







 本文详细介绍了PASCALVOC2012、SBD和增强版PASCALVOC2012数据集的结构、下载方式及数据处理方法,涵盖了语义分割、实例分割等关键概念,同时提供了数据集制作与整合的实用脚本。
本文详细介绍了PASCALVOC2012、SBD和增强版PASCALVOC2012数据集的结构、下载方式及数据处理方法,涵盖了语义分割、实例分割等关键概念,同时提供了数据集制作与整合的实用脚本。
本文用到的数据处理脚本:PASCAL-VOC-2012-Augmented-Dataset
分割数据集
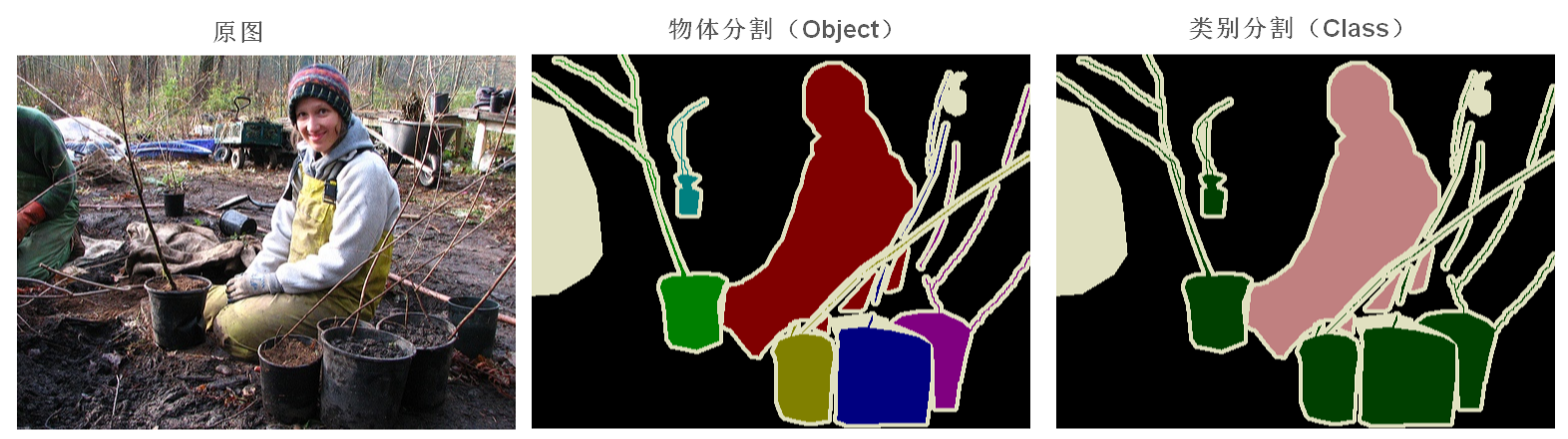
下面三张分别是原图,实例分割和语义分割的 PNG 图:
- 语义分割相当于是类别分割,即为每一个像素分类,得到它所属的类别即可,但如果有两个物体都属于同一类别,语义分割并不区分这两个物体,只是单纯的将他们都分为同一类,体现为下面最右侧图中花盆全被填充为绿色;
- 实例分割相当于是物体分割,它是语义分割的子类型,需要在像素级分类的基础上,进一步对不同的实例进行区分,体现为中间一幅图中对每一个花盆都填充了不同的颜色进行区分。
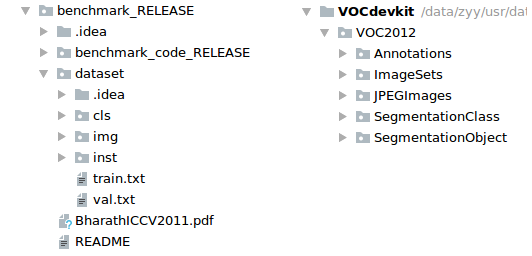
在 FCN 这篇论文中,用到了两个基本的分割数据集,分别是benchmark_RELEASE和PASCAL VOC2012
Benchmark
Benchmark 数据集:benchmark_RELEASE
