









起因:在其他服务器正常运行的docker环境迁移复制到其他环境中(该服务包含paddlepaddle等第三方库),出现上述标题所示错误。具体错误打印信息如下:
terminate called after throwing an instance of 'phi::enforce::EnforceNotMet'
what():--------------------------------------
C++ Traceback (most recent call last):
--------------------------------------
0 PaddleDeploy::Model::PaddleEngineInit(PaddleDeploy::PaddleEngineConfig const&)
1 PaddleDeploy::PaddleInferenceEngine::Init(PaddleDeploy::InferenceConfig const&)
2 paddle_infer::CreatePredictor(paddle::AnalysisConfig const&)
3 paddle_infer::Predictor::Predictor(paddle::AnalysisConfig const&)
4 std::unique_ptr<paddle::PaddlePredictor, std::default_delete<paddle::PaddlePredictor> > paddle::CreatePaddlePredictor<paddle::AnalysisConfig, (paddle::PaddleEngineKind)2>(paddle::AnalysisConfig const&)
5 paddle::AnalysisConfig::fraction_of_gpu_memory_for_pool() const
6 phi::backends::gpu::SetDeviceId(int)
7 phi::backends::gpu::GetGPUDeviceCount()
8 phi::enforce::EnforceNotMet::EnforceNotMet(phi::ErrorSummary const&, char const*, int)
9 phi::enforce::GetCurrentTraceBackString[abi:cxx11](bool)----------------------
Error Message Summary:
----------------------
ExternalError: CUDA error(803), system has unsupported display driver / cuda driver combination.
[Hint: Please search for the error code(803) on website (https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html#group__CUDART__TYPES_1g3f51e3575c2178246db0a94a430e0038) to get Nvidia's official solution and advice about CUDA Error.] (at /paddle/paddle/phi/backends/gpu/cuda/cuda_info.cc:66)Aborted (core dumped)
应该是两台服务器安装的cuda版本不同导致。解决办法。首先进入docker环境,查看该docker拥有多少cuda版本。
进入安装目录(不同电脑可能不同):
cd /usr/lib/x86_64-linux-gnu/显示如下,有三个版本的cuda,这三个版本不确定那个有效,可以使用软连接方法挨个尝试,直到执行程序不出现上述错误为止。(其中红色框起来时软连接,即淡蓝色的是软连接)
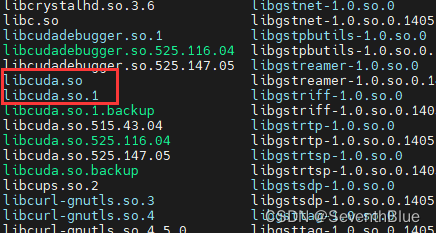
这里的操作是先删除libcuda.so.1(建议还是备份一下),然后又创建其他其他库指向该libcuda.so.1的软连接。操作命令如下:
sudo rm -rf /usr/lib/x86_64-linux-gnu/libcuda.so.1
sudo ln -s libcuda.so.525.147.05 /usr/lib/x86_64-linux-gnu/libcuda.so.1

















 8218
8218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









