






论文链接:https://arxiv.org/pdf/2503.01307
1. 论文概述
论文探讨了语言模型在利用额外测试时计算(test-time compute)进行自我改进时,哪些内在的认知行为起到了关键作用。研究重点在于四种认知行为:
- 验证(Verification):对中间结果进行系统性检查。
- 回溯(Backtracking):当发现当前方案失败时,主动放弃并尝试其他路径。
- 子目标设定(Subgoal Setting):将复杂问题分解为更易管理的子问题。
- 逆向链式推理(Backward Chaining):从目标出发倒推到初始状态。
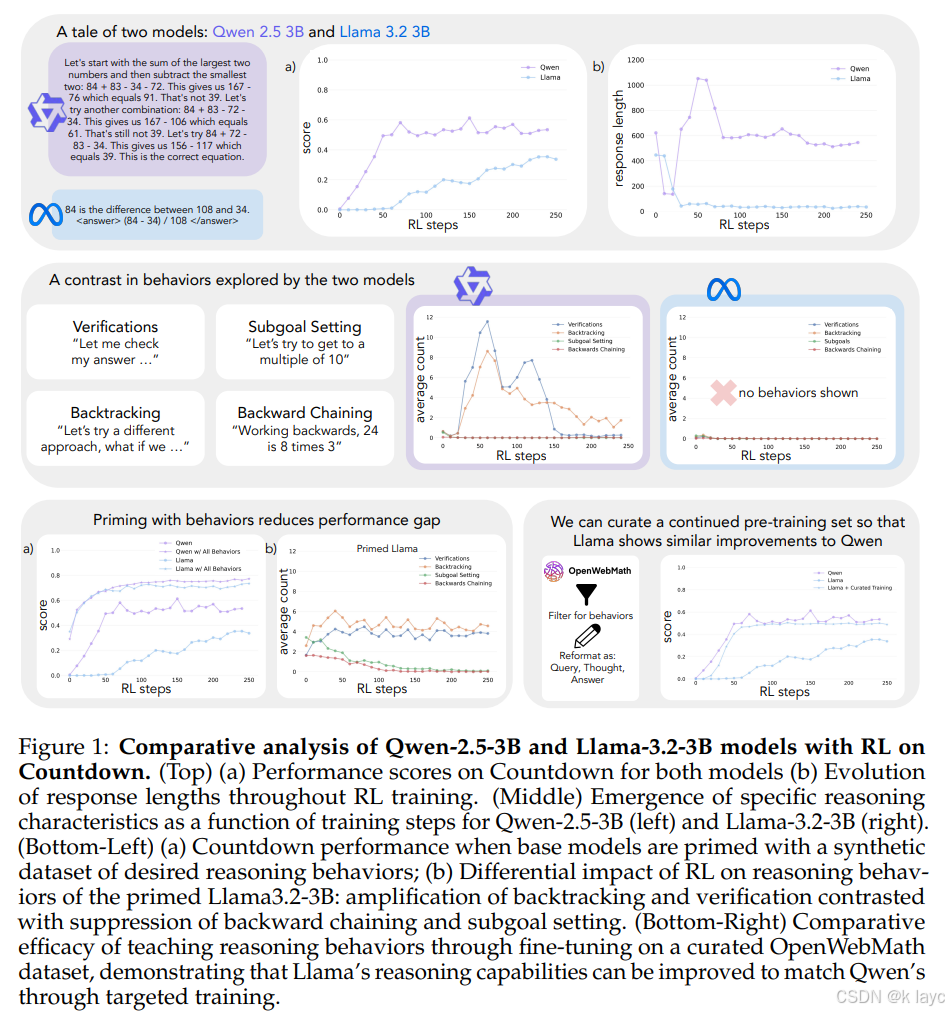
论文通过对比不同语言模型(如 Qwen-2.5-3B 和 Llama-3.2-3B)在 Countdown 游戏中的表现,分析了这些行为在自我改进中的作用,并通过数据干预、强化学习(RL)和预训练数据调整来验证这些认知行为的重要性。
2. 研究动机与背景
2.1 测试时推理与自我改进
-
测试时推理(Test-Time Inference):近年来,利用更多推理步骤和更长推理链条来“更仔细思考”复杂问题成为一种有效策略。论文指出,与人类专家在解决困难问题时花更多时间仔细思考类似,语言模型也能从延长推理过程中获益。
-
强化学习在自我改进中的作用:虽然通过 RL 对语言模型进行训练并非新鲜事,但不同模型在同样的 RL 训练下表现却差异巨大。例如,论文中提到在 Countdown 游戏中 Qwen-2.5-3B 能取得显著提升,而 Llama-3.2-3B 则很快遇到瓶颈。
2.2 认知行为的引入
作者提出,成功的自我改进不仅依赖于增加推理步骤或计算资源,更依赖于模型是否在初始策略中体现了类似人类专家的关键认知行为。具体来说,能够检查、修正、分解问题以及从目标逆推的能力决定了模型能否充分利用额外计算来改进自身。
3. 方法论与实验设计
论文主要通过两大方向探索如何促使语言模型“自我改进”:
3.1 分析关键认知行为
3.1.1 定义与分类
作者选取了四种关键行为:
-
验证(Verification)
- 模型在输出中包含诸如“Let me check my answer …”的语句,用以核对中间结果是否正确。
-
回溯(Backtracking)
- 当发现当前推理路线不通时,模型会明确指出“this approach won’t work because …”,并尝试其他方案。
-
子目标设定(Subgoal Setting)
- 模型在推理过程中主动将复杂问题分解为多个子问题,如“Let’s try to get to a multiple of 10”等。
-
逆向链式推理(Backward Chaining)
- 模型从目标出发,倒推到初始状态,例如“Working backwards, 24 is 8 times 3”。
