







 本文介绍了使用Python、MySQL和FineBI快速搭建数据可视化的方法。先说明了数据来源,可通过开发者工具或天行API获取疫情数据;接着阐述了用Python和MySQL进行数据处理的过程;最后介绍了FineBI的安装、启动、数据载入、组件创建和联动等数据可视化操作。
本文介绍了使用Python、MySQL和FineBI快速搭建数据可视化的方法。先说明了数据来源,可通过开发者工具或天行API获取疫情数据;接着阐述了用Python和MySQL进行数据处理的过程;最后介绍了FineBI的安装、启动、数据载入、组件创建和联动等数据可视化操作。
数据可视化-python+MySQL+FineBI-快速搭建
目录
数据可视化-python+MySQL+FineBI-快速搭建
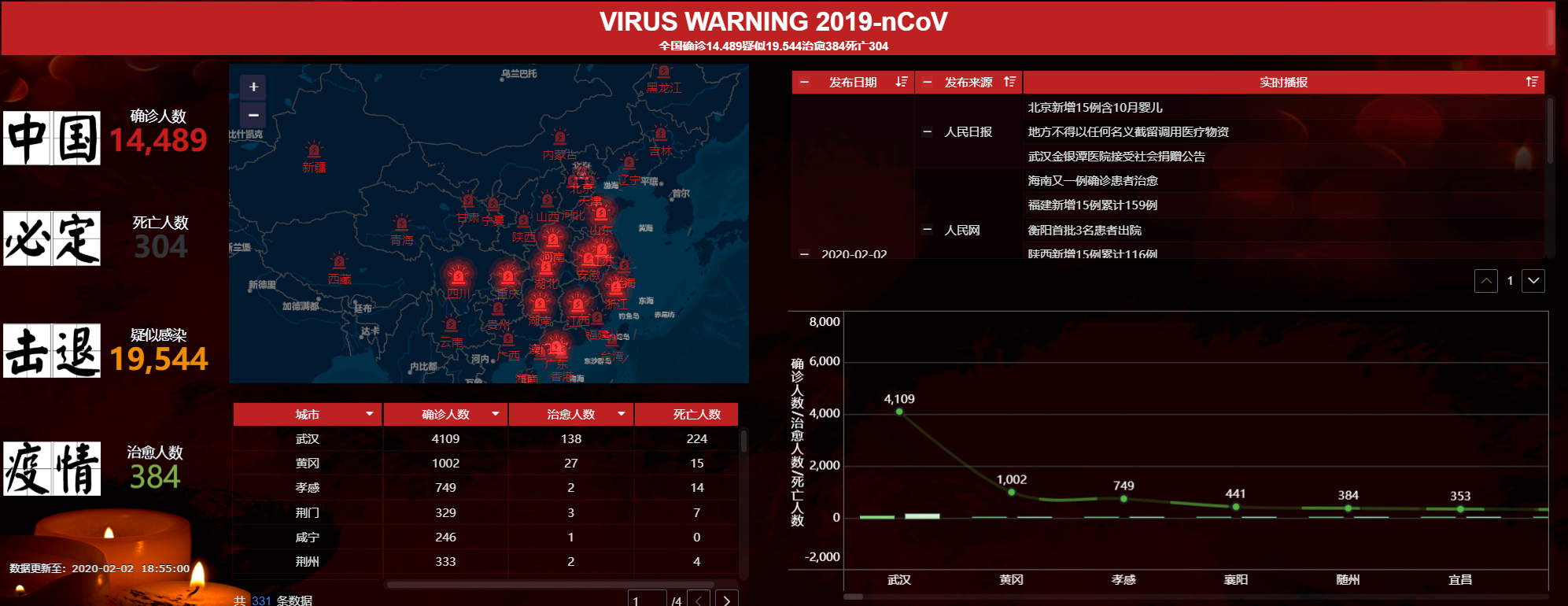
效果图
截图:
数据来源
如何查找数据
目前各大网站(BAT)都重点关注全国'疫情'情况,可以通过Chrome/Firefox开发者工具,去捕获查找,抓包都可以
本次的小demo我是直接使用天行API,目前免费注册,'疫情'数据API免费使用不限次数,做做练手比较方便,不用担心被封IP之类的情况发生啦。
如果不会找数据API的话,可以看看下面链接文章:
| Python实战:抓肺炎'疫情'实时数据,画2019-nCoV疫 情地图 | |
| 制作一个'疫情'地图(html+node) | |
| 如何用 Python 画出新型冠状病毒'疫情'地图? |
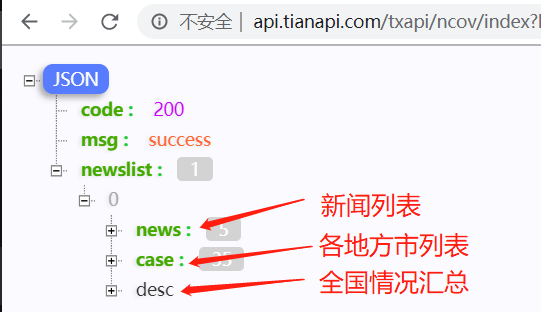
API数据分析-地方市
天行API的数据也是来自丁香园的数据,一共有2个API分别,地方市情况、省份情况,两个数据有时候不同步,甚至有点差别,使用的时候就细心的看看哈。
详细的就不说太多了,说了没有意义,多点去发掘问题解决问题,才是体验你为何掉头发的根本原因啊!
