






字符串里面存储字符类型的 不可变的 序列 容器 只有查询的功能 没有增删改
访问字符
字符 = 字符串[索引]
出部分字符(切片)
子字符串= 字符串[开始:结束:步长]
步长也可以是负数: 为负数时倒序截取.
判断

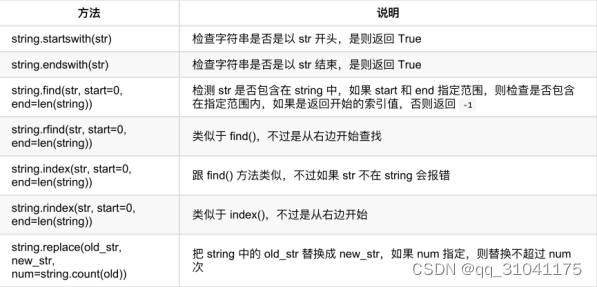
查找和替换
大小写转换

拆分和连接

去除空⽩字符

什么是转义字符
通过\可以将无意义的字符转换为具有指定功能的字符.
例如:
\n: 代码换行
\t: 代表制表符(tab键)
\: 代表\字符 ': 表示普通的单引号 ": 表示普通的双引号
字符串的编码
编码值:计算机存储数据的时候只能存数字(存的是数字对应的二进制的补码)
为了能够让计算机存储字符,给每个字符对应一个固定的数字,每次需呀存储这个字符的时候就去存这个数字
编码表:ASSII码 : 有128个字符对应的编码值(只要包含英文符号和其他西欧语言对应的符号)
数字字符0-9从48开始连续递增
大写字母A-Z从65开始连续递增
小写字母a-z从97开始连续递增
UNICODE码 (统一码 万国码) ASSII码的扩展 包含了世界上所有国家所有语言对应的符号
python程序对于编码值的应用
1)chr(编码值) 获取指定编码值的字符 通过编码值获取字符
for i in range(65,65+26):
print(chr(i))
在程序里面加上0x就可以转十六进制 assii码
print(chr(0x4e00))
for i in range(0x4e00,0x9fa5+1): # 查看所有的中文
print(chr(i),end=’ ')
2)ord() 字符 获取指定字符对应的编码 只能是长度为1的字符串 大于1 或者 小于1 都不行
3)编码字符
编码字符 \u四位的十进制数 -->\u四位的十六进制数
编码值转化成16进制数 程序中给字符串提供字符的时候有两种方式: a.直接提供符号本身 b.通过字符对应的编码字符来提供(\u四位的十六进制数)
使用场景: 知道编码值 但是 不知道字符是什么
print(“在unicode编码表中最后一个中文是什么,‘\u9fa5’”) # 0000-ffff
字符串的分割(重点)
string.split() 按照空格字符串分割,返回一个列表
string.split(“分隔符”) 按照指定分隔符分割,返回一个列表
string.split(“分隔符”,分割次数) 按照指定分隔符分割,分割指定的次数,返回一个列表
string.rsplit(“分隔符”,分割次数) 从后面开始按照指定分隔符分割,分割指定的次数,返回一个列表
判断开头或者结尾的字符
string.startswith(“开头字符”)
string.endswith(“结尾字符”)
字符串替换
string.replace(“原文”,“替换文”)
将字符串中的原文替换成 替换的文字
字符串连接
string.join(列表)
列表中的元素使用string连接起来
判断字符串由数字组成
string.isdigit()
while遍历字符
索引= 0;
长度 = len(字符串)
while 索引 < 长度:
元素 = 字符串[索引]
索引+=1
for 字符 in 字符串:
print(字符)
字符串的查询
字符串的获取字符的语法和列表获取元素是一样
1)获取单个元素
str_one=‘one one one’
print(str_one[1],str_one[-1])
*** 不管转义字符的功能是什么 在计算字符串长度的时候 一个转义字符的长度是1
str_two = ‘\tabc\n123\u4e08m’
print(str_two[1], str_two[-1])
2)切片 和列表的切片是一样的
message = ‘我的电话号码死:15283141714’
x = print(message[-11:])
字符串的添加/提取
通过字符串的拼接
str_join = ‘a09b8a56sj12o1212’
new_str = ‘’
for i in str_join:
if ‘0’<i<‘9’:
new_str+=i
print(new_str)
留下的条件过滤带空字符串里面就可以了
练习:将字符串中所有的数字字符都替换成*
str_1 = ‘ab2Mk89你好8’ # -> ‘abMk**你好’
new_str = ‘’
for i in str_1:
if ‘0’ < i < ‘9’:
i = ‘*’
new_str += i
else:
new_str += i
print(new_str)
可变的数据类型:
不可变的数据类型:
比较运算: > < >= <= == !=
1)判断相等: 两个一模一样的字符串才相等
print(‘abcc’==‘cbac’) # false
2)比较大小:两个字符串比较大小,比较的是一对相等字符的编码值大小
#练习:统计字符串中中文和大写字母的数量
str1 = ‘shfa换手机223–=2MjshUj行HSJSA’
ch_str = ‘’
count = 0 # 出现的数量
A_str = ‘’
a_str = ‘’
n_str = ‘’
for i in str1:
if ‘0’ < i < ‘9’:
n_str += i
count += 1
elif ‘A’ < i < ‘Z’:
A_str += i
elif ‘a’ < i < ‘z’:
a_str += i
elif ‘\u4e00’ < i < ‘\u9fa5’:
ch_str += i
print(ch_str, A_str, a_str, n_str,count)
3) in 和 not in
字符串1 in 字符串2 --判断字符串1是否在字符串2的子串 一定是整体全部包含在里面
字符串 所有的数据都能转
字符串1 in 字符串2 - 判断字符串1是否是字符串2的子串(判断字符串2中是否包含字符串1)
print(10 in [10, 20, 30]) # True
print([10, 20] in [10, 20, 30]) # False
print(‘a’ in ‘abc123’) # True
print(‘abc’ in ‘abc123’) # True
print(‘ab1’ in ‘abc123’) # False
str(数据) - 将指定数据转换成字符串
所有类型的数据都可以转换成字符串,转换的时候是在数据的打印值外面加引号
print(100)
str(100) # ‘100’
list1 = [10,20,30]
print(list1) # [10, 20, 30]
str(list1) # ‘[10, 20, 30]’
list2 = [“abc”, 100]
print(list2)