这些行为在专家级问题解决中十分常见,也是模型在自我改进过程中有效利用长推理链条的重要保障。
3.1.2 行为检测与分类管道
- 作者使用 GPT-4o-mini3 构建了一个分类管道,通过预先提供示例,识别模型输出中是否包含上述认知行为,并统计其出现频次。这种量化分析为后续干预和评估提供了依据。
3.2 模型对比与 RL 实验
3.2.1 借助 Countdown 游戏构建实验环境
- Countdown 游戏简介:
Countdown 是一款数学拼图游戏,给定一组数字和一个目标数,玩家需要利用四则运算组合这些数字以达到目标。该任务要求模型具有数学计算、规划和搜索策略,是评估认知行为的理想测试床。
3.2.2 模型对比
- 对比模型:
- Qwen-2.5-3B:实验中表现出自然的验证和回溯行为,经过 RL 后表现大幅提升,准确率从低起步最终达到约 60%。
- Llama-3.2-3B:初始时缺乏上述认知行为,RL 训练后改进有限,仅达到 30% 左右的准确率。
3.2.3 关键发现
- 初始行为的重要性:
模型能否有效利用额外计算进行自我改进,取决于其是否在基础推理中体现出关键认知行为。Qwen 的改进正是由于其天然具备这些行为,而 Llama 则需要额外干预。
3.3 干预与行为引导
3.3.1 通过“Priming”(预激)引导行为
-
作者设计了多组“priming”数据集,对 Llama 模型进行微调,使其在推理过程中显现出特定的认知行为。数据集包括:
- 仅回溯(Backtracking Only)
- 回溯+验证
- 回溯+子目标设定
- 回溯+逆向链式推理
- 综合所有策略
-
实验发现:
经过这些行为干预后,Llama 的 RL 训练效果显著提升;更重要的是,即使使用包含错误答案但具有正确推理模式的数据,模型的性能也能大幅提高。这说明正确的认知行为比最终答案的正确性更为关键。
3.3.2 预训练数据干预
- 除了在 RL 阶段进行行为“priming”,作者还尝试修改预训练数据分布,利用 OpenWebMath 和 FineMath 数据集,筛选并重构出富含目标认知行为的文本。
- 经过继续预训练后,Llama 在自我改进的轨迹上逐渐与 Qwen 接近,证明通过预训练阶段的干预也能增强模型的认知行为,从而提升其利用测试时计算自我改进的能力。
4. 实验结果与分析
4.1 行为频率分析
-
基线对比:
通过对比 Qwen-2.5-3B 和 Llama-3.2-3B 的输出,发现 Qwen 自然展现出较高的验证、回溯、子目标设定和逆向链式推理行为,而 Llama 的这些行为显著较少。 -
干预后效果:
在对 Llama 进行行为干预后(通过 priming 以及预训练数据调整),这些认知行为的频次明显提升,伴随而来的是 Countdown 任务上准确率的显著改善。
4.2 RL 训练轨迹
-
训练步骤与响应长度:
实验中,Qwen 在 RL 训练过程中出现了响应长度延长、错误修正次数增多等现象,这反映出其在利用额外计算进行“深度思考”时,能够主动验证和修正自己的思路。 -
行为强化:
RL 不仅放大了已有的有用认知行为(如回溯和验证),同时在干预后的 Llama 上也能够学到这些策略,从而大幅提高整体表现。
4.3 重要结论
-
认知行为是自我改进的关键:
论文的核心发现是:模型在初始阶段是否具备诸如验证、回溯、子目标设定与逆向链式推理等认知行为,决定了其后续通过 RL 进行自我改进的潜力。 -
行为模式比正确答案更重要:
即使训练数据中的解决方案不完全正确,只要其中包含了正确的推理模式,模型依然可以利用这些模式进行有效学习。这一发现扩展了之前关于从错误轨迹中学习的工作。 -
预训练数据干预的有效性:
通过增加预训练数据中目标认知行为的比例,能够在不依赖特定任务(如 Countdown)的情况下,使模型在各类问题上展现出更强的自我改进能力。
5. 讨论与展望
5.1 讨论
-
内在认知行为与外部计算的关系:
模型能否利用额外的测试时计算不仅取决于计算资源本身,更依赖于模型是否具备引导这些计算的内在策略。只有当模型具备像人类专家一样“验证”、“回溯”等能力时,额外计算才能转化为更高的推理质量。 -
任务依赖性与通用性:
尽管本研究以 Countdown 游戏作为主要实验平台,但作者认为这些认知行为原则有望扩展到编码、游戏对抗、甚至创造性写作等更多领域。未来工作需要探讨如何在不同任务和领域中设计和引导这些认知行为。
5.2 展望
-
更多认知行为的探索:
本文重点关注了四种认知行为,未来可以探索例如类比思考(Making Analogies)和元认知(Metacognition)等其他策略,以进一步丰富模型的推理能力。 -
自我发现新行为:
除了模仿人类专家已有的行为,未来的模型可能通过自主探索发现全新的推理策略,从而开辟全新的自我改进路径。 -
安全与伦理:
随着模型具备更强的自我改进和自主推理能力,如何确保这些能力在安全可控范围内使用也成为亟待解决的问题。
6. 总结
论文《Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs》通过系统分析和实验验证,揭示了语言模型自我改进过程中关键的内在认知行为。作者证明:
- 模型具备验证、回溯、子目标设定和逆向链式推理等行为能够有效利用额外计算进行深度推理;
- 通过对 Llama 模型进行行为干预(无论是通过 priming 还是预训练数据调整),可以显著提升其在 Countdown 等任务上的表现;
- 即使训练数据中的答案不正确,只要推理过程体现出正确的认知模式,模型的学习效果仍能得到改善。
这一工作为构建能自我改进、持续进化的智能推理系统提供了理论依据和实验支持,也为未来研究如何引导模型“学习如何思考”开辟了新的方向。

















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









