







bagging和boosting
bagging和boosting是模型集成的两种方式,可以将很多弱分类器融合成一个强分类器
bagging:采用有放回的均匀采样,基分类器之间不存在依赖关系,可以并行处理,通过投票表决的方式来确定结果
boosting:根据错误率来进行采样,基分类器之间存在依赖关系,各棵树之间是串行的,后面的分类器在拟合前面结果的残差。通过将每棵树的结果累加来决定最终的结果。
boosting开始对所有的样本赋予相同的权重,在每次训练结束后,对失败的样本赋予较大的权重,采样和上一轮的训练结果有关。
偏差 & 方差、
泛化误差:偏差+方差+噪声
偏差:训练得到所有模型输出的平均值和真实模型的输出值之间的差距
方差:由不同的训练集训练出的模型输出之间的差距。
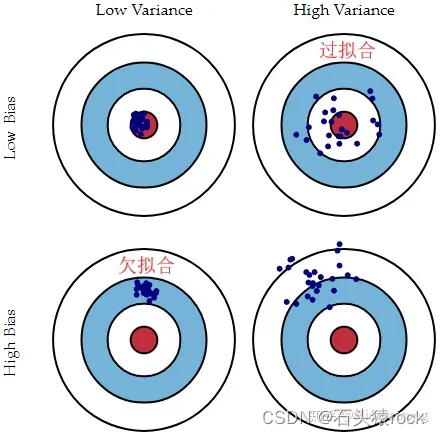
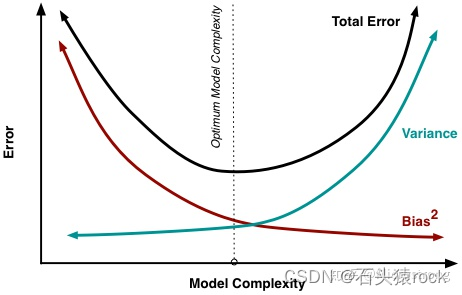
偏差,方差和bagging,boosting的关系
bagging是对训练样本进行采样,得到不同的训练子集,然后通过不同的训练子集得到多个分类器,然后取这些分类器的平均,实在降低模型的方差。
boosting是迭代算法,后面的在拟合前面结果的残差,是在降低模型的偏差。
如何衡量一颗树很好?目标函数
以xgboost为例,在构造每棵树的过程中,我们可以计算出目标函数的最小值,然后以这个最小值为准则来递归构建树的每一层节点。
GBDT和随机森林的区别
- 随机森林可以由回归树或分类树组成,GBDT只能由回归树组成
GDBT只能选择CART树,这是由于CART树的输出是一个分数,有助于优化算法 - 随机森林是有放回的均值采样,GBDT根据错误率来赋予权重的采样
- 随机森林的结果是通过投票表决的,GBDT的结果是将多颗树的结果累加确定的
- 随机森林中的树是并行生成的,GBDT中的树是串行生成的
- 随机森林是通过减小模型方差来提高性能,GBDT是通过减小模型的偏差来提高性能。
- 随机森林对异常值不敏感,GBDT对异常值非常敏感
xgboost
通过泰勒公式化简后的目标函数:
o
b
j
=
(
∑
i
n
g
i
)
w
j
+
1
2
(
∑
i
n
h
i
)
w
j
2
+
r
T
obj=(\sum_i^n g_i)w_j+\frac{1}{2}(\sum_i^nh_i)w_j^2+rT
obj=(∑ingi)wj+21(∑inhi)wj2+rT
通过求梯度我们可以找到最小的目标函数,构建第t颗树,计算Gain找到最好的分割点。
构建过程:
根据每一个特征对训练数据进行排序,保存为block结构,有多少个特征就有多少个block
在每个block内,根据目标函数下降最大,选择每个特征的最佳切割点,每个样本都计算出
g
i
,
h
i
g_i,h_i
gi,hi,然后通过找不同的切割点,计算出
G
L
,
G
R
G_L,G_R
GL,GR,然后计算出Gain,看Gain的正负看值不值得切分。
根据目标函数下降最大,选择最佳的特征分割点
GBDT和XGBOOST的区别:
- GBDT是机器学习算法,xgboost是算法的工程实现
- GBDT对损失函数的残差进行了一阶泰勒展开,xgboost进行了二阶泰勒展开
- xgboost对目标函数加入了正则化项,控制了模型的复杂度,缓解了模型过拟合的现象
- GBDT的基分类器只能选择CART树,xgboost还支持其他分类器
xgboost的并行化表现在在构建每颗树的时候,对于不同的特征,xgboost在不同的线程中去分裂,并选择收益最大的特征分割点
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