str(list2) # “[‘abc’, 100]”
dict1 = {“a”:10,‘b’:20, ‘c’:“abc”}
print(dict1)
str(dict1) # “{‘a’: 10, ‘b’: 20, ‘c’: ‘abc’}”
字符串的切割
str_1 = ‘how are you? i am fine! thank you! and you?’
print(str_1.replace(‘you’, ‘me’))
print(str_1.replace(‘you’, ‘me’, 1)) # 后面加一个1 就是替换1次的意思
str_1 = ’ how are you? i am fine! thank you! and you?’
print(str_1.replace(’ ', ‘’)) # 后面加一个1 就是替换1次的意思
1. 必须掌握的字符串相关方法(一级)
1) 字符串.join(序列) - 用指定字符串将序列中元素拼接成一个字符串(序列中的元素必须是字符串)
result = ‘+’.join([‘name’, ‘age’, ‘gender’])
print(result) # name+age+gender
result = ''.join(‘abc’)
print(result) # ab==c
nums = [10, 20, 30, 40]
‘10+20+30+40’
result = ‘+’.join([str(x) for x in nums])
print(result) # ‘10+20+30+40’
list1 = [10, ‘abc’, ‘你好’, 1.23, True, ‘手机壳’]
‘abc你好手机壳’
result = ‘’.join([x for x in list1 if type(x) == str])
print(result) # ‘abc你好手机壳’
练习:将列表中每个元素的第一个字符提取出来形成一个新的字符串:
[‘name’, ‘age’, ‘gender’] -> ‘nag’
list1 = [‘name’, ‘age’, ‘gender’]
result = ‘’.join([x[0] for x in list1])
print(result)
2) split
字符串1.split(字符串2) - 将字符串1中所有的字符串2作为切割点对字符串1进行切割
字符串1.split(字符串2, N) - 将字符串1中前N个字符串2作为切割点对字符串1进行切割
str1 = ‘123abc你好abc=abc+++’
result = str1.split(‘abc’)
print(result) # [‘123’, ‘你好’, '=’, ‘+++’]
result = str1.split(‘a’)
print(result) # [‘123’, ‘bc你好’, ‘bc===’, ‘bc+++’]
result = str1.split(‘abc’, 2)
print(result) # [‘123’, ‘你好’, ‘===abc+++’]
注意:如果切割点连续出现或者切割点在字符串的开头或者结果,切割的结果中会出现空串
str1 = ‘abc123abcabc你好abc=abc+++abc’
result = str1.split(‘abc’)
print(result) # [‘’, ‘123’, ‘’, ‘你好’, '=’, ‘+++’, ‘’]
3)
字符串1.replace(字符串2, 字符串3) - 将字符串1中所有的字符串2都替换成字符串3
字符串1.replace(字符串2, 字符串3, N) - 将字符串1中前N个字符串2都替换成字符串3
message = ‘how are you? i am fine! thank you! and you?’
result = message.replace(‘you’, ‘me’)
print(result) # how are me? i am fine! thank me! and me?
result = message.replace(‘you’, ‘me’, 1)
print(result) # how are me? i am fine! thank you! and you?
案例:删除字符串message中所有的空格符号
result = message.replace(’ ', ‘’)
print(result) # howareyou?iamfine!thankyou!andyou?
4)
字符串.strip() - 删除字符串前后两端的空白字符
字符串.strip(字符集) - 删除字符串前后两端的指定所有字符
str1 = ‘’’
你 好,世 界
'''
result = str1.strip()
print(result)
print(‘====’)
str2 = ‘/+//u/重/庆a++///++//’
result = str2.strip(‘/+’)
print(result)
字符串1.find(字符串2) - 获取字符串2第一次出现在字符串1中的位置,如果字符串2不存在返回-1
字符串1.index(字符串2) - 获取字符串2第一次出现在字符串1中的位置,如果字符串2不存报错
message = ‘how are you? i am fine! thank you! and you?’
print(message.find(‘you’), message.index(‘you’))
print(message.find(‘abc’)) # -1
print(message.index(‘abc’)) # 报错
字符串1.find(字符串2, 开始下标, 结束下标) - 在字符串1中指定范围内查找字符串2第一次出现的位置, 如果找不到返回-1
字符串1.index(字符串2, 开始下标, 结束下标) - 在字符串1中指定范围内查找字符串2第一次出现的位置, 如果找不到报错
message = ‘how are you? i am fine! thank you! and you?’
print(message.find(‘you’, 0, 8)) # -1
print(message.find(‘you’, 11)) # 30
字符串1.rfind(字符串2) - (从后往前找)
字符串1.rindex(字符串2) - (从后往前找)
message = ‘how are you? i am fine! thank you! and you?’
print(message.rfind(‘you’)) # 39















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









