







暴力实现的复杂度:
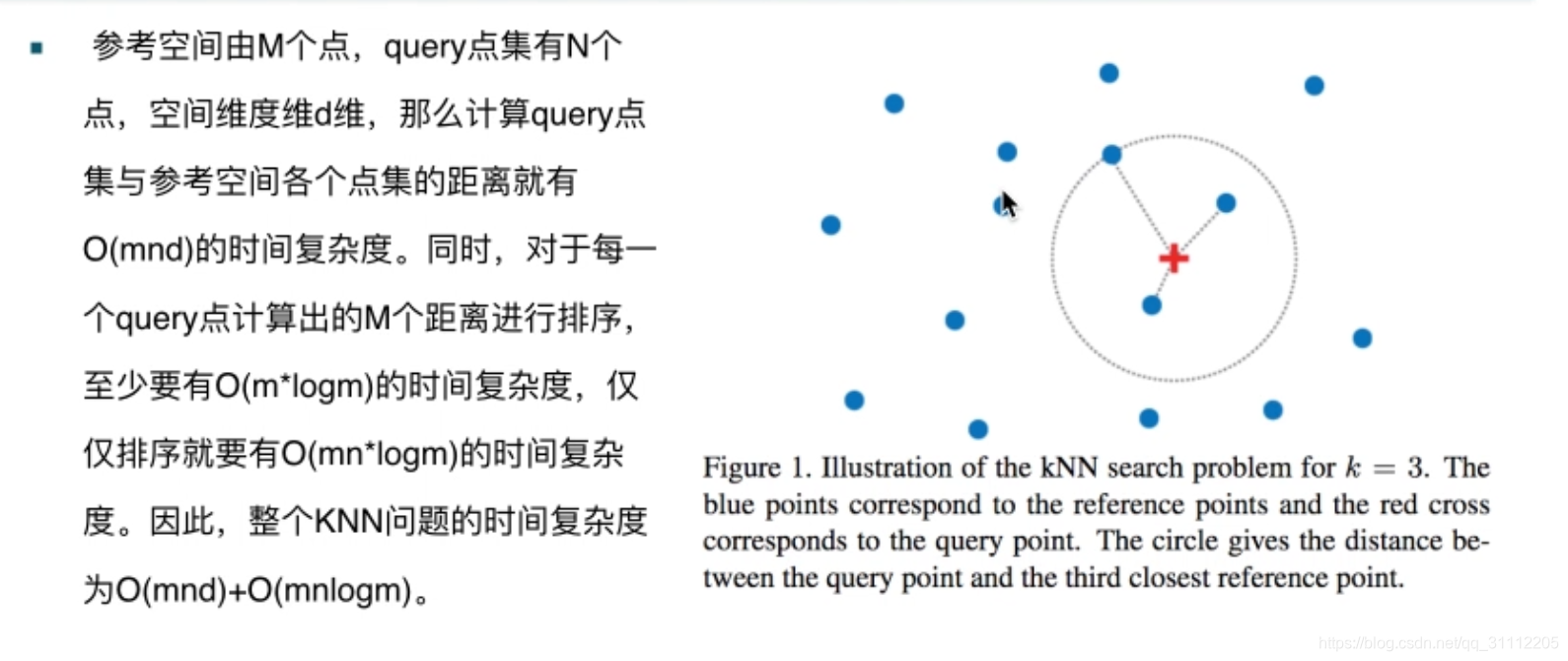
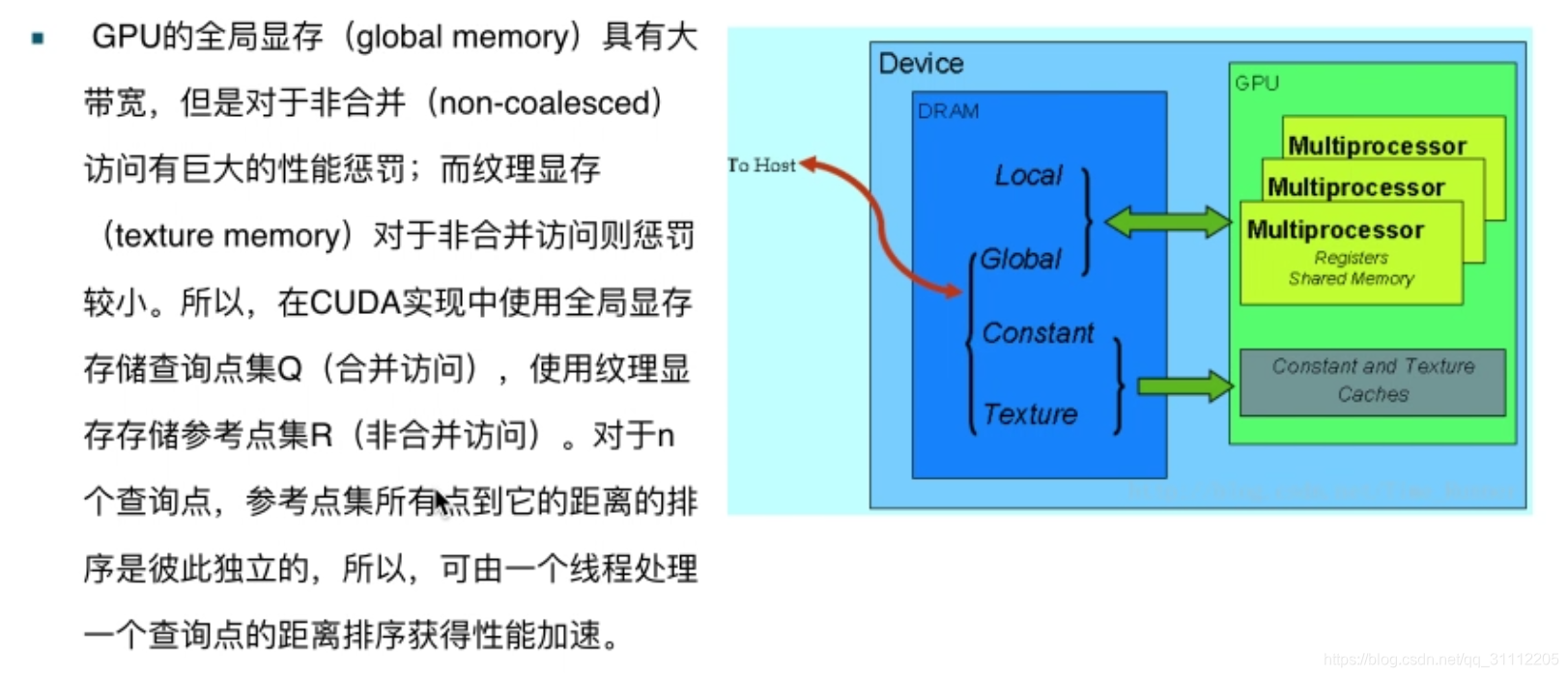
实现分析:
完整的代码:
Ubuntu运行命令:
nvcc -o knn_cuda_with_indexes.exe knn_cuda_with_indexes.cu -lcuda -D_CRT_SECURE_NO_DEPRECATE#include <cuda.h>
#include <cuda_runtime.h>
#include <cuda_runtime_api.h>
#include <device_launch_parameters.h>
// If the code is used in Matlab, set MATLAB_CODE to 1. Otherwise, set MATLAB_CODE to 0.
