







我们现在将讨论如何使用迄今为止讨论过的 DBMS 组件来执行查询。
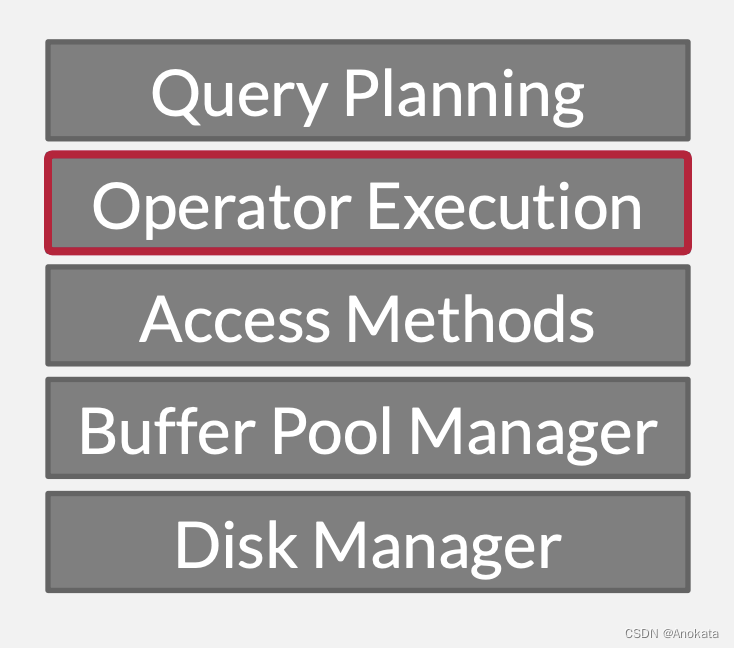
1 查询计划【Query Plan】
我们首先来看当一个查询【Query】被解析【Parsed】后会发生什么?
当 SQL 查询被提供给数据库执行引擎,它将通过语法解析器进行检查,然后它会被转换成关系的代数表示,需要注意的是,这个代数表示是得到优化过后的。
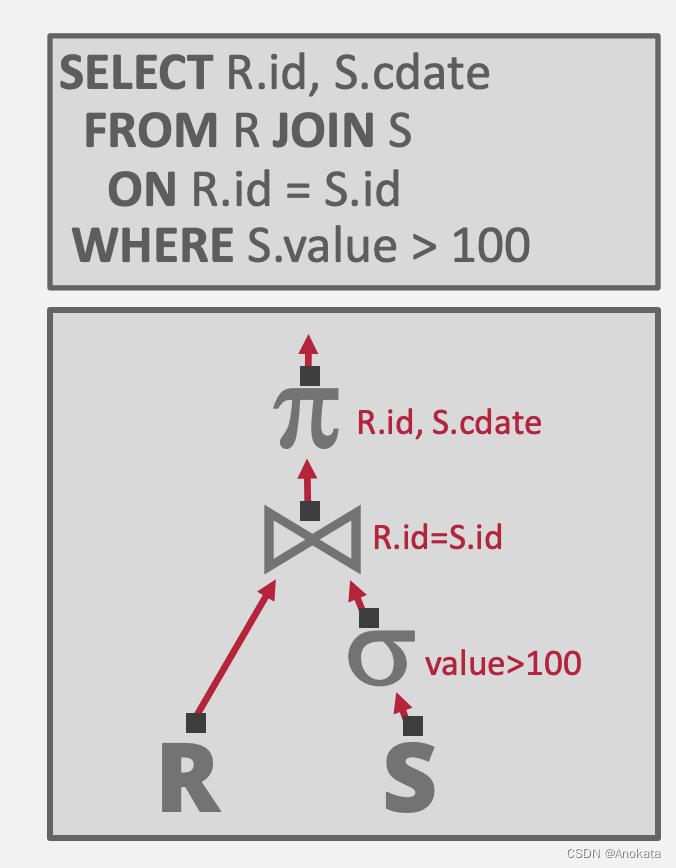
大概解释一下这棵树:
- R 和 S 是两张表,也可以说是两个关系
- 首先对 S 表做查询,条件谓词 value > 100
- 然后将 S 表与 R 表做 join ,连接的条件是 S.id = R.id
- 最后对联表生成的关系做映射,只取R.id和S.cdata两列输出的到结果中
我们得到了用树形表示的查询,树的每一个节点都是一个操作符。数据从树的叶子向上流向根,根节点的输出就是查询的结果。
那么我们想用算法对这些操作符做什么呢??
- 就像不能假设表完全可以被内存容纳下来一样,面向磁盘的 DBMS 也不能假设查询结果(设置时中间结果)可以被内存容纳。
- 我们将使用缓冲池来实现需要溢出到磁盘的算法,即内存不足以承载(中间)结果集时。
- 我们还将更喜欢能够最大化顺序 I/O 量的算法。
2 为什么我们需要排序
关系型模型【Relational model/】/SQL 是无序的【unsorted】。
但是查询【Query】可能要求元组以特定方式排序(ORDER BY)。
但即使查询没有指定顺序,我们可能仍然想要排序来做其他事情:
- 轻松支持重复消除(DISTINCT)。
- 将排序元组【sorted tuples】批量加载到 B+Tree 索引中的速度更快。
- 聚合(GROUP BY)。
3 内存排序
如果内存足以容纳数据,那么我们可以使用标准排序算法,例如快速排序。
大多数数据库系统使用快速排序进行内存排序。
在其他数据平台中,尤其是 Python,默认排序算法是 TimSort。 它是插入排序和二元归并排序的结合。 通常在真实数据上效果很好。
如果内存不足以容纳数据,那么我们需要使用一种能够感知读取和写入磁盘页面成本的技术。
4 排序算法
今天我们主要讲下面几个算法:
- Top-N 堆排序【Top-N Heap Sort】
- 外部归并排序【External Merge Sort】
- 聚合【Aggregations】
4.1 Top-N 堆排序【Top-N Heap Sort】
如果查询【Query】中包含带有 LIMIT 的 ORDER BY,则 DBMS 只需扫描数据一次即可找到前 N 个元素。
堆排序的理想场景:如果 topN 元素适合内存。
- 扫描一次数据,在内存中维护一个排序的优先级队列。
1️⃣ 我们扫描数据
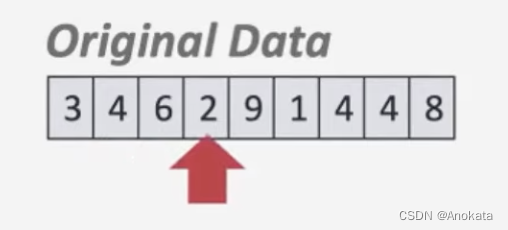
2️⃣ 并将其设置到堆排序的数组中 <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