新闻列表,各地方市情况,全国情况数据分析,下列是我认为比较需要的数据,整理了一下,仅供参考,按照自己的实际情况处理即可。
| 新闻列表字段 | 各地市情况字段 | 全国情况字段 | |||
| id | id | id | |||
| pubDate | 发布时间 | createTime | createTime | ||
| pubDateStr | xxx前发布 | modifyTime | modifyTime | ||
| title | tags | infectSource | |||
| summary | 新闻简介 | provinceId | passWay | ||
| infoSource | provinceName | imgUrl | 地图 | ||
| sourceUrl | provinceShortName | dailyPic | 情况趋势图 | ||
| provinceId | cityName | summary | |||
| provinceName | confirmedCount | 确诊数 | virus | ||
| createTime | suspectedCount | 疑似数 | remark1 | 感染情况 | |
| modifyTime | curedCount | 治愈数 | remark2 | 感染症状 | |
| deadCount | 死亡数 | generalRemark | 数据来源说明 | ||
| comment | 备注 | ||||
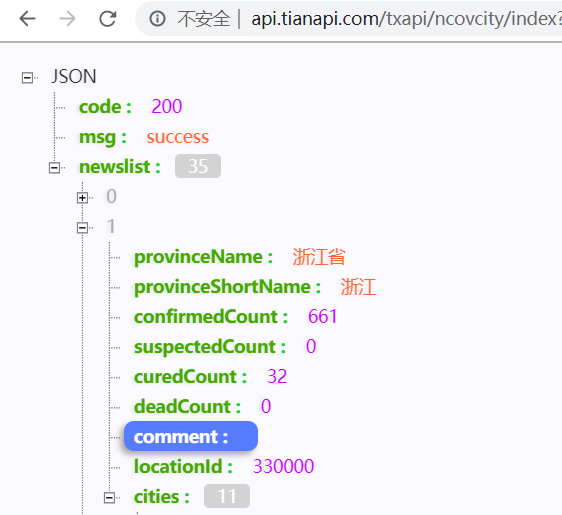
API数据分析-省份
省份列表数据,
| provinceName | |
| provinceShortName | |
| confirmedCount | 确诊数 |
| suspectedCount | 疑似数 |
| curedCount | 治愈数 |
| deadCount | 死亡数 |
| comment | 备注 |
| cities | 各城市情况,(字典 列表 字典嵌套) |
数据处理-python
人生苦短,我用python
API拿到的都是json,简单用python处理一下就好,反正就一句话,json,字典,列表,这些类型的数据直接for一下就好了,没有for不能处理的东西,只是你还没有想到for多少次而是,哪里不死就往死里弄,反正你要的数据总会来的,时间就是最好的经验了
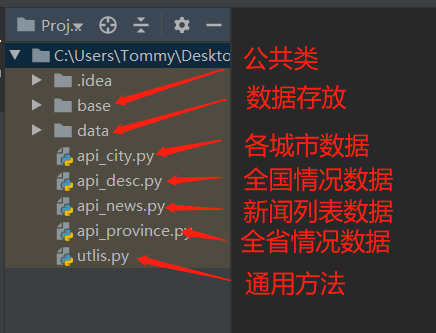
数据处理-目录结构
数据处理-思路分析
虽然API都是免费的,如果每次发起请求的话,操作比较慢,占用资源,造成不必要的浪费,所以总结了一下
| 访问API | 本地:省时,远程:消耗服务器 requests包 |
| 接收数据,写入为本地数据json | 轻量级存储,够用 |
| 直接读取本都数据json | python 处理方便 |
| 对本地数据json处理 | for循环就好了 、json包 |
| 处理后的数据写入MySQL | inset ,update基本sql语句、pymysql包 |
| FineBI读取MySQL数据,生成可视化图表 |
数据处理-公共类
总结:
怎样方便就怎样写,常用的,多次用的,很少有改变的,固定的写法,就先推在一起吧!
只要思想不滑坡,方法总比困难多!
import json
import pymysql
class BaseFun(object):
@staticmethod
def conn_database(data_name):
"""
连接数据库方法
:param data_name: 传入-数据库名称
:return: 连接后返回,conn
"""
conn = pymysql.connect(
host='localhost',
user='root',
password='root',
database=data_name,
charset='utf8')
print("连接数据库成功", conn.cursor())
return conn
@staticmethod
def city_url():
"""
各市级疫情数据api,只有城市情况
:return:city_url
"""
city_url = 'http://api.tianapi.com/txapi/ncovcity/index?key=替换你自己的key'
print('连接【各市级】疫情数据api,成功')
return city_url
@staticmethod
def prov_url():
"""
各省级疫情数据api,包含新闻,全汇总
:return: prov_rul
"""
prov_rul = 'http://api.tianapi.com/txapi/ncov/index?key=替换你自己的key'
print('连接【各省级】疫情数据api,成功')
return prov_rul
@staticmethod
def read_json(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
res_data = json.load(f)
print('读取数据成功')
return res_data
@staticmethod
def write_json(file_path, data):
with open(file_path, 'w', encoding='utf-8')as f:
json.dump(data, f)
print('写入数据成功')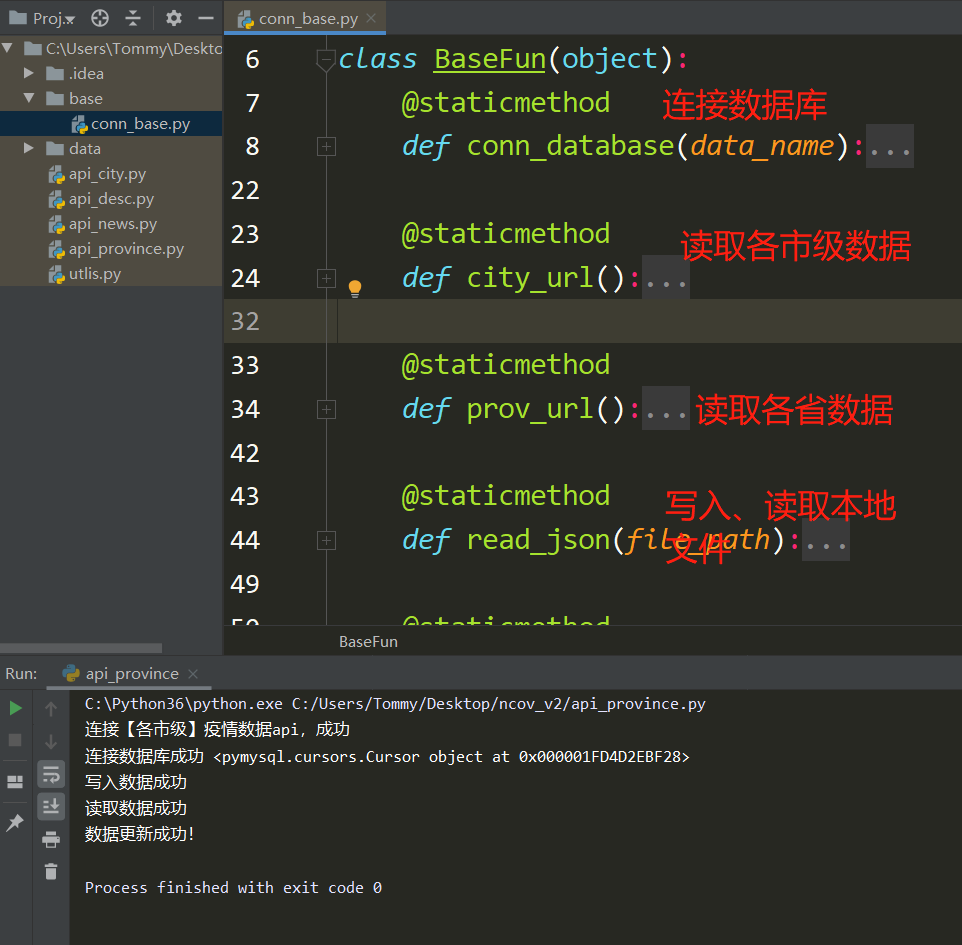
数据处理-全省数据
总结:
开始不停的调用公共类的方法,不停的for去处理数据
比较特别就是__main__的使用,和BASE_DIR路径处理,原因是数据存放的文件夹ncov_v2\data,直接在pycharm运行没有问题,如果在黑窗口运行就会报错,读取不了数据,原因是路径问题
# 获取当前文件的上一层绝对路径
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
import requests
from base.conn_base import BaseFun
from utlis import BASE_DIR
data_list = list()
class City(BaseFun):
url = BaseFun.city_url()