#define MATLAB_CODE 0
// Includes
#include <stdio.h>
#include <math.h>
#include "cuda.h"
#if MATLAB_CODE == 1
#include "mex.h"
#else
#include <time.h>
#endif
// Constants used by the program
#define MAX_PITCH_VALUE_IN_BYTES 262144
#define MAX_TEXTURE_WIDTH_IN_BYTES 65536
#define MAX_TEXTURE_HEIGHT_IN_BYTES 32768
#define MAX_PART_OF_FREE_MEMORY_USED 0.9
#define BLOCK_DIM 16
// Texture containing the reference points (if it is possible)
texture<float, 2, cudaReadModeElementType> texA;
//-----------------------------------------------------------------------------------------------//
// KERNELS //
//-----------------------------------------------------------------------------------------------//
/**
* Computes the distance between two matrix A (reference points) and
* B (query points) containing respectively wA and wB points.
* The matrix A is a texture.
*
* @param wA width of the matrix A = number of points in A
* @param B pointer on the matrix B
* @param wB width of the matrix B = number of points in B
* @param pB pitch of matrix B given in number of columns
* @param dim dimension of points = height of matrices A and B
* @param AB pointer on the matrix containing the wA*wB distances computed
*/
__global__ void cuComputeDistanceTexture(int wA, float * B, int wB, int pB, int dim, float* AB) {
unsigned int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int yIndex = blockIdx.y * blockDim.y + threadIdx.y;
if (xIndex < wB && yIndex < wA) {
float ssd = 0;
for (int i = 0; i < dim; i++) {
float tmp = tex2D(texA, (float)yIndex, (float)i) - B[i * pB + xIndex];
ssd += tmp * tmp;
}
AB[yIndex * pB + xIndex] = ssd;
}
}
/**
* Computes the distance between two matrix A (reference points) and
* B (query points) containing respectively wA and wB points.
*
* @param A pointer on the matrix A
* @param wA width of the matrix A = number of points in A
* @param pA pitch of matrix A given in number of columns
* @param B pointer on the matrix B
* @param wB width of the matrix B = number of points in B
* @param pB pitch of matrix B given in number of columns
* @param dim dimension of points = height of matrices A and B
* @param AB pointer on the matrix containing the wA*wB distances computed
*/
__global__ void cuComputeDistanceGlobal(float* A, int wA, int pA, float* B, int wB, int pB, int dim, float* AB) {
// Declaration of the shared memory arrays As and Bs used to store the sub-matrix of A and B
__shared__ float shared_A[BLOCK_DIM][BLOCK_DIM];
__shared__ float shared_B[BLOCK_DIM][BLOCK_DIM];
// Sub-matrix of A (begin, step, end) and Sub-matrix of B (begin, step)
__shared__ int begin_A;
__shared__ int begin_B;
__shared__ int step_A;
__shared__ int step_B;
__shared__ int end_A;
// Thread index
int tx = threadIdx.x;
int ty = threadIdx.y;
// Other variables
float tmp;
float ssd = 0;
// Loop parameters
begin_A = BLOCK_DIM * blockIdx.y;
begin_B = BLOCK_DIM * blockIdx.x;
step_A = BLOCK_DIM * pA;
step_B = BLOCK_DIM * pB;
end_A = begin_A + (dim - 1) * pA;
// Conditions
int cond0 = (begin_A + tx < wA); // used to write in shared memory
int cond1 = (begin_B + tx < wB); // used to write in shared memory & to computations and to write in output matrix
int cond2 = (begin_A + ty < wA); // used to computations and to write in output matrix
// Loop over all the sub-matrices of A and B required to compute the block sub-matrix
for (int a = begin_A, b = begin_B; a <= end_A; a += step_A, b += step_B) {
// Load the matrices from device memory to shared memory; each thread loads one element of each matrix
if (a / pA + ty < dim) {
shared_A[ty][tx] = (cond0) ? A[a + pA * ty + tx] : 0;
shared_B[ty][tx] = (cond1) ? B[b + pB * ty + tx] : 0;
}
else {
shared_A[ty][tx] = 0;
shared_B[ty][tx] = 0;
}
// Synchronize to make sure the matrices are loaded
__syncthreads();
// Compute the difference between the two matrixes; each thread computes one element of the block sub-matrix
if (cond2 && cond1) {
for (int k = 0; k < BLOCK_DIM; ++k) {
tmp = shared_A[k][ty] - shared_B[k][tx];
ssd += tmp * tmp;
}
}
// Synchronize to make sure that the preceding computation is done before loading two new sub-matrices of A and B in the next iteration
__syncthreads();
}
// Write the block sub-matrix to device memory; each thread writes one element
if (cond2 && cond1)
AB[(begin_A + ty) * pB + begin_B + tx] = ssd;
}
/**
* Gathers k-th smallest distances for each column of the distance matrix in the top.
