







写在最开头,对GB的理解:
1、Gradient Boosting:每一次的计算是为了减少上一次的残差(residual),而为了消除残差,我们可以在残差减少的梯度(Gradient)方向上建立一个新的模型。在Gradient Boost中,每个新的模型的建立是为了使得之前模型的残差往梯度方向减少(当然也可以变向理解成每个新建的模型都给予上一模型的误差给了更多的关注),
2、Shrinkage(缩减)的思想认为:每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。用方程来看更清晰,即没用Shrinkage时:(yi表示第i棵树上y的预测值, y(1~i)表示前i棵树y的综合预测值)
y(i+1) = 残差(y1~yi), 其中: 残差(y1~yi) = y真实值 - y(1 ~ i)
y(1 ~ i) = SUM(y1, …, yi)
Shrinkage不改变第一个方程,只把第二个方程改为:
y(1 ~ i) = y(1 ~ i-1) + step * yi
即Shrinkage仍然以残差作为学习目标,但对于残差学习出来的结果,只累加一小部分(step*残差)逐步逼近目标,step一般都比较小,如0.01~0.001(注意该step非gradient的step),导致各个树的残差是渐变的而不是陡变的。直觉上这也很好理解,不像直接用残差一步修复误差,而是只修复一点点,其实就是把大步切成了很多小步。本质上,Shrinkage为每棵树设置了一个weight,累加时要乘以这个weight,这个weight就是step。
3、适用范围:该版本GBDT几乎可用于所有回归问题(线性/非线性),相对logistic regression仅能用于线性回归,GBDT的适用面非常广。亦可用于二分类问题(设定阈值,大于阈值为正例,反之为负例)。
from:https://blog.csdn.net/sb19931201/article/details/52506157
平方误差损失函数的残差,其他损失函数却不一定是。梯度提升树(gradient boosting),就是使用损失函数的负梯度作为残差的近似值。
为什么损失函数的负梯度作为残差的近似值?
总损失  取极小值时对应的 F 就是我们想求的 F。我们将F(x)作为自变量。根据梯度下降法,求取 J(F) 取极小值时的 F(x) :
取极小值时对应的 F 就是我们想求的 F。我们将F(x)作为自变量。根据梯度下降法,求取 J(F) 取极小值时的 F(x) :

每次迭代过程中(假设当前是第 m 轮迭代),假设下面数据(伪残差)的拟合结果为 h_m(x) 。

得到:
,。![]()
使用“line search”(一维搜索,即求解单变量函数的极小化问题),可以求得步长 ρm 为:

疑问:![]() 是什么。这里我对比GBDT中函数更新公式和基础的梯度下降将其理解为更新梯度的步长,但是并不确定。梯度下降中步长是超参数,不是根据数据学习的,这里的是需要根据数据优化的。此外,在看XGBOOST原理时,线搜索是用在寻找最佳树结构上的,而这里是寻找最佳。
是什么。这里我对比GBDT中函数更新公式和基础的梯度下降将其理解为更新梯度的步长,但是并不确定。梯度下降中步长是超参数,不是根据数据学习的,这里的是需要根据数据优化的。此外,在看XGBOOST原理时,线搜索是用在寻找最佳树结构上的,而这里是寻找最佳。
from:http://aandds.com/blog/ensemble-gbdt.html
GBDT和xgboost能有效的应用到分类、回归、排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的。本文尝试一步一步梳理GB、GBDT、xgboost,它们之间有非常紧密的联系,GBDT是以决策树(CART)为基学习器的GB算法,GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。xgboost扩展和改进了GDBT,xgboost算法更快,准确率也相对高一些。
事实上,分类与回归是一个东西,只不过分类的结果是离散值,回归是连续的,本质是一样的,都是特征(feature)到结果/标签(label)之间的映射。分类树的样本输出(即响应值)是类的形式,如判断蘑菇是有毒还是无毒,周末去看电影还是不去。而回归树的样本输出是数值的形式,比如给某人发放房屋贷款的数额就是具体的数值,可以是0到120万元之间的任意值。这时候你就没法用上述的信息增益、信息增益率、基尼系数来判定树的节点分裂了,你就会采用新的方式,预测误差,常用的有均方误差、对数误差等。而且节点不再是类别,是数值(预测值),那么怎么确定呢,有的是节点内样本均值,有的是最优化算出来的比如Xgboost。
CART回归树
CART回归树是假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。
而CART回归树实质上就是在该特征维度对样本空间进行划分,而这种空间划分的优化是一种NP难问题,因此,在决策树模型中是使用启发式方法解决。典型CART回归树产生的目标函数为:

在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
(1)选择最优切分特征j和最优的切分点s,就转化为求解这么一个目标函数:

遍历特征j,对固定的切分特征j,扫描切分点s,选择使得上式达到最小值的对(j,s)。所以我们只要遍历所有特征的的所有切分点,就能找到最优的切分特征和切分点。最终得到一棵回归树。
(2)用选定的对(j,s)划分区域成两个子区域R1,R2;并决定相应的输出值,分别为R1,R2区间内的输出平均值:
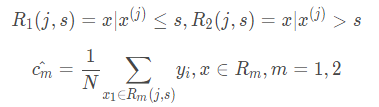
(3)继续对两个子区域调用步骤(1)和(2),直至满足停止条件。
(4)将输入空间划分为M个区域 R1,R2,...RM ,生成决策树:
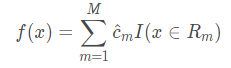
为所在区域的输出值的平均。
具体事例流程可参见:https://blog.csdn.net/gzj_1101/article/details/78355234#最小二乘法回归树生成算法
GBDT
GBDT泛指所有梯度提升树算法,包括XGBoost,它也是GBDT的一种变种,为了区分它们,GBDT一般特指“Greedy Function Approximation:A Gradient Boosting Machine”里提出的算法,只用了一阶导数信息。
GBDT是在函数空间上利用梯度下降进行优化
GBDT是多个弱分类器合成强分类器的过程(加权求和),每次迭代产生一个弱分类器,当前弱分类器是在之前分类器残差基础上训练。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量Gradient即每个文档得分的一个下降方向组成的N维向量,N为样本个数。这里仅仅是把”求残差“的逻辑替换为”求梯度“,可以这样想:梯度方向为每一步最优方向,累加的步数多了,总能走到局部最优点,若该点恰好为全局最优点,那和用残差的效果是一样的。
目标:损失函数尽可能快减小,则让损失函数沿着梯度方向下降。--> gbdt 的gb的核心了。

正如名字的含义,基本的结构:Gradient Boosting + 决策树 = GBDT。要注意的是这里的决策树是回归树,GBDT中的决策树是个弱模型,深度较小一般不会超过5,叶子节点的数量也不会超过10,对于生成的每棵决策树乘上比较小的缩减系数(学习率<0.1),有些GBDT的实现加入了随机抽样(subsample 0.5<=f <=0.8)提高模型的泛化能力。通过交叉验证的方法选择最优的参数。
负梯度拟合
Gradient boosting的思想是迭代生多个(M个)弱的模型,然后将每个弱模型的预测结果相加,后面的模型Fm+1(x)基于前面学习模型的Fm(x)的效果生成的,关系如下:


在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是, 损失函数是
, 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器
,让本轮的损失函数
最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
讲梯度提升树之前先来说一下提升树
假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小.


r就是当前的模型拟合数据的残差(residual)所以,对于提升树来说只需要简单地拟合当前模型的残差。回到我们上面讲的那个通俗易懂的例子中,第一次迭代的残差是10岁,第二 次残差4岁……
常见的损失函数如下:

当损失函数是平方损失和指数损失函数时,梯度提升树每一步优化是很简单的,但是对于一般损失函数而言,往往每一步优化起来不那么容易,针对这一问题,Friedman提出了梯度提升树算法,这是利用最速下降的近似方法,其关键是利用损失函数的负梯度作为提升树算法中的残差的近似值。
那么负梯度长什么样呢?

在上图中的损失函数中,GBDT选取了相对来说容易优化的损失函数——平方损失。大牛Freidman提出了用损失函数的负梯度来拟合本轮损失的近似值。进而拟合一个CART回归树.第m轮的第i个样本的损失函数的负梯度为:
![r_{im} = -\left[\frac{\partial L(y_i, F(x_i))}{\partial F(x_i)}\right]_{F(x)=F_{m-1}(x)} \quad \mbox{for } i=1,\ldots,n.](https://upload.wikimedia.org/math/0/b/e/0bebe45631e9a1c4ed693590d60829c0.png)
此时我们发现GBDT的负梯度就是残差,所以说对于回归问题,我们要拟合的就是残差。
 中的f,不要理解为传统意义上的函数,而是一个函数向量
中的f,不要理解为传统意义上的函数,而是一个函数向量 ,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
GB算法的步骤:
1.初始化模型为常数值:

2.迭代生成M个基学习器
1.计算伪残差
2.基于 生成基学习器
生成基学习器
3.计算最优的步长 (梯度方向下降最慢的步长?)
(梯度方向下降最慢的步长?)