def __init__(self):
self.res_data = requests.get(self.url)
self.response_data = self.res_data.json()
self.conn = BaseFun.conn_database('ncov')
BaseFun.write_json(BASE_DIR + '/data/api_province_v2.json', self.response_data)
def read_data(self):
res_data = BaseFun.read_json(BASE_DIR + '/data/api_province_v2.json')
return res_data['newslist']
def data_4_list(self):
for res in self.read_data():
data_list.append([
res.get('provinceName'),
res.get('provinceShortName'),
res.get('confirmedCount'),
res.get('suspectedCount'),
res.get('curedCount'),
res.get('deadCount'),
res.get('comment'),
str(res.get('cities')),
])
def update_sql(self):
for i in range(len(data_list)):
self.sql = "update api_province_v2 set provinceName=%s, provinceShortName=%s, confirmedCount=%s, suspectedCount=%s, curedCount=%s, deadCount=%s, comment=%s, cities=%s where provinceShortName=" + '"' + \
data_list[i][1] + '"'
# 获取一个光标
self.conn.cursor()
# 连接并执行
self.conn.cursor().execute(self.sql, [data_list[i][0], data_list[i][1], data_list[i][2], data_list[i][3],
data_list[i][4],
data_list[i][5], data_list[i][6], data_list[i][7]])
# 涉及写操作注意要提交
self.conn.commit()
# 关闭光标对象
self.conn.cursor().close()
# 关闭数据库连接
self.conn.close()
if __name__ == '__main__':
update_data = City()
update_data.data_4_list()
update_data.update_sql()
print('数据更新成功!')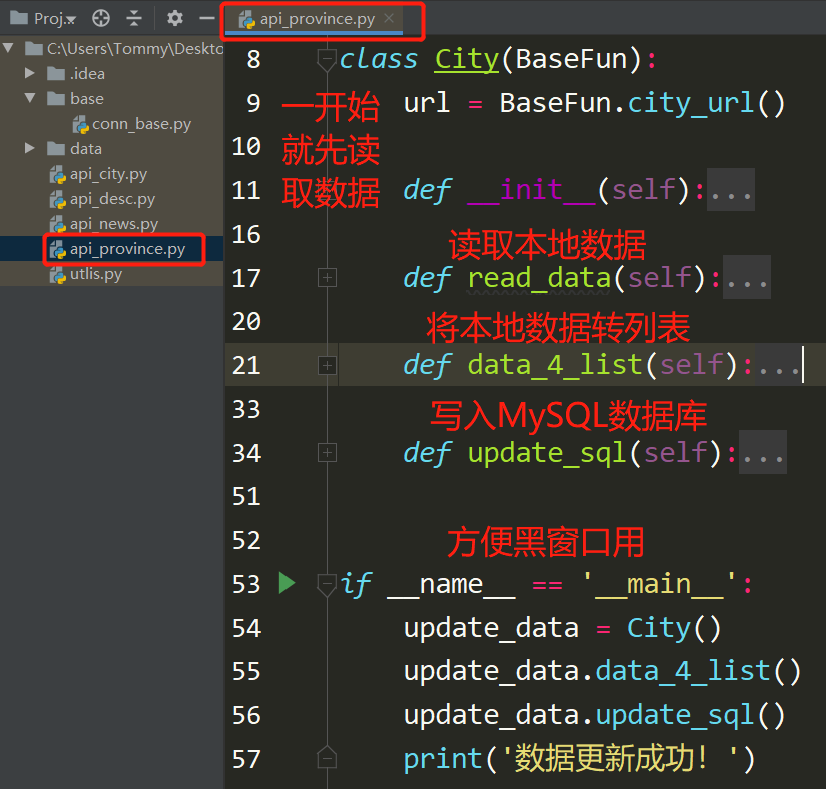
数据处理-新闻列表数据
总结:
写法和上一个差不多,思路都是一样的
唯一的就是这里,我写了一个小陷阱,哈哈哈
重点好似没有什么影响
import requests
from base.conn_base import BaseFun
from utlis import BASE_DIR, time_change
data_list = list()
class News(BaseFun):
url = BaseFun.prov_url()
def __init__(self):
self.res_data = requests.get(self.url)
self.response_data = self.res_data.json()
self.conn = BaseFun.conn_database('ncov')
BaseFun.write_json(BASE_DIR + '/data/api_desc.json', self.response_data)
def read_data(self):
res_data = BaseFun.read_json(BASE_DIR + '/data/api_desc.json')
return res_data['newslist'][0]['news']
def insets_sql(self):
for res in self.read_data():
if 'provinceName' in res.keys():
# 更新sql语句
sql = "INSERT INTO api_news (id, pubDate, pubDateStr, title, summary,infoSource,sourceUrl, provinceId, provinceName, createTime,modifyTime) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ON DUPLICATE KEY UPDATE id = id"
# 获取一个光标
cursor = self.conn.cursor()
# 连接并执行
cursor.execute(sql, [res['id'], time_change(res['pubDate']), res['pubDateStr'], res['title'],
res['summary'], res['infoSource'], res['sourceUrl'], res['provinceId'],
res['provinceName'], time_change(res['createTime']),
time_change(res['modifyTime'])])
else:
sql = "INSERT INTO api_news (id, pubDate, pubDateStr, title, summary,infoSource,sourceUrl, provinceId, createTime, modifyTime) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ON DUPLICATE KEY UPDATE id = id"
# 获取一个光标
cursor = self.conn.cursor()