*
* @param dist distance matrix
* @param dist_pitch pitch of the distance matrix given in number of columns
* @param ind index matrix
* @param ind_pitch pitch of the index matrix given in number of columns
* @param width width of the distance matrix and of the index matrix
* @param height height of the distance matrix and of the index matrix
* @param k number of neighbors to consider
*/
__global__ void cuInsertionSort(float *dist, int dist_pitch, int *ind, int ind_pitch, int width, int height, int k) {
// Variables
int l, i, j;
float *p_dist;
int *p_ind;
float curr_dist, max_dist;
int curr_row, max_row;
unsigned int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
if (xIndex < width) {
// Pointer shift, initialization, and max value
p_dist = dist + xIndex;
p_ind = ind + xIndex;
max_dist = p_dist[0];
p_ind[0] = 1;
// Part 1 : sort kth firt elementZ
for (l = 1; l < k; l++) {
curr_row = l * dist_pitch;
curr_dist = p_dist[curr_row];
if (curr_dist < max_dist) {
i = l - 1;
for (int a = 0; a < l - 1; a++) {
if (p_dist[a*dist_pitch] > curr_dist) {
i = a;
break;
}
}
for (j = l; j > i; j--) {
p_dist[j*dist_pitch] = p_dist[(j - 1)*dist_pitch];
p_ind[j*ind_pitch] = p_ind[(j - 1)*ind_pitch];
}
p_dist[i*dist_pitch] = curr_dist;
p_ind[i*ind_pitch] = l + 1;
}
else
p_ind[l*ind_pitch] = l + 1;
max_dist = p_dist[curr_row];
}
// Part 2 : insert element in the k-th first lines
max_row = (k - 1)*dist_pitch;
for (l = k; l < height; l++) {
curr_dist = p_dist[l*dist_pitch];
if (curr_dist < max_dist) {
i = k - 1;
for (int a = 0; a < k - 1; a++) {
if (p_dist[a*dist_pitch] > curr_dist) {
i = a;
break;
}
}
for (j = k - 1; j > i; j--) {
p_dist[j*dist_pitch] = p_dist[(j - 1)*dist_pitch];
p_ind[j*ind_pitch] = p_ind[(j - 1)*ind_pitch];
}
p_dist[i*dist_pitch] = curr_dist;
p_ind[i*ind_pitch] = l + 1;
max_dist = p_dist[max_row];
}
}
}
}
/**
* Computes the square root of the first line (width-th first element)
* of the distance matrix.
*
* @param dist distance matrix
* @param width width of the distance matrix
* @param pitch pitch of the distance matrix given in number of columns
* @param k number of neighbors to consider
*/
__global__ void cuParallelSqrt(float *dist, int width, int pitch, int k) {
unsigned int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int yIndex = blockIdx.y * blockDim.y + threadIdx.y;
if (xIndex < width && yIndex < k)
dist[yIndex*pitch + xIndex] = sqrt(dist[yIndex*pitch + xIndex]);
}
//-----------------------------------------------------------------------------------------------//
// K-th NEAREST NEIGHBORS //
//-----------------------------------------------------------------------------------------------//
/**
* Prints the error message return during the memory allocation.