4.更新模型

因此GBDT实际的核心问题变成怎么基于使用CART回归树生成?
GBDT算法过程(版本1):
假设训练集样本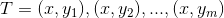
1、初始化弱学习器,选择一个特征c,使误差最小,c的均值可设置为N个样本y的均值。
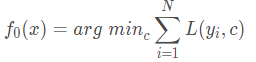
2、对迭代次数t=1,2,3,…,M有:
a、对样本i=1,2,3,…,N,计算负梯度,即残差:
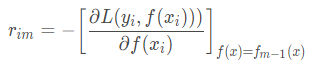
b、将上步得到的残差作为样本新的真实值,并将数据![]() 作为下棵树的训练数据,得到一颗新的第m棵回归树
作为下棵树的训练数据,得到一颗新的第m棵回归树,其对应的叶子节点区域为
![]() 。其中J 为第m个回归树中的叶子节点的个数;
。其中J 为第m个回归树中的叶子节点的个数;
c、对每个叶子区域j=1,2,3,…,J,计算最佳拟合值(其实就是每个区域内所有样本标签的均值):

我们拟合的是残差,所以
![]() 是到目前为止弱分类器所组成的强分类器的最终输出,目的是使其输出与实际y误差最小。注意这里的
是到目前为止弱分类器所组成的强分类器的最终输出,目的是使其输出与实际y误差最小。注意这里的和上面的步长
不是同一个东西。
d、更新强学习器
 或
或 
它代表一个集合,集合中每个值代表一个训练样本的序号,整个集合就是被第t棵CART树分到了第j个叶子节点上的训练样本。
3、得到强学习器f(x)表达式:

from:【机器学习算法总结】GBDT
算法流程如下(版本2):

2.1 :求之前分类器损失函数的负梯度作为本次弱分类器需要拟合的输出
2.2:对回归树的学习,一般选择CART TREE(分类回归树),对应的叶节点区域为w,CART树就用平方误差最小化
2.3:在叶结点区域上损失函数最小,求弱分类器权重(步长)
2.4:合成新的分类器
不同问题的提升树学习方法使用的损失函数不同,回归问题一般用平方误差损失函数,分类问题一般用指数损失函数,以及其它一般决策问题的一般损失函数。
损失函数
分类算法常用的损失函数有:指数损失函数和对数损失函数。
- 对数损失函数(二分类):

- 对数损失函数(多分类):

- 指数损失函数:

回归
回归算法常用损失函数有:均方差、绝对损失、Huber损失和分位数损失。
- 均方差:

- 绝对损失:L(y,f(x))=∣y−f(x)∣
- Huber损失:Huber损失是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心点附近采用均方差。这个界限一般用分位数点来度量,损失函数和对应的负梯度误差如下:

- 分位数损失:分位数损失和负梯度误差如下所示。其中其中θ为分位数,需要我们在回归前指定。

from:https://www.cnblogs.com/peizhe123/p/5086128.html
from:https://www.cnblogs.com/pinard/p/6140514.html
实例详解:
如下表所示:一组数据,特征为年龄、体重,身高为标签值。共有5条数据,前四条为训练样本,最后一条为要预测的样本。
| 编号 | 年龄(岁) | 体重(kg) | 身高(m)(标签值) |
|---|---|---|---|
| 0 | 5 | 20 | 1.1 |
| 1 | 7 | 30 | 1.3 |
| 2 | 21 | 70 | 1.7 |
| 3 | 30 | 60 | 1.8 |
| 4(要预测的) | 25 | 65 | ? |
参数设置:
- 学习率:learning_rate=0.1
- 迭代次数:n_trees=5
- 树的深度:max_depth=3
1.初始化弱学习器:

2.对迭代轮数m=1,2,…,M:
由于我们设置了迭代次数:n_trees=5,这里的M=5。计算负梯度,根据上文损失函数为平方损失时,负梯度就是残差残差,再直白一点就是 y与上一轮得到的学习器的差值

此时将残差作为样本的真实值来训练弱学习器,即下表数据:
| 编号 | 年龄(岁) | 体重(kg) | 标签值 |
|---|---|---|---|
| 0 | 5 | 20 | -0.375 |
| 1 | 7 | 30 | -0.175 |
| 2 | 21 | 70 | 0.225 |
| 3 | 30 | 60 | 0.325 |

以上划分点是的总平方损失最小为0.025有两个划分点:年龄21和体重60,所以随机选一个作为划分点,这里我们选年龄21,现在我们的第一棵树长这个样子:

例如:右节点误差:(0.225+0.325)-0.225)^2+(0.225+0.325)-0.325)^2=0.005
我们设置的参数中树的深度max_depth=3,现在树的深度只有2,需要再进行一次划分,这次划分要对左右两个节点分别进行划分:


此时可更新强学习器,需要用到参数学习率:learning_rate=0.1,用lr lrlr表示。
具体参考: https://blog.csdn.net/zpalyq110/article/details/79527653
GBDT分类算法
GBDT分类算法在思想上和回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。为解决此问题,我们尝试用类似于逻辑回归的对数似然损失函数的方法,也就是说我们用的是类别的预测概率值和真实概率值来拟合损失函数。对于对数似然损失函数,我们有二元分类和多元分类的区别
二分类
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,则损失函数表示为:
其中 。则此时的负梯度误差为:
。则此时的负梯度误差为:

对于生成的决策树,我们各个叶子节点的最佳残差拟合值为:

由于上式比较难优化,我们一般使用近似值代替:

多分类
多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假如类别数为K,则我们的对数似然函数为:

其中如果样本输出类别为k,则 。第k类的概率的表达式为:
。第k类的概率的表达式为:

集合上两式,我们可以计算出第t轮的第i个样本对应类别l的负梯度误差为:

其实这里的误差就是样本i对应类别l的真实概率和t-1轮预测概率的差值。对于生成的决策树,我们各个叶子节点的最佳残差拟合值为:

由于上式比较难优化,我们用近似值代替:

除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,多元GBDT分类和二元GBDT分类以及GBDT回归算法过程相同。
实例说明:
第一步:训练的时候,是针对样本X每个可能的类都训练一个分类回归树。如目前的训练集共有三类,即K = 3,样本x属于第二类,那么针对样本x的分类结果,我们可以用一个三维向量[0,1,0]来表示,0表示不属于该类,1表示属于该类,由于样本已经属于第二类了,所以第二类对应的向量维度为1,其他位置为0。
针对样本有三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。第一颗树针对样本x的第一类,输入是(x,0),第二颗树针对样本x的第二类,输入是(x,1),第三颗树针对样本x的第三类,输入是(x,0)。
在对样本x训练后产生三颗树,对x 类别的预测值分别是f1(x),f2(x),f3(x),那么在此类训练中,样本x属于第一类,第二类,第三类的概率分别是:

然后可以求出针对第一类,第二类,第三类的残差分别是:

开始第二轮训练,针对第一类输入为(x,y11(x)),针对第二类输入为(x,y22(x)),针对第三类输入为(x,y33(x)),继续训练出三颗树。一直迭代M轮,每轮构建三棵树。
当训练完毕以后,新来一个样本x1,我们需要预测该样本的类别的时候,便产生三个值f1(x),f2(x),f3(x),则样本属于某个类别c的概率为:![]()
下面以Iris数据集的六个数据为例来展示GBDT多分类的过程:

我们用一个三维向量来标志样本的label,[1,0,0]表示样本属于山鸢尾,[0,1,0]表示样本属于杂色鸢尾,[0,0,1]表示属于维吉尼亚鸢尾。gbdt 的多分类是针对每个类都独立训练一个 CART Tree。所以这里,我们将针对山鸢尾类别训练一个 CART Tree 1。杂色鸢尾训练一个 CART Tree 2 。维吉尼亚鸢尾训练一个CART Tree 3,这三个树相互独立。
下面我们来看 CART Tree1 是如何生成的。CART Tree的生成过程是从这四个特征中找一个特征做为CART Tree1 的节点。遍历所有的可能性,找到一个最好的特征和它对应的最优特征值可以让当前式子的值最小:

我们以第一个特征的第一个特征值为例。R1为所有样本中花萼长度小于5.1cm的样本集合,R2为所有样本中花萼长度大于等于5.1cm的样本集合,所以R1=[2],R2=[1,3,4,5,6]R1=[2],R2=[1,3,4,5,6]