cursor.execute(sql, [res['id'], time_change(res['pubDate']), res['pubDateStr'], res['title'],
res['summary'], res['infoSource'], res['sourceUrl'], res['provinceId'],
time_change(res['createTime']),
time_change(res['modifyTime'])])
# 涉及写操作注意要提交
self.conn.commit()
# 关闭光标对象
cursor.close()
# 关闭数据库连接
self.conn.close()
if __name__ == '__main__':
insets_data = News()
insets_data.insets_sql()
print('数据更新成功!')数据处理-全国情况数据
总结:
增加一个ccTime的数字字段,存入当天的年月日,确保当日只有一条数据,desc字段的数据有更新,具体下面有说明,增加了较昨日对比的数据
from datetime import datetime
import requests
from base.conn_base import BaseFun
from utlis import BASE_DIR, time_change
data_list = list()
now = datetime.now()
formatted_date = now.strftime('%Y-%m-%d')
class Desc(BaseFun):
url = BaseFun.prov_url()
def __init__(self):
self.res_data = requests.get(self.url)
self.response_data = self.res_data.json()
self.conn = BaseFun.conn_database('ncov')
BaseFun.write_json(BASE_DIR + '/data/api_desc.json', self.response_data)
def read_data(self):
res_data = BaseFun.read_json(BASE_DIR + '/data/api_desc.json')
return res_data['newslist'][0]['desc']
def data_4_list(self):
for res in self.read_data():
data_list.append(self.read_data()[res])
print(data_list)
def insets_sql(self):
sql = "INSERT INTO api_desc (createTime,modifyTime,infectSource,passWay,imgUrl,dailyPic,countConfirmedCount,countSuspectedCount,countCuredCount,countDeadCount,virus,remark1,remark2,generalRemark,ccTime) " \
"VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) " \
"ON DUPLICATE KEY UPDATE ccTime=%s,modifyTime=%s,countConfirmedCount=%s,countSuspectedCount=%s,countCuredCount=%s,countDeadCount=%s"
# 获取一个光标
self.conn.cursor()
# 连接并执行
int_val = (time_change(data_list[1]), time_change(data_list[2]), data_list[3], data_list[4],
data_list[5], data_list[6], data_list[10], data_list[11], data_list[12], data_list[13],
data_list[20], data_list[21], data_list[22],
data_list[26], formatted_date)
upd_val = (formatted_date, time_change(data_list[2]), data_list[10],
data_list[11], data_list[12], data_list[13])
val = (*int_val, *upd_val)
self.conn.cursor().execute(sql, val)
# 涉及写操作注意要提交
self.conn.commit()
# 关闭光标对象
self.conn.cursor().close()
# 关闭数据库连接
self.conn.close()
if __name__ == '__main__':
insets_data = Desc()
insets_data.data_4_list()
insets_data.insets_sql()
print('数据更新成功!')API的数据新增,seriousCount严重病例,和较昨日对比数据字段suspectedIncr,confirmedIncr,curedIncr,deadIncr,seriousIncr

数据处理-地方市数据
总结:
地方市的数据来自,省份数据cities字段,所以一开始直接读取省份json,进行数据重新整理,并生成新的city.json,执行读写和写入数据库
from base.conn_base import BaseFun
from utlis import BASE_DIR
city_list = list()
class City(BaseFun):
def __init__(self):
self.conn = BaseFun.conn_database('ncov')
self.res_data = BaseFun.read_json(BASE_DIR + '/data/api_province_v2.json')
def data_4_list(self):
for i in self.res_data['newslist']:
for j in i['cities']:
# 城市名称列表
# print(j)
city_list.append(j)
print('本地数据处理成功!')
