







 本文介绍了Neo4j数据库中的一些关键函数用法,包括字符串函数如TOUPPER、TOLOWER和SUBSTRING,聚合函数如COUNT、MAX、MIN、SUM和AVG,以及关系函数STARTNODE、ENDNODE、ID、TYPE和COLLECT。这些函数在查询和操作图数据时非常实用。
本文介绍了Neo4j数据库中的一些关键函数用法,包括字符串函数如TOUPPER、TOLOWER和SUBSTRING,聚合函数如COUNT、MAX、MIN、SUM和AVG,以及关系函数STARTNODE、ENDNODE、ID、TYPE和COLLECT。这些函数在查询和操作图数据时非常实用。
Neo4j 函数使用手册
1. 字符串函数
1.1 TOUPPER 函数 : 转换为大写
- upper 函数高版本不支持使用
-- 创建节点
create (t:Teacher {name:'Anna',sex:'女',subject:'英语'}) return t
-- upper函数使用
match (t:Teacher)
where t.name = 'Anna'
return toupper(t.name), t.sex, t.subject
1.2 TOLOWER 函数 : 转换为小写
- lower 函数高版本不支持使用
match (t:Teacher)
where t.name = 'Anna'
return tolower(t.name), t.sex, t.subject
1.3 SUBSTRING 函数 : 字符串截取
在Neo4j的CQL,如果一个字符串包含N个字母,那么它的长度为n和指数从0开始,并在N-1结束。
startIndex : 是指数值子字符串函数。
endIndex : 是可选的。 如果我们忽略它,则返回从startIndex到指定的字符串结束的字符串的子字符串。
SUBSTRING(<input-string>,<startIndex> ,<endIndex>)
示例:
match (t:Teacher)
return substring(t.name, 0, 10)
2. 聚合函数
2.1 count 函数
match (t:Teacher) return count(t), count(*)
2.2 max 函数
match (t:Teacher) return max(t.id)
2.3 min 函数
match (t:Teacher) return min(t.id)
2.4 sum 函数
match (t:Teacher) return sum(t.id)
2.5 avg 函数
match (t:Teacher) return avg(t.id)
3. 关系函数
STARTNODE (<relationship-label-name>)
3.1 STARTNODE : 用于知道关系的开始节点
match (t) - [tc:teacher_class] -> (c)
return startnode(tc)

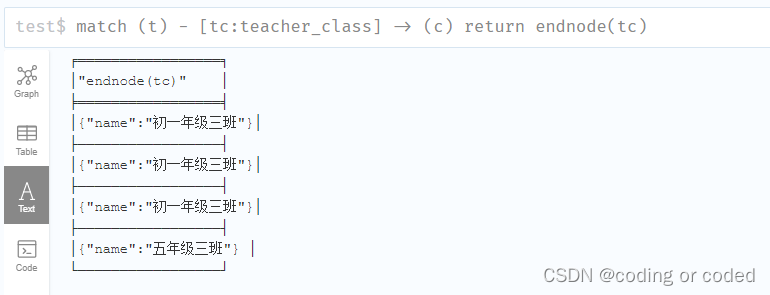
3.2 ENDNODE : 用于知道关系的结束节点
match (t) - [tc:teacher_class] -> (c)
return endnode(tc)
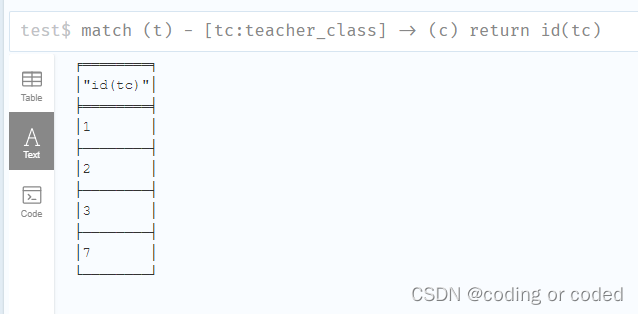
3.3 ID : 用于知道关系的ID
match (t) - [tc:teacher_class] -> (c)
return id(tc)
3.4 TYPE : 用于知道字符串表示中的一个关系的TYPE
match (t) - [tc:teacher_class] -> (c)
return type(tc)

3.5 COLLECT : 集合
-- class的name集合
match (c:Class) return collect(c.name)
-- class的name 去重集合
match (c:Class) return collect(distinct c.name)

















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