y1为R1所有样本label的均值:1/1=1;y2为R2所有样本label的均值:(1+0+0+0+0)/5=0.2
下面计算损失函数的值,采用平方误差,分别计算R1和R2的误差平方和,样本2属于R1的误差:(1−1)2=0,样本1,3,4,5,6属于R2的误差和([1,0,0]表示样本属于山鸢尾):![]()
这里有四个特征,每个特征有六个特征值,所有需要6*4 = 24个损失值的计算,我们选取值最小的分量的分界点作为最佳划分点,这里我们就不一一计算了,直接给出最小的特征花萼长度,特征值为5.1 cm。这个时候损失函数最小为 0.8。 于是我们的预测函数此时也可以得到: ![]()
此例子中R1=[2],R2=[1,3,4,5,6], y1=1,y2=0.2,训练完以后的最终式子为:![]()
![]()
I看做单个叶节点包含的样本个数。
from:https://www.cnblogs.com/always-fight/p/9400346.html
正则化
我们也需要对GBDT进行正则化,防止过拟合。GBDT的正则化主要有3种方式:learning_rate(学习率);subsample(子采样比例);min_samples_split(叶子结点包含的最小样本数)。
1、learning_rate。学习率是正则化的一部分,它可以降低模型更新的速度(需要更多的迭代)。
经验表明:一个小的学习率 (v<0.1) 可以显著提高模型的泛化能力(相比较于v=1) 。如果学习率较大会导致预测性能出现较大波动。
2、subsample,子采样比例。每一轮迭代中,新的决策树拟合的是原始训练集的一个子集(而并不是原始训练集)的残差。这个子集是通过对原始训练集的无放回随机采样而来。无放回抽样的子采样比例(subsample),取值为(0,1]。如果取值为1,则与原始的梯度提升树算法相同,即使用全部样本。如果取值小于1,则使用部分样本去做决策树拟合。较小的取值会引入随机性,有助于改善过拟合,因此可以视作一定程度上的正则化;但是会增加样本拟合的偏差,
这种方法除了改善过拟合之外,另一个好处是:未被采样的另一部分子集可以用来计算包外估计误差。因此可以避免额外给出一个独立的验证集。
3、min_samples_split,叶子结点包含的最小样本数。梯度提升树会限制每棵树的叶子结点包含的样本数量至少包含m个样本,其中m为超参数。在训练过程中,一旦划分结点会导致子结点的样本数少于m,则终止划分。
RF与GBDT之间的区别与联系
都是由多棵树组成;最终的结果都由多棵树共同决定;
不同点:
组成随机森林的树可以分类树也可以是回归树,而GBDT只由回归树组成;
组成随机森林的树可以并行生成(Bagging);GBDT 只能串行生成(Boosting);这两种模型都用到了Bootstrap的思想;
随机森林的结果是多数表决表决的,而GBDT则是多棵树加权累加之和;
随机森林对异常值不敏感,而GBDT对异常值比较敏感;
随机森林是减少模型的方差,而GBDT是减少模型的偏差;
随机森林不需要进行特征归一化。而GBDT则需要进行特征归一化;
随机森林对训练集一视同仁权值一样,GBDT是基于权值的弱分类器的集成 ;
优缺点
GBDT主要的优点有:
1) 可以灵活处理各种类型的数据,包括连续值和离散值。
2) 在相对少的调参时间情况下,预测的准确率也可以比较高。这个是相对SVM来说的。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
GBDT的主要缺点有:
1)由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
参数调优:
参数分为两类,第一类是Boosting框架的重要参数,第二类是弱学习器CART回归树的参数。GradientBoostingClassifier和GradientBoostingRegressor的参数绝大部分相同。
- n_estimators: 也就是弱学习器的最大迭代次数,弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是100。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
- learning_rate: 即每个弱学习器的权重缩减系数,也称作步长,在原理篇的正则化章节我们也讲到了,加上了正则化项,我们的强学习器的迭代公式为
,v的取值范围为
。对于同样的训练集拟合效果,较小的意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的开始调参,默认是1。
- subsample: 即正则化章节讲到的子采样,取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间,默认是1.0,即不使用子采样。
- init: 即我们的初始化的时候的弱学习器,拟合对应原理篇里面的
,如果不输入,则用训练集样本来做样本集的初始化分类回归预测。否则用init参数提供的学习器做初始化分类回归预测。
- loss: 损失函数。
(1)对于分类模型,有对数似然损失函数"deviance"和指数损失函数"exponential"两者输入选择。默认是对数似然损失函数"deviance"。一般来说,推荐使用默认的"deviance"。它对二元分离和多元分类各自都有比较好的优化。而指数损失函数等于把我们带到了Adaboost算法。
(2)对于回归模型,有均方差"ls", 绝对损失"lad", Huber损失"huber"和分位数损失“quantile”。默认是均方差"ls"。一般来说,如果数据的噪音点不多,用默认的均方差"ls"比较好。如果是噪音点较多,则推荐用抗噪音的损失函数"huber"。而如果我们需要对训练集进行分段预测的时候,则采用“quantile”。 - alpha:这个参数只有GradientBoostingRegressor有,当我们使用Huber损失"huber"和分位数损失“quantile”时,需要指定分位数的值。默认是0.9,如果噪音点较多,可以适当降低这个分位数的值
CART回归决策树的参数基本来源于决策树类,也就是说,和DecisionTreeClassifier和DecisionTreeRegressor的参数基本类似。不再详述,可参见:https://www.jianshu.com/p/6a706c50afdf
应用场景
GBDT 可以适用于回归问题(线性和非线性);
GBDT 也可用于二分类问题(设定阈值,大于为正,否则为负)和多分类问题。
Xgboost
xgboost对应的模型就是一堆CART树。我们希望建立K个回归树,使得树群的预测值尽量接近真实值,而且有尽量大的泛化能力,预测就是将每棵树的预测值加到一起作为最终的预测值。下图就是CART树和一堆CART树的示例,用来判断一个人是否会喜欢计算机游戏:


我们用数学来准确地表示这个模型,如下所示:

这里的K就是树的棵数,F表示所有可能的CART树,f表示一棵具体的CART树。这个模型由K棵CART树组成。那么,这个模型的参数是什么?第二,用来优化这些参数的目标函数又是什么?
模型的目标函数,如下所示:

这个目标函数同样包含两部分,第一部分就是损失函数,第二部分就是正则项,这里的正则化项由K棵树的正则化项相加而来,获取了xgboost模型和它的目标函数,那么训练的任务就是通过最小化目标函数来找到最佳的参数组。
树的复杂度定义:
其中T为叶子节点的个数,||w||为叶子节点向量的模 。γ表示节点切分的难度,λ表示L2正则化系数。
如下例树的复杂度表示:
参数在哪里?
xgboost模型由CART树组成,参数自然存在于每棵CART树之中。确定一棵CART树需要确定两部分,第一部分就是树的结构(树的深度),这个结构负责将一个样本映射到一个确定的叶子节点上,其本质上就是一个函数。第二部分就是各个叶子节点上的值w。
如果K棵树的结构都已经确定,那么整个模型剩下的就是所有K棵树的叶子节点的值,模型的正则化项可以设为各个叶子节点的值的平方和。此时,整个目标函数其实就是一个K棵树的所有叶子节点的值的函数,我们就可以使用梯度下降或者随机梯度下降来优化目标函数。
加法训练,它是一种启发式算法。运用加法训练,我们的目标不再是直接优化整个目标函数。而是分步骤优化目标函数,首先优化第一棵树,完了之后再优化第二棵树,直至优化完K棵树。整个过程如下图所示:

在第t步时,我们添加了一棵CART树,这棵CART树
是怎么得来的呢?非常简单,就是在现有的t-1棵树的基础上,使得目标函数最小的那棵CART树,如下图所示:

假如我们使用的损失函数时MSE,那么上述表达式会变成这个样子:

这个式子非常漂亮,因为它含有的一次式和二次式,而且一次式项的系数是残差。你可能好奇,为什么有一次式和二次式就漂亮,因为它会对我们后续的优化提供很多方便,继续前进你就明白了。
注意:是什么?它其实就是第t个CART树
的某个叶子节点的值,叶子节点的值是可以作为模型的参数的。
但是对于其他的损失函数,我们未必能得出如此漂亮的式子,对于一般的损失函数,我们需要将其作泰勒二阶展开,泰勒公式的二阶导近似表示:
 ,
,![]() +
+![]()
令为Δx,则二阶近似展开:

其中:
.
:表示前t-1棵树组成的学习模型的预测误差,
gi和hi分别表示预测误差对当前模型的一阶导和二阶导
当前模型往预测误差减小的方向进行迭代。现有t-1棵树,这t-1棵树组成的模型对第i个训练样本有一个预测值,这个
与第i个样本的真实标签
肯定有差距是不是?这个差距可以用 L(
,
)这个损失函数来衡量。
我们来看一个具体的例子,假设我们正在优化第11棵CART树,也就是说前10棵 CART树已经确定了。这10棵树对样本(,
=1)的预测值是
=-1,假设我们现在是做分类,我们的损失函数是:

在=1时,损失函数变成:

我们可以求出这个损失函数对于的梯度,如下所示:

将 =-1代入上面的式子,计算得到-0.27。这个-0.27就是
。该值是负的,也就是说,如果我们想要减小这10棵树在该样本点上的预测损失,我们应该沿着梯度的反方向去走,也就是要增大
的值,使其趋向于正,因为我们的实际标签
=1就是正的。
在优化第t棵树时,有多少个和hi要计算?就是各有N个,N是训练样本的数量。如果有10万样本,在优化第t棵树时,就需要计算出个10万个
和hi。感觉好像很麻烦是不是?但是你再想一想,这10万个gi之间是不是没有啥关系?可以并行计算,这也是为什么xgboost会辣么快!
现在我们来审视下这个式子,哪些是常量,哪些是变量。式子最后有一个constant项,它就是前t-1棵树的正则化项。L(,
)也是常数项。剩下的三个变量项分别是第t棵CART树的一次式,二次式,和当前树的正则化项。这里所谓的树的一次式,二次式,其实都是某个叶子节点的值的一次式,二次式。
我们的目标是让这个目标函数最小化,常数项显然没有什么用,我们把它们去掉,就变成了下面这样:

现在我们可以回答之前的一个问题了,为什么一次式和二次式显得那么漂亮。因为这些一次式和二次式的系数是和hi,而
和hi可以并行地求出来。
和hi是不依赖于损失函数的形式的,只要这个损失函数二次可微就可以了。这有什么好处呢?好处就是xgboost可以支持自定义损失函数,只需满足二次可微即可。
模型正则化项
Ω()仍然是不清不楚。现在我们就来定义如何衡量一棵树的正则化项。我们先对CART树作另一番定义,如下所示:

首先,一棵树有T个叶子节点,这T个叶子节点的值组成了一个T维向量w,q(x)是一个映射,用来将样本映射成1到T的某个值,也就是把它分到某个叶子节点,q(x)其实就代表了CART树的结构。自然就是这棵树对样本x的预测值了。
有了这个定义,xgboost就使用了如下的正则化项:

注意:这里出现了γ和λ,这是xgboost自己定义的,在使用xgboost时,你可以设定它们的值,显然,γ越大,表示越希望获得结构简单的树,因为此时对较多叶子节点的树的惩罚越大。λ越大也是越希望获得结构简单的树。
见证奇迹的时刻
至此,我们关于第t棵树的优化目标已然很清晰,下面我们对它做如下变形,请睁大双眼,集中精力:

代表什么?它代表一个集合,集合中每个值代表一个训练样本的序号,整个集合就是被第t棵CART树分到了第j个叶子节点上的训练样本。T代表叶子结点树。理解了这一点,再看这步转换,其实就是内外求和顺序的改变。
进一步,我们可以做如下简化:

对于第t棵CART树的某一个确定的结构(可用q(x)表示),所有的Gj和Hj都是确定的。而且上式中各个叶子节点的值之间是互相独立的。上式其实就是一个简单的二次式,我们很容易求出各个叶子节点的最佳值以及此时目标函数的值。如下所示:

obj*值越小,代表这样结构越好!也就是说,它是衡量第t棵CART树的结构好坏的标准,这个值仅仅是用来衡量结构的好坏的,与叶子节点的值可是无关的。为什么?请再仔细看一下obj*的推导过程。obj*只和Gj和Hj和T有关,而它们又只和树的结构q(x)有关,与叶子节点的值可是半毛关系没有。如下图所示:

Note:这里,我们对给出一个直觉的解释。我们假设分到j这个叶子节点上的样本只有一个。那么,
就变成如下这个样子:

这个式子告诉我们,的最佳值就是负的梯度乘以一个权重系数,该系数类似于随机梯度下降中的学习率。观察这个权重系数,我们发现,
越大,这个系数越小,也就是学习率越小。
越大代表什么意思呢?代表在该点附近梯度变化非常剧烈,可能只要一点点的改变,梯度就从10000变到了1,所以,此时我们在使用反向梯度更新时步子就要小而又小,也就是权重系数要更小。
有了评判树的结构好坏的标准,我们就可以先求最佳的树结构,这个定出来后,最佳的叶子结点的值实际上在上面已经求出来了。
问题是:树的结构近乎无限多,一个一个去测算它们的好坏程度,然后再取最好的显然是不现实的。所以,我们仍然需要采取一点策略,这就是逐步学习出最佳的树结构。这与我们将K棵树的模型分解成一棵一棵树来学习是一个道理,只不过从一棵一棵树变成了一层一层节点而已。
下面我们就来看一下具体的学习过程。我们以判断一个人是否喜欢计算机游戏为例子。最简单的树结构就是一个节点的树。我们可以算出这棵单节点树的好坏程度obj*。假设我们现在想按照年龄将这棵单节点树进行分叉,我们需要知道:
1、按照年龄分是否有效,是否减少了obj的值
2、如果可分,那么以哪个年龄值来分。
为了回答上面两个问题,我们可以将这一家五口人按照年龄做个排序。如下图所示:

按照这个图从左至右扫描,我们就可以找出所有的切分点。对每一个确定的切分点,我们衡量切分好坏的标准如下:

这个Gain实际上就是单节点的obj*减去切分后的两个节点的树obj*,Gain如果是正的,并且值越大,表示切分后obj*越小于单节点的obj*,就越值得切分。同时,如果Gain就是负的,表明切分后obj反而变大了。γ在这里实际上是一个临界值,它的值越大,表示我们对切分后obj下降幅度要求越严。这个值也是可以在xgboost中设定的。
扫描结束后,我们就可以确定是否切分,如果切分,对切分出来的两个节点,递归地调用这个切分过程,我们就能获得一个相对较好的树结构。
注意:xgboost的切分操作和普通的决策树切分过程是不一样的。普通的决策树在切分的时候并不考虑树的复杂度,而依赖后续的剪枝操作来控制。xgboost在切分的时候就已经考虑树的复杂度,就是那个γ参数。所以,它不需要进行单独的剪枝操作。
链接:https://www.jianshu.com/p/7467e616f227
总结:
(1). xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。