def write_data(self):
BaseFun.write_json(BASE_DIR + '/data/api_city.json', city_list)
def read_data(self):
res_datas = BaseFun.read_json(BASE_DIR + '/data/api_city.json')
return res_datas
def update_sql(self):
for res in self.read_data():
sql = "update api_city set confirmedCount=%s, suspectedCount=%s, curedCount=%s, deadCount=%s where cityName =%s"
# 获取一个光标
self.conn.cursor()
# 连接并执行
self.conn.cursor().execute(sql, [res['confirmedCount'], res['suspectedCount'], res['curedCount'],
res['deadCount'],
res['cityName']])
# 涉及写操作注意要提交
self.conn.commit()
# 关闭光标对象
self.conn.cursor().close()
# 关闭数据库连接
self.conn.close()
if __name__ == '__main__':
update_data = City()
update_data.data_4_list()
update_data.write_data()
update_data.read_data()
update_data.update_sql()
print('数据更新成功!')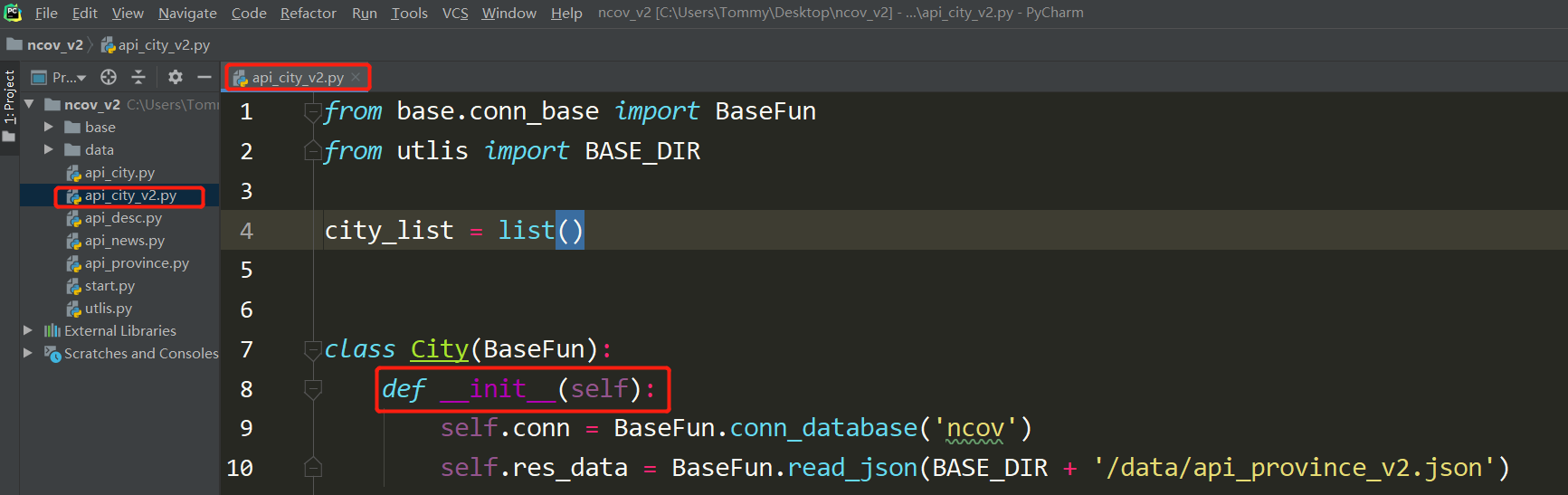
数据处理-统一调动
总结:
每个py文件都需要单独执行一次,才能写入数据到数据库,为了方便每个api*.py都增加一个start方法自调用,根目录增加一个start.py调动所有api接口
from api_city import City
from api_desc import Desc
from api_news import News
from api_province import Prov
class Start(object):
def __init__(self):
Prov().start()
print('全省数据更新-成功')
News().start()
print('新闻数据更新-成功')
Desc().start()