*
* @param error error value return by the memory allocation function
* @param memorySize size of memory tried to be allocated
*/
void printErrorMessage(cudaError_t error, int memorySize) {
printf("==================================================\n");
printf("MEMORY ALLOCATION ERROR : %s\n", cudaGetErrorString(error));
printf("Whished allocated memory : %d\n", memorySize);
printf("==================================================\n");
#if MATLAB_CODE == 1
mexErrMsgTxt("CUDA ERROR DURING MEMORY ALLOCATION");
#endif
}
/**
* K nearest neighbor algorithm
* - Initialize CUDA
* - Allocate device memory
* - Copy point sets (reference and query points) from host to device memory
* - Compute the distances + indexes to the k nearest neighbors for each query point
* - Copy distances from device to host memory
*
* @param ref_host reference points ; pointer to linear matrix
* @param ref_width number of reference points ; width of the matrix
* @param query_host query points ; pointer to linear matrix
* @param query_width number of query points ; width of the matrix
* @param height dimension of points ; height of the matrices
* @param k number of neighbor to consider
* @param dist_host distances to k nearest neighbors ; pointer to linear matrix
* @param dist_host indexes of the k nearest neighbors ; pointer to linear matrix
*
*/
void knn(float* ref_host, int ref_width, float* query_host, int query_width, int height, int k, float* dist_host, int* ind_host) {
unsigned int size_of_float = sizeof(float);
unsigned int size_of_int = sizeof(int);
// Variables
float *query_dev;
float *ref_dev;
float *dist_dev;
int *ind_dev;
cudaArray *ref_array;
cudaError_t result;
size_t query_pitch;
size_t query_pitch_in_bytes;
size_t ref_pitch;
size_t ref_pitch_in_bytes;
size_t ind_pitch;
size_t ind_pitch_in_bytes;
size_t max_nb_query_traited;
size_t actual_nb_query_width;
size_t memory_total;
size_t memory_free;
// Check if we can use texture memory for reference points
size_t use_texture = (ref_width*size_of_float <= MAX_TEXTURE_WIDTH_IN_BYTES && height*size_of_float <= MAX_TEXTURE_HEIGHT_IN_BYTES);
// CUDA Initialisation
cuInit(0);
// Check free memory using driver API ; only (MAX_PART_OF_FREE_MEMORY_USED*100)% of memory will be used
CUcontext cuContext;
CUdevice cuDevice = 0;
cuCtxCreate(&cuContext, 0, cuDevice);
cuMemGetInfo(&memory_free, &memory_total);
cuCtxDetach(cuContext);
// Determine maximum number of query that can be treated
max_nb_query_traited = (memory_free * MAX_PART_OF_FREE_MEMORY_USED - size_of_float * ref_width*height) / (size_of_float * (height + ref_width) + size_of_int * k);
max_nb_query_traited = min((unsigned int)query_width, (unsigned int)(max_nb_query_traited / 16) * 16);
// Allocation of global memory for query points and for distances
result = cudaMallocPitch((void **)&query_dev, &query_pitch_in_bytes, max_nb_query_traited * size_of_float, height + ref_width);
if (result) {
printErrorMessage(result, max_nb_query_traited*size_of_float*(height + ref_width));
return;
}
query_pitch = query_pitch_in_bytes / size_of_float;
dist_dev = query_dev + height * query_pitch;
// Allocation of global memory for indexes
result = cudaMallocPitch((void **)&ind_dev, &ind_pitch_in_bytes, max_nb_query_traited * size_of_int, k);
if (result) {
cudaFree(query_dev);
printErrorMessage(result, max_nb_query_traited*size_of_int*k);
return;
}
ind_pitch = ind_pitch_in_bytes / size_of_int;
// Allocation of memory (global or texture) for reference points