(2). GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成,xgboost不仅使用到了一阶导数,还使用二阶导数。
第t次的loss:

对上式做二阶泰勒展开:g为一阶导数,h为二阶导数

(3). 上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,xgboost寻找分割点的标准是最大化,lamda,gama与正则化项相关

xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
树节点分裂方法
遍历所有特征的所有可能的分割点,计算Gain值,选取最大的 (Feature,label) 去分裂。
会在所有特征 (features) 上,枚举所有可能的划分(splits)。为了更高效,该算法必须首先根据特征值对数据进行排序,以有序的方式访问数据来枚举  公式中的结构得分 (structure score) 的梯度统计 (gradient statistics)。
公式中的结构得分 (structure score) 的梯度统计 (gradient statistics)。

近似方法:对于每个特征,只考察分位点,减少计算复杂度。
该算法会首先根据特征分布的百分位数 (percentiles of feature distribution),提出候选划分点 (candidate splitting points)。接着,该算法将连续型特征映射到由这些候选点划分的分桶(buckets) 中,聚合统计信息,基于该聚合统计找到在 proposal 间的最优解。
加权分位点 (Weighted quantile) 介绍:
举例子说明,一般来说对于一个数据列表有:
input: 1, 2, 3, 4, 5
weight:0.1, 0.2, 0.2, 0.3, 0.5
取元素的方法为:指定 rank,如 0.5 分位点的元素为3。
原因:当一个序列无法全部加载到内存时,常常采用分位数缩略图近似的计算分位点,以近似获取特定的查询。
近似算法举例:三分位数 (请仔细理解)

XGBoost 树节点实际分裂方式
实际上XGBoost不是简单地按照样本个数进行分位,而是以二阶导数值  作为权重(Weighted Quantile Sketch),如下:
作为权重(Weighted Quantile Sketch),如下:

为什么用 加权?
把目标函数 ![\tilde{L}^{(t)} \simeq \sum_{i=1}^{n} [ g_i f_t(\mbox{x}_i) + \frac{1}{2}h_i f_t^2(\mbox{x}_i)]+\Omega(f_t)](https://i-blog.csdnimg.cn/blog_migrate/dd9a379c4bffb3513fd44ff74c19fe0e.png) 整理成以下形式,可以看出 有对
整理成以下形式,可以看出 有对  加权的作用。
加权的作用。
![\begin{align} \tilde{L}^{(t)} & \simeq \sum_{i=1}^{n} [ g_i f_t(\mbox{x}_i) + \frac{1}{2}h_i f_t^2(\mbox{x}_i)]+\Omega(f_t) \\ &= \sum_{i=1}^{n} [ g_i f_t(\mbox{x}_i) + \frac{1}{2}h_i f_t^2(\mbox{x}_i) \underbrace{\color{red}{+ \frac{1}{2}\frac{g_i^2}{h_i}}}_{\text{添加一个常数}}]+\Omega(f_t) \color{red}{+ constant} \\ &= \sum_{i=1}^{n} \color{red}{\frac{1}{2}h_i} \left[ f_t(\mbox{x}_i) - \left( -\frac{g_i}{h_i} \right) \right]^2 + \Omega(f_t) + constant \end{align}](https://i-blog.csdnimg.cn/blog_migrate/c91623b7c92cc66c21bcec90def555ce.png)
from:https://zhuanlan.zhihu.com/p/38297689
xgboost与gdbt除了上述三点的不同,xgboost在实现时还做了许多优化:
- xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,paper提到50倍。
- 特征列排序后以块的形式存储在内存中,在迭代中可以重复使用;虽然boosting算法迭代必须串行,但是在处理每个特征列时可以做到并行。XGBoost与GDBT都是逐次迭代来提高模型性能,但是XGBoost在选取最佳切分点时可以开启多线程进行,大大提高了运行速度
- XGBoost是拟合上一轮损失函数的二阶导展开,GDBT是拟合上一轮损失函数的一阶导展开,因此,XGBoost的准确性更高,且满足相同的训练效果,需要的迭代次数更少。
- xgboost在切分的时候就已经考虑了树的复杂度,就是那个γ参数。所以,它不需要进行单独的剪枝操作。
from :https://www.cnblogs.com/wxquare/p/5541414.htmlhttps://www.cnblogs.com/wxquare/p/5541414.html

















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









