试实例到所有训练样例距离的数组,初始化为0
dist_array = np.zeros(train_nums)
for i, test_instance in enumerate(test_data):
# 对于每个测试实例计算到训练集中每个实例的距离
for j, train_instance in enumerate(train_data):
dist = np.sqrt(sum(np.square(test_instance - train_instance)))
# 与第j个实例的距离添加到数组中
dist_array[j] = dist
# 寻找距离每个测试实例最近的k个距离的索引
indexes = heapq.nsmallest(self.__K, range(train_nums), dist_array.take)
# 得到k个索引的类别
classes = train_label[indexes]
# 采用投票原则得到每个实例最可能的分类
# 初始化一个计数器可以快速实现查找,自己构造也是可以的
counter = Counter(classes)
# 得到票数最多的类别,1代表得到一个最多的类别也即最大个数的类别
label = counter.most_common(1)
# 注意返回的label是一个list,在list中是以元组的形式放置数据,数据格式是[('label', nums)]
# label 是类别, nums是票数
# 所以我们只是需要取出'label', 也即类别只需要这样索引即可label[0][0]
# 得到每个实例预测的类别
test_class[i] = label[0][0]
return test_class
pass
# 计算模型的准确率
@staticmethod
def score(predict, test_label):
"""
:param predict: 预测的类别
:param test_label: 测试集实例实际的类别
:return: 准确率
"""
# 判断预测数组的元素和真实标记是否相同
correct = np.equal(predict, test_label)
# correct 是一个布尔数组,python可以直接进行运算
# 求准确率
accuracy = np.mean(correct)
return accuracy
pass
# 定义一个主函数
def main():
# 加载数据集
iris = load_iris()
# 查看数据集大小
print('数据集大小:', iris.data.shape)
# 将数据集分割成训练数据和测试数据
xtrain, xtest, ytrain, ytest = train_test_split(iris.data, iris.target, test_size=0.25, random_state=33)
print('训练集大小是:', xtrain.shape)
print('测试集大小是:', xtest.shape)
# 定义一个KNN类
knn = KNN(7)
# 训练
predict = knn.fit(xtrain, xtest, ytrain)
# 正确率测试
accuracy = knn.score(predict, ytest)
print('自定义KNN准确率是:', accuracy)
# 接下来测试一下调用库函数的准确率
knn_lib = KNeighborsClassifier(n_neighbors=3)
knn_lib.fit(xtrain, ytrain)
print('调用库函数的kNN准确率:', knn_lib.score(xtest, ytest))
if __name__ == '__main__':
# 函数调用运行
main()
pass













 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