if (use_texture) {
// Allocation of texture memory
cudaChannelFormatDesc channelDescA = cudaCreateChannelDesc<float>();
result = cudaMallocArray(&ref_array, &channelDescA, ref_width, height);
if (result) {
printErrorMessage(result, ref_width*height*size_of_float);
cudaFree(ind_dev);
cudaFree(query_dev);
return;
}
cudaMemcpyToArray(ref_array, 0, 0, ref_host, ref_width * height * size_of_float, cudaMemcpyHostToDevice);
// Set texture parameters and bind texture to array
texA.addressMode[0] = cudaAddressModeClamp;
texA.addressMode[1] = cudaAddressModeClamp;
texA.filterMode = cudaFilterModePoint;
texA.normalized = 0;
cudaBindTextureToArray(texA, ref_array);
}
else {
// Allocation of global memory
result = cudaMallocPitch((void **)&ref_dev, &ref_pitch_in_bytes, ref_width * size_of_float, height);
if (result) {
printErrorMessage(result, ref_width*size_of_float*height);
cudaFree(ind_dev);
cudaFree(query_dev);
return;
}
ref_pitch = ref_pitch_in_bytes / size_of_float;
cudaMemcpy2D(ref_dev, ref_pitch_in_bytes, ref_host, ref_width*size_of_float, ref_width*size_of_float, height, cudaMemcpyHostToDevice);
}
// Split queries to fit in GPU memory
for (int i = 0; i < query_width; i += max_nb_query_traited) {
// Number of query points considered
actual_nb_query_width = min((unsigned int)max_nb_query_traited, (unsigned int)query_width - i);
// Copy of part of query actually being treated
cudaMemcpy2D(query_dev, query_pitch_in_bytes, &query_host[i], query_width*size_of_float, actual_nb_query_width*size_of_float, height, cudaMemcpyHostToDevice);
// Grids ans threads
dim3 g_16x16(actual_nb_query_width / 16, ref_width / 16, 1);
dim3 t_16x16(16, 16, 1);
if (actual_nb_query_width % 16 != 0) g_16x16.x += 1;
if (ref_width % 16 != 0) g_16x16.y += 1;
//
dim3 g_256x1(actual_nb_query_width / 256, 1, 1);
dim3 t_256x1(256, 1, 1);
if (actual_nb_query_width % 256 != 0) g_256x1.x += 1;
//
dim3 g_k_16x16(actual_nb_query_width / 16, k / 16, 1);
dim3 t_k_16x16(16, 16, 1);
if (actual_nb_query_width % 16 != 0) g_k_16x16.x += 1;
if (k % 16 != 0) g_k_16x16.y += 1;
// Kernel 1: Compute all the distances
if (use_texture)
cuComputeDistanceTexture << <g_16x16, t_16x16 >> > (ref_width, query_dev, actual_nb_query_width, query_pitch, height, dist_dev);
else
cuComputeDistanceGlobal << <g_16x16, t_16x16 >> > (ref_dev, ref_width, ref_pitch, query_dev, actual_nb_query_width, query_pitch, height, dist_dev);
// Kernel 2: Sort each column
cuInsertionSort << <g_256x1, t_256x1 >> > (dist_dev, query_pitch, ind_dev, ind_pitch, actual_nb_query_width, ref_width, k);
// Kernel 3: Compute square root of k first elements
cuParallelSqrt << <g_k_16x16, t_k_16x16 >> > (dist_dev, query_width, query_pitch, k);
// Memory copy of output from device to host
cudaMemcpy2D(&dist_host[i], query_width*size_of_float, dist_dev, query_pitch_in_bytes, actual_nb_query_width*size_of_float, k, cudaMemcpyDeviceToHost);
cudaMemcpy2D(&ind_host[i], query_width*size_of_int, ind_dev, ind_pitch_in_bytes, actual_nb_query_width*size_of_int, k, cudaMemcpyDeviceToHost);
}
// Free memory
if (use_texture)
cudaFreeArray(ref_array);
else
cudaFree(ref_dev);
cudaFree(ind_dev);
cudaFree(query_dev);
}
//-----------------------------------------------------------------------------------------------//
// MATLAB INTERFACE & C EXAMPLE //
//-----------------------------------------------------------------------------------------------//
#if MATLAB_CODE == 1
/**
* Interface to use CUDA code in Matlab (gateway routine).
