







一、题目要求
在[0,100]*[0,100]的二维平面上有10个物体需要搬运,共有4个机器人。
现在需要将10个物体分配给4个机器人,使得机器人移动的总距离最小,如何分配?
每个机器人最多搬运3个物体。
10个物体和4个机器人的初始位置。
global task_position;
task_position = [[75.7740 ,82.3458];
[74.3132,69.4829];
[39.2227,31.7099];
[65.5478,95.0222];
[17.1187,3.4446];
[70.6046,43.8744];
[3.1833,38.1558];
[27.6923,76.5517];
[4.6171,79.5200];
[9.7132,18.6873] ]
global robot_position;
robot_position =[[48.9764,75.4687];
[44.5586,27.6025];
[64.6313,67.9703];
[70.9365,65.5098];]二、算法原理
1、算法运行流程
1、离散编码
对于n个任务,编码为1~n;
对于m个资源,编码为1~m;
2、粒子初始化
(1)粒子长度计算
粒子长度L为:
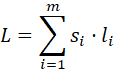
其中,li![]() 为第i个资源si
为第i个资源si![]() 能够执行任务的最大数目。
能够执行任务的最大数目。
(2)粒子内容
粒子内容为资源对应的编码,其中每个资源编码在粒子出现的次数等于其能执行任务的数目![]() 。
。
例:三个资源编码为1、2、3,资源1可执行三个任务,资源2可执行两个任务,粒子的一种形式如下:

(3)粒子意义

粒子中,第i个位置的内容为k,表示将任务i分配至资源k执行。
例:粒子中第一个位置的内容为2,表示将任务1分配至资源2执行。
(4)粒子初始化
设定粒子数目N,初始化粒子,即随机生成粒子内容为步骤(2),排序随机的N个粒子。
3、粒子位置变化
(1)适应度计算
第i个粒子的适应度为:
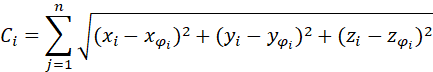
其中,为任务位置,计算过后保存每个粒子当前最优值和种群的最优值。
![]()
(2)惯性操作
随机生成i,j,其中![]() ,对粒子i,j位置处的内容进行置换,计算适应度值;
,对粒子i,j位置处的内容进行置换,计算适应度值;
若适应度值小于个体最优值对个体最优值进行更新;若适应度值大于劣势值,随机数小于w,也进行粒子更新;若小于种群最优值对种群最优值进行更新。
(3)自我认知
随机生成i,其中![]() ,将粒子个体第i个元素的内容替换为个体最优记录的第i个元素的内容;
,将粒子个体第i个元素的内容替换为个体最优记录的第i个元素的内容;
若适应度值小于个体最优值对个体最优值进行更新;若适应度值大于劣势值,随机数小于 ![]() ,也进行粒子更新;若小于种群最优值对种群最优值进行更新。
,也进行粒子更新;若小于种群最优值对种群最优值进行更新。
(4)社会认知
随机生成i,其中![]() ,将粒子个体第i个元素的内容替换为种群最优记录的第i个元素的内容;
,将粒子个体第i个元素的内容替换为种群最优记录的第i个元素的内容;
若适应度值小于个体最优值对个体最优值进行更新;若适应度值大于劣势值,随机数小于![]() ,也进行粒子更新;若小于种群最优值对种群最优值进行更新。
,也进行粒子更新;若小于种群最优值对种群最优值进行更新。
4、循环终止
(1)设定最大迭代次数;
(2)设定最优值变化率小于某值,退出循环。
三、实验代码与结果
1、实验代码
clear;clc;
T = [[75.7740 82.3458] %位置分布矩阵
[74.3132 69.4829]
[39.2227 31.7099]
[65.5478 95.0222]
[17.1187 3.4446]
[70.6046 43.8744]
[ 3.1833 38.1558]
[27.6923 76.5517]
[ 4.6171 79.5200]
[ 9.7132 18.6873]
[48.9764 75.4687]
[44.5586 27.6025]
[64.6313 67.9703]
[70.9365 65.5098]
];
n = 10; %n个任务
m = 4; %m个资源
max_load = 3; %任务最大携带资源量
L_context = [1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]; %粒子内容
dis = ones(n + m, n + m); %记录资源与任务两两之间欧式距离
for i = 1:n + m
for j = 1:n + m
dis(i, j) = ((T(i, 1) - T(j, 1))^2 + (T(i, 2) - T(j, 2))^2)^0.5;
end
end
NP = 100; % 种群规模
w = 0.5; % 惯性权重
c1 = 1.5; % 自我认知学习因子
c2 = 1.5; % 社会认知学习因子
L = m * max_load; % 粒子长度L
g = ones(NP, L); % 粒子群
best = 0; % 最佳迭代次数
num_max = 1000; % 最大进化代数
% 粒子初始化
for i = 1:NP
for j = 1:max_load
% 粒子随机生成排序
g(i, :) = L_context(randperm(numel(L_context)));
end
end
gb = ones(1, n + m);
num = 1; % 进化代数
cost = zeros(NP); % 存放个体的适应值
shortest_dis = 10^5; % 存放全局最优值
zbest = g(1, :); % 存放全局对应最优值的解
gbest = g; % 存放个体最优值
for i = 1:NP % 计算初始种群中的最优值和最优值对应的解
cost(i) = fitness(g(i, :), dis, n, m);
if(cost(i) <= shortest_dis)
shortest_dis = cost(i);
zbest=g(i, :);
end
end
f_gbest = cost; % 存放个体的最优适应值
while (num < num_max)
for i = 1:NP
% 惯性操作
position_i = randperm(n,1); %随机生成i
position_j = randperm(n,1); %随机生成j
%置换粒子i,j位置处内容
tmp = g(i, :);
tmp(position_i) = g(i, position_j);
tmp(position_j) = g(i, position_i);
% 适应值更新
tmp_cost = fitness(tmp, dis, n, m); % 计算新的适应度
% 适应度值小于个体最优值对个体最优值进行更新;
if tmp_cost < f_gbest(i)
g(i, :) = tmp;
gbest(i, :) = g(i, :);
f_gbest(i) = tmp_cost;
else % 随机数小于w,也进行粒子更新
if rand() < w
g(i, :) = tmp;
end
end
% 小于种群最优值对种群最优值进行更新
if tmp_cost < shortest_dis
zbest = tmp;
shortest_dis = tmp_cost;
best = num;
end
end
% 自我认知
K1 = randperm(L,1);
if fitness(gbest(K1, :), dis, n, m) > zbest
g(K1, :) = gbest(K1, :); %第i个元素的内容替换为个体最优记录的第i个元素
end
if rand < c1
g(K1, :) = gbest(K1, :); %第i个元素的内容替换为个体最优记录的第i个元素
end
if fitness(gbest(K1, :), dis, n, m) < shortest_dis
shortest_dis = fitness(gbest(K1, :), dis, n, m);
end
% 社会认知
K2 = randperm(L,1);
if fitness(gbest(K2, :), dis, n, m) > zbest
g(K2, :) = zbest; %第i个元素的内容替换为个体最优记录的第i个元素
end
if rand < c2
g(K2, :) = zbest; %粒子个体第i个元素的内容替换为种群最优记录的第i个元素
end
if fitness(gbest(K2, :), dis, n, m) < shortest_dis
shortest_dis = fitness(gbest(K1, :), dis, n, m);
end
gb(num) = shortest_dis;
num = num + 1;
end
plot(gb);
fprintf("迭代次数:%d 次 \nThe shortest distance = %f \n", best, shortest_dis);
[num ,route_msg] = fitness(zbest, dis, n, m);
for i = 1:m
j = 1;
fprintf("机器人%d:", i);
while(j <= 3 && route_msg(i, j) > 0)
fprintf("--> %d ", route_msg(i, j));
j = j + 1;
end
fprintf("\n");
end
%适应度函数
function [value, route_msg] = fitness(L, dis, n, m)
route_msg = zeros(m, 3);
value = 0.0;
for i = 1:m
%找到资源i需要完成的任务j的集合
pos = find(L(1:n) == i);
%暂时存储全局最短路径
tmp_shortest = 10000.0;
%全排列,计算资源i完成任务的所有可能路径
perm_mission = perms(pos);
for j = 1:length(perm_mission)
%初始值设为机器人i到第一个任务的距离
s = dis(i + n, perm_mission(j,1));
for k = 1:length(pos) - 1
s = s + dis(perm_mission(j,k), perm_mission(j,k + 1));
end
if s < tmp_shortest
%记录下资源i最短路径及其距离
tmp_shortest = s;
route_msg(i, 1: length(pos)) = perm_mission(j,:);
end
end
value = value + tmp_shortest;
end
end2、实验结果
迭代次数:58 次
The shortest distance = 201.173335
机器人1:--> 8 --> 9 --> 7
机器人2:--> 3 --> 10 --> 5
机器人3:--> 6
机器人4:--> 2 --> 1 --> 4 
4、说明
该代码不是我完成的(我太菜了),仅供大家参考。
流转了几手才到我手中,不知道原作者是哪位大佬,在此谢过。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