print('全国数据更新-成功')
City().start()
print('全市数据更新-成功')
print('--------------')
print('全数据更新-成功')
if __name__ == '__main__':
Start()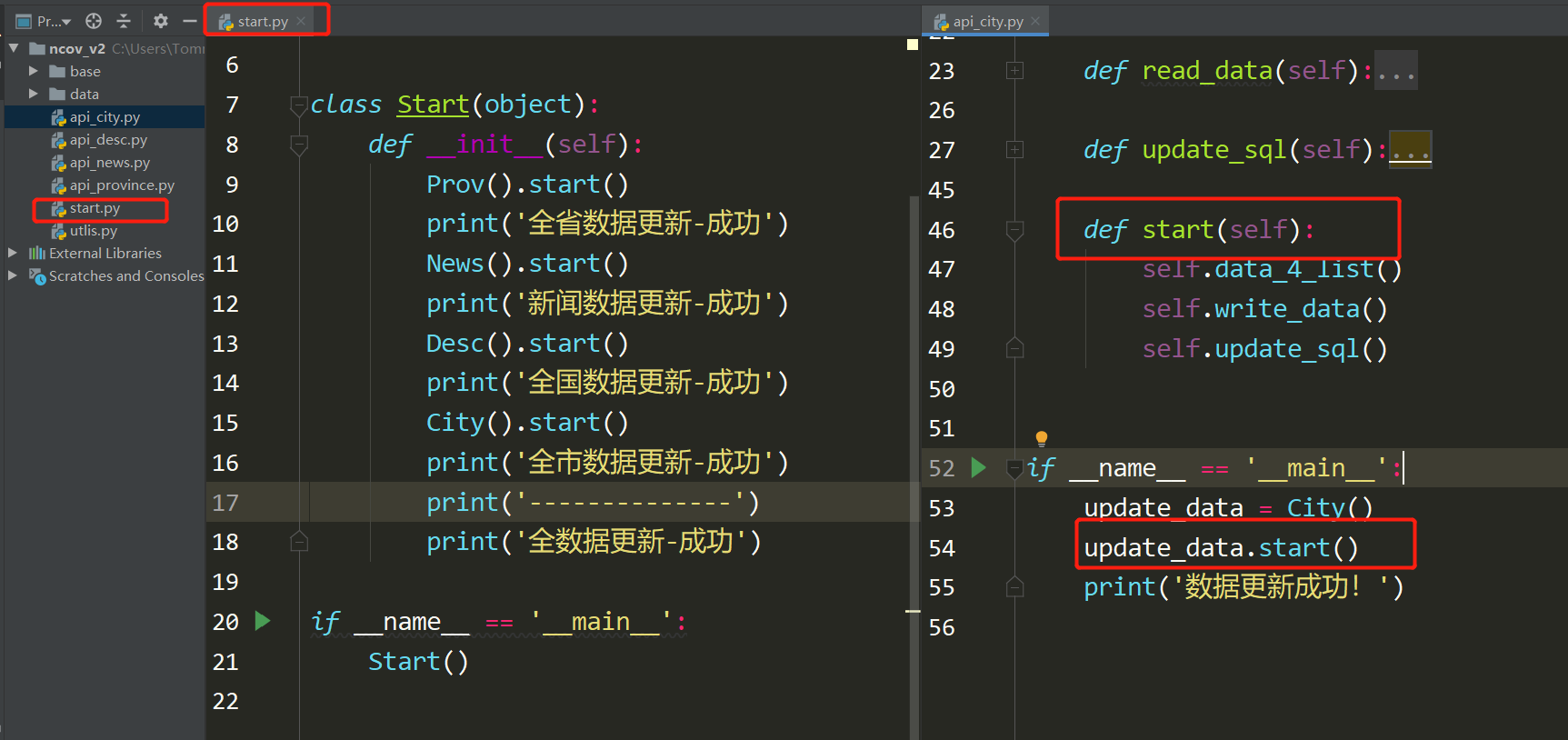
数据处理-MySQL
黑窗口操作太难了,直接使用Navicat操作数据库吧!
数据处理-目录结构SQL

数据处理-全省数据SQL
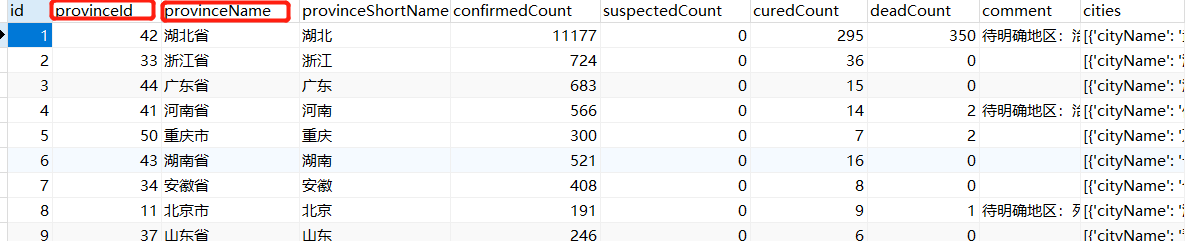
总结:provinceId,provinceName需要自行添加这个来个字段的数据,否则后期数据可视化无法实现联动显示
CREATE TABLE `api_province_v2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`provinceId` int(11) DEFAULT NULL,
`provinceName` varchar(15) DEFAULT NULL,
`provinceShortName` varchar(15) DEFAULT NULL,
`confirmedCount` int(11) DEFAULT NULL,
`suspectedCount` int(11) DEFAULT NULL,
`curedCount` int(11) DEFAULT NULL,
`deadCount` int(11) DEFAULT NULL,
`comment` varchar(255) DEFAULT NULL,
`cities` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=35 DEFAULT CHARSET=utf8;
数据处理-新闻列表数据SQL
总结:
还是上面python处理的时候那个坑,哈哈哈
CREATE TABLE `api_news` (
`id` int(11) NOT NULL,
`pubDate` varchar(255) DEFAULT NULL,
`pubDateStr` varchar(255) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
`summary` text,
`infoSource` varchar(255) DEFAULT NULL,
`sourceUrl` text,
`provinceId` varchar(11) DEFAULT NULL,
`provinceName` varchar(255) DEFAULT NULL,