*
* @param nlhs Number of expected mxArrays (Left Hand Side)
* @param plhs Array of pointers to expected outputs
* @param nrhs Number of inputs (Right Hand Side)
* @param prhs Array of pointers to input data. The input data is read-only and should not be altered by your mexFunction .
*/
void mexFunction(int nlhs, mxArray *plhs[], int nrhs, const mxArray *prhs[]) {
// Variables
float* ref;
int ref_width;
int ref_height;
float* query;
int query_width;
int query_height;
float* dist;
int* ind;
int k;
// Reference points
ref = (float *)mxGetData(prhs[0]);
ref_width = mxGetM(prhs[0]);
ref_height = mxGetN(prhs[0]);
// Query points
query = (float *)mxGetData(prhs[1]);
query_width = mxGetM(prhs[1]);
query_height = mxGetN(prhs[1]);
// Number of neighbors to consider
k = (int)mxGetScalar(prhs[2]);
// Verification of the reference point and query point sizes
if (ref_height != query_height)
mexErrMsgTxt("Data must have the same dimension");
if (ref_width * sizeof(float) > MAX_PITCH_VALUE_IN_BYTES)
mexErrMsgTxt("Reference number is too large for CUDA (Max=65536)");
if (query_width * sizeof(float) > MAX_PITCH_VALUE_IN_BYTES)
mexErrMsgTxt("Query number is too large for CUDA (Max=65536)");
// Allocation of output arrays
dist = (float *)mxGetPr(plhs[0] = mxCreateNumericMatrix(query_width, k, mxSINGLE_CLASS, mxREAL));
ind = (int *)mxGetPr(plhs[1] = mxCreateNumericMatrix(query_width, k, mxINT32_CLASS, mxREAL));
// Call KNN CUDA
knn(ref, ref_width, query, query_width, ref_height, k, dist, ind);
}
#else // C code
/**
* Example of use of kNN search CUDA.
*/
int main(void) {
// Variables and parameters
float* ref; // Pointer to reference point array
float* query; // Pointer to query point array
float* dist; // Pointer to distance array
int* ind; // Pointer to index array
int ref_nb = 4096; // Reference point number, max=65535
int query_nb = 4096; // Query point number, max=65535
int dim = 32; // Dimension of points
int k = 20; // Nearest neighbors to consider
int iterations = 100;
int i;
// Memory allocation
ref = (float *)malloc(ref_nb * dim * sizeof(float));
query = (float *)malloc(query_nb * dim * sizeof(float));
dist = (float *)malloc(query_nb * k * sizeof(float));
ind = (int *)malloc(query_nb * k * sizeof(float));
// Init
srand(time(NULL));
for (i = 0; i < ref_nb * dim; i++) ref[i] = (float)rand() / (float)RAND_MAX;
for (i = 0; i < query_nb * dim; i++) query[i] = (float)rand() / (float)RAND_MAX;
// Variables for duration evaluation
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
float elapsed_time;
// Display informations
printf("Number of reference points : %6d\n", ref_nb);
printf("Number of query points : %6d\n", query_nb);
printf("Dimension of points : %4d\n", dim);
printf("Number of neighbors to consider : %4d\n", k);
printf("Processing kNN search :");
// Call kNN search CUDA
cudaEventRecord(start, 0);
for (i = 0; i < iterations; i++)
knn(ref, ref_nb, query, query_nb, dim, k, dist, ind);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsed_time, start, stop);
printf(" done in %f s for %d iterations (%f s by iteration)\n", elapsed_time / 1000, iterations, elapsed_time / (iterations * 1000));
// Destroy cuda event object and free memory
cudaEventDestroy(start);
cudaEventDestroy(stop);
free(ind);
free(dist);
free(query);
free(ref);
}
#endif运行结果:


















 6573
6573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









