







【基本概念】
Tensorflow最基本的一次计算过程:接收n个固定格式的数据输入,通过特定函数,将其转化为n个张量(Tensor)输出。
数据流图:在逻辑上描述以此机器学习计算的过程。
1.数据流图
节点:通常以圆、椭圆或方框表示,代表对数据的运算或某种操作
边:数据流图是一种有向图,通常用带箭头的线段表示
(除了上述概念以外)
Session(会话):根据上下文,会话负责管理协调整个数据流图的计算过程
Op(操作):数据流图中的一个节点,代表依次基本操作过程
Tensor(张量):在Tensorflow中,所有计算数据的格式,本质上一个n维数组
【例】构建一个数据流图
import tensorflow as tf
a = tf.constant(4,name = "input_a")
b = tf.constant(2,name = "input_b")
c = tf.multiply(a,b,name = "mul_c")
d = tf.add(a,b,name = "add_d")
e = tf.add(c,d,name = "add_e")
sess = tf.Session()
print(sess.run(e))
sess.close()tf.constant()就是创建一个常量操作,本身有多个参数,其函数原型如下:
constant(
value,
dtype = None, #张量数据类型
shape = None, #张量维度
mame = 'Const', #制定操作名称
verify_shape = False #是否验证张量形状
)2.TensorBoard(数据流图可视化工具)
tensorboard的参数如下:
- --port:设置Web服务的端口号,如果不设置,默认6006
- --event_file:制定一个特定的事件日志文件
- --reload_interval:Web服务后台重新加载数据的间隔,默认120秒
3.张量思维
阶、形状、维度是一个概念
tmp = tf.constant([[1,2],[3,4]])
with tf.Session() as sess:
shape = tf.shape(tmp)
rank = tf.rank(tmp)
print(sess.run(shape)) #输出 [2,2] 代表2×2的数组
print(sess.run(rank)) #输出 2 代表维度为24.Tensorflow中的相关操作
TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU。一般你不需要显式指定使用 CPU 还是 GPU, TensorFlow 能自动检测。如果检测到 GPU, TensorFlow 会尽可能地利用找到的第一个 GPU 来执行操作。
并行计算能让代价大的算法计算加速执行,TensorFlow也在实现上对复杂操作进行了有效的改进。大部分核相关的操作都是设备相关的实现,比如GPU。下面是一些重要的操作/核:

TensorFlow的算术操作如下:


【链接】Tensorflow一些常用基本概念与函数(很全);使用时查阅官方文档函数说明即可
5.Tensorflow中的Graph对象
import tensorflow as tf
import numpy as np
a = tf.constant(123)
print(a.graph)
print(tf.get_default_graph())a的图对象就是当前默认的图对象。当Tensorflow库被加载时,即使用户没有显式地创建一个图,它也会自动创建一个图对象,并将其作为默认的数据流图。
6.Tensorflow中的Session
Tensorflow内核使用更加高效的C++作为后台,以支撑它的密集计算。Tensorflow吧前台(即Python程序)与后台程序之间的连接称为“会话(Session)”。
Session作为会话,主要功能是指定操作对象的执行环境。Session类的三个可选参数如下:
- target(可选):指定连接的执行引擎。对于大多数Tensorflow应用程序来说,使用默认的空字符串,即使用in-process(进程间)引擎,如果这个值不为空,多用在分布式环境中的案例
with tf.Session("grpc://example.org:2222") as sess:
#调用sess.run()一旦调用会话的run()方法,当前节点就会称为集群中的主机,它把图的Op分发到集群中的各个节点(slave),这里的“grpc”是指gRPC,即“谷歌远程过程调用”。
- graph(可选):指定在Session对象和中参与计算的图(graph)。默认是“None”,表示要使用默认图
- config(可选):这个参数可辅助配置Session对象所需的参数,如果要限制CPU或GPU的使用数目,为数据流图设置优化参数以及设置日志选项等
run()方法的使用
run(
fetches,
#表示数据流图中能接受的任意数据流图元素,Op或者Tensor对象,前者返回None,后者输出为Numpy数组
feed_dict = None,
options = None,
run_metadata = None
)7.Tensorflow中的placeholder
通常为了维护数据流图的完整性,可以先使用一个占位符,提前占据对应位置。
a = tf.placeholder(tf.float32, name = "input_1")
b = tf.placeholder(tf.float32, name = "input_2")
output = tf.multiply(a,b,name = "mul_out")
input_dict = {a:7,b:10}
with tf.Session() as sess:
print(sess.run(output,feed_dict = input_dict))其中placeholder的参数如下:
placeholder(
dtype,
shape = None,
name = None
)8.Tensorflow中的Variable对象
数据流图中的两大组成部分,一个是Tensor对象,另一个是op对象,这二者都具有不可变性(immutable)。而且在数据流图中,对于普通Tensor来说,经过一次Op操作后,就会转化为另一个Tensor,当前一个Tensoe的使命完成后,就会被系统回收。
解决这个为题的方法就是使用Variable对象。本质上,Variable就是一个常驻内存、不会被轻易回收的Tensor。
my_state = tf.Variable(0,name = "counter")
one = tf.constant(1)
new_value = tf.add(my_state,one)
update = tf.assign(my_state, new_value)
init_Op = tf.global_variables_initializer() #全局变量初始化操作
#在这之前都是流图的构思
with tf.Session() as sess:
sess.run(init_Op)
print(sess.run(my_state))
for _ in range(3): #_是一个垃圾箱变量,虽然可以接受变量,但是不准备用它,只看重整个for循环的次数
sess.run(update)
print(sess.run(my_state))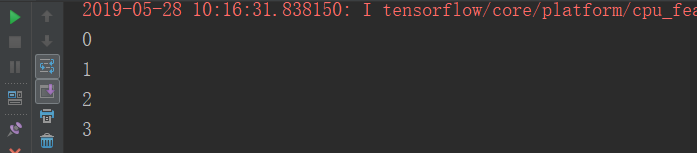
9.Tensorflow中的名称作用域
with tf.name_scope('hidden') as scope:
a= tf.constant(5, name = 'alpha')
print(a.name)
weights = tf.Variable(tf.random_uniform([1,2],-1.0,1.0), name = 'weights')
print(weights.name)
bias = tf.Variable(tf.zeros([1]), name = 'bias')
print(bias.name)
with tf.name_scope('conv1') as scope:
weights = tf.Variable([1.0,2.0], name = 'weights')
print(weights.name)
bias = tf.Variable([0,3], name = 'biases')
print(bias.name)
sess = tf.Session()
writer = tf.summary.FileWriter('./2',sess.graph)
10.张量的Reduce方向
在并行计算中,如在CUDA或MPI中,常有“约减”(Reduce,也可以叫做“规约”)。其表示将一批数据,在多进程或多线程中,按照某种操作(Op),将众多(可能分布于不同节点)数据合并到一个或几个数据之内。约减之后,数据个数在总量上是减少的。(数量的减少,不是减法)。
约减函数如tf.reduce() tf.reduce_mean() tf.reduce_max() tf.reduce_min等。
整理自《深度学习之美》
















 61
61











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