`createTime` varchar(255) DEFAULT NULL,
`modifyTime` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
数据处理-全国情况数据SQL
总结:
每天只有一条总数据,ccTime
CREATE TABLE `api_desc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`createTime` varchar(255) DEFAULT NULL,
`modifyTime` varchar(255) DEFAULT NULL,
`infectSource` varchar(255) DEFAULT NULL,
`passWay` varchar(255) DEFAULT NULL,
`imgUrl` varchar(255) DEFAULT NULL,
`dailyPic` varchar(255) DEFAULT '',
`summary` varchar(255) DEFAULT NULL,
`deleted` varchar(255) DEFAULT NULL,
`countRemark` varchar(255) DEFAULT NULL,
`countConfirmedCount` varchar(255) DEFAULT NULL,
`countSuspectedCount` varchar(255) DEFAULT NULL,
`countCuredCount` varchar(255) DEFAULT NULL,
`countDeadCount` varchar(255) DEFAULT NULL,
`virus` varchar(255) DEFAULT NULL,
`remark1` varchar(255) DEFAULT NULL,
`remark2` varchar(255) DEFAULT NULL,
`remark3` varchar(255) DEFAULT NULL,
`remark4` varchar(255) DEFAULT NULL,
`remark5` varchar(255) DEFAULT NULL,
`generalRemark` varchar(255) DEFAULT NULL,
`ccTime` varchar(255) NOT NULL,
PRIMARY KEY (`id`,`ccTime`),
UNIQUE KEY `ctime` (`ccTime`)
) ENGINE=InnoDB AUTO_INCREMENT=23 DEFAULT CHARSET=utf8;
数据处理-地方市数据SQL
总结:
provinceId,provinceName联动字段和全省的数据关联
CREATE TABLE `api_city` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cityName` varchar(255) DEFAULT NULL,
`confirmedCount` varchar(255) DEFAULT NULL,
`suspectedCount` varchar(255) DEFAULT NULL,
`curedCount` varchar(255) DEFAULT NULL,
`deadCount` varchar(255) DEFAULT NULL,
`provinceId` int(11) DEFAULT NULL,
`provinceName` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=332 DEFAULT CHARSET=utf8;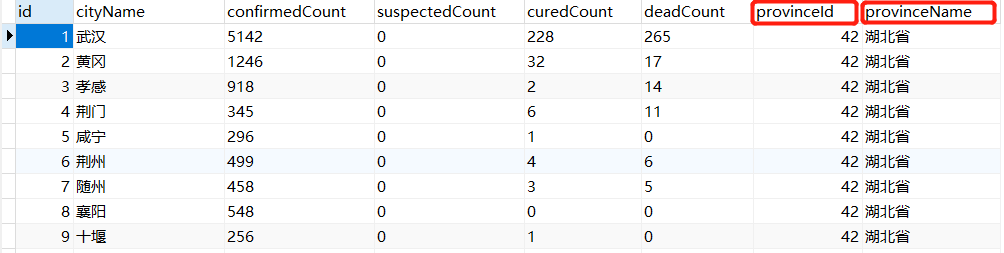
数据应用
嗯嗯,过年啊,只能在家里,都快要长蘑菇了,看见哪些一张张的大数据,手有点痒,在x度看了一下数据可视化,然鹅有很多开源和免费的可视化工具,选了FineBI,就是免费、模板多可以满足目前的需求,而且简单~~
数据可视化-安装
这里不说,建议你看官方文档
数据可视化-启动
安装完直接双击FineBI启动
启动过程:

启动完成:

数据可视化-数据载入
- FineBI登录成功之后,第一步创建数据
- 添加本地数据
- 对数据表的字段进行设置,数值,日期优先作为数据指标,该设置不影响真实数据库
修改字段:

最终字段:

数据可视化-组件创建
- 数据准备好,点击右上角【创建组件】,官方文档有教程的

- 将准备好数据字段拖动到对应的位置
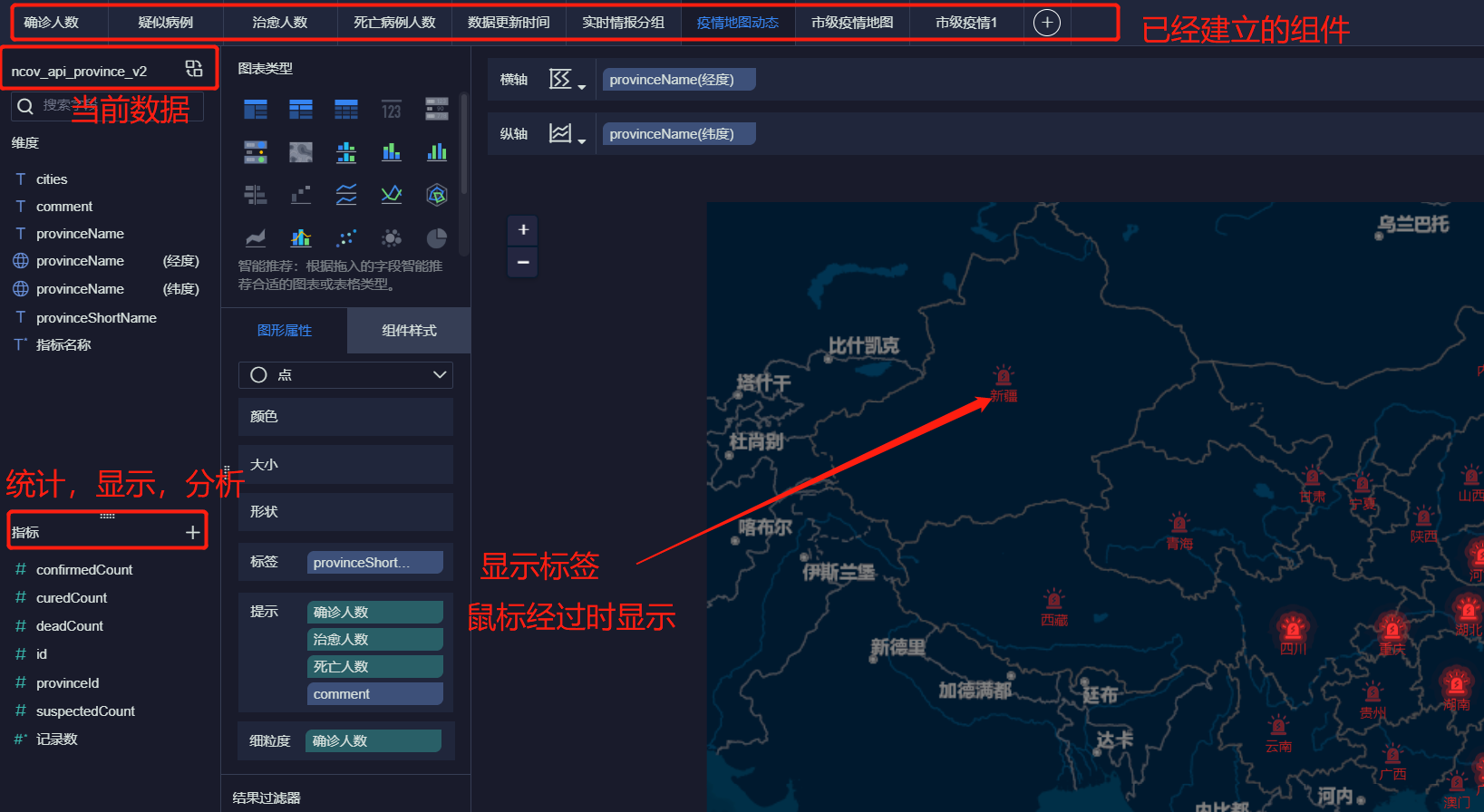
数据可视化-组件联动
- 设置联动,如果数据来自同一个数据表会自己联动的,如果来自其他数据就需要自定处理,关联一下,类似MySQL的inner join的用法
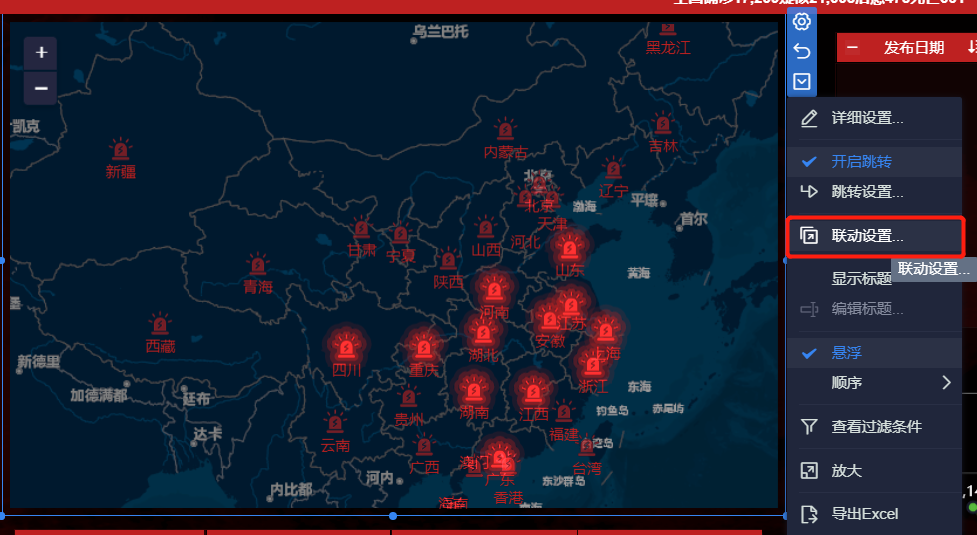
- 自定义联动设置(有勾选的代表已经联动)
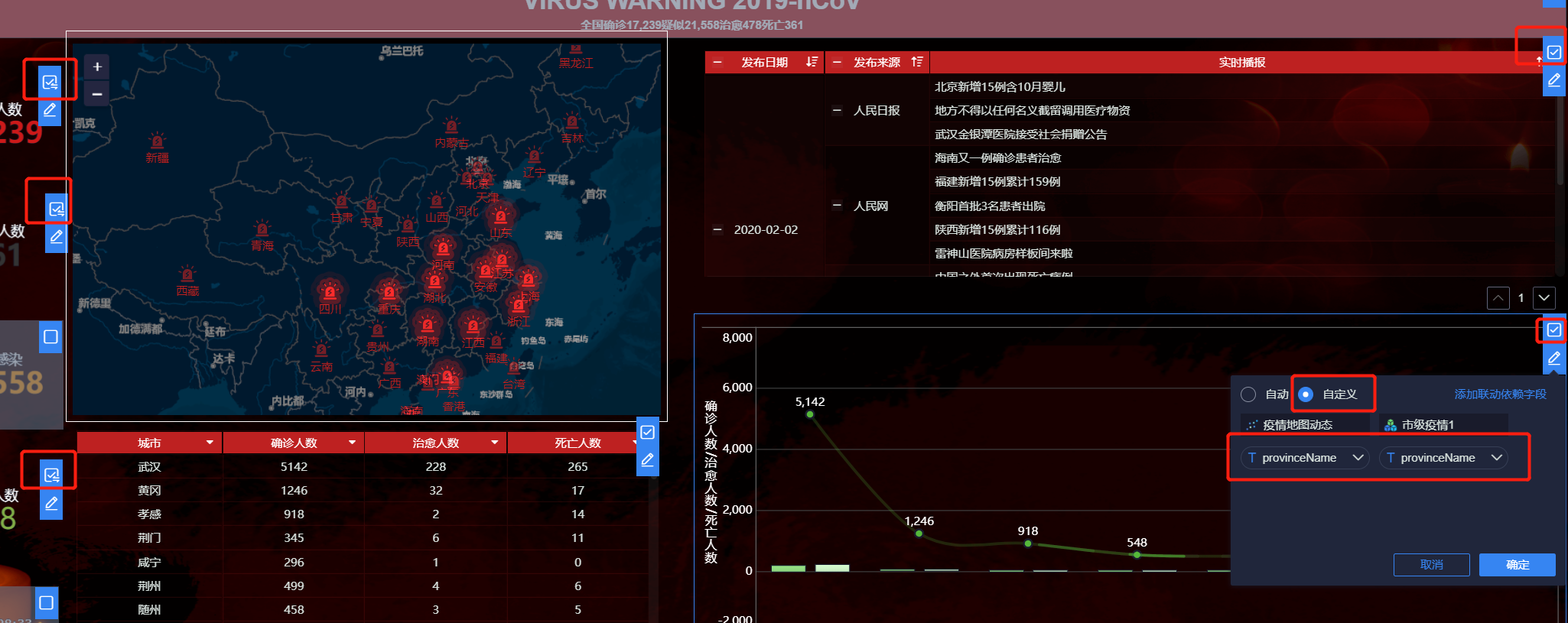
总结:
完!
python代码已经上传git

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