其所有的图片都可用于分割任务(语义分割与实例分割),共 11355 张,其中官方划分用于训练的数据包含 8498 张,用于验证的数据包含 2867 张,如下表:
| 训练(train) | 验证(val) | 总计 |
|---|---|---|
| 8498 张 | 2857 张 | 11355 张 |
dataset 文件夹下包含了训练数据的相关内容,其中 cls 为语义分割标签,inst 为实例分割标签,img 为原图,其中两种标签都是以 .mat 的格式存储的。
(1)img:
(2)cls 和 inst:
查看 cls 语义分割 中的一个 .mat 文件:
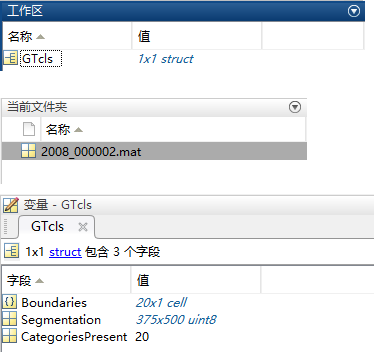
CategoriesPresent 为 20,表示该图片上物体的分类编号为 20
Segmentation 为 375 x 500 的 unit8 数据,打开如下:
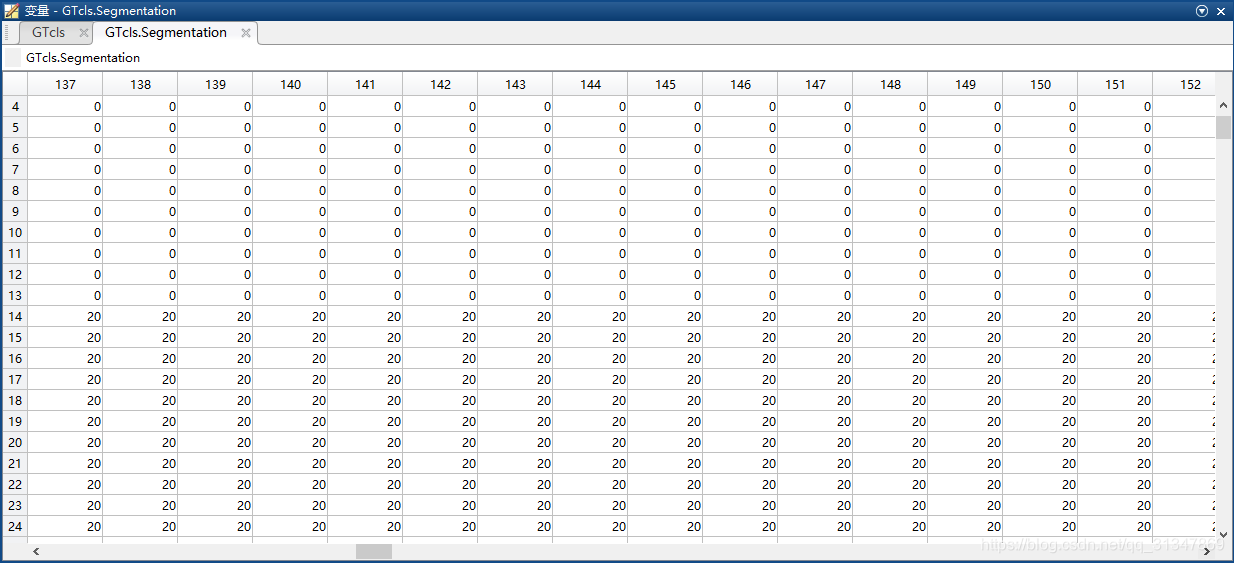
这张表形状为 375 行 500 列,表示了图像中的每一个像素点,且只有两个数值:0 和 20,代表给一个像素点的分类要么是 0(背景),要么是 20(某一类前景)
查看 inst 实例分割中与上面对应的 .mat 文件:
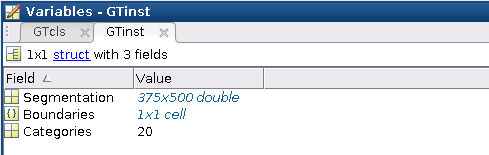
可以看到类别标注 Categories 仍是 20,但是打开 Segmentation 发现在 cls 标注为 0 和 20 的像素点在 inst 中标注为了 0 和 1,这说明在 inst 中的 label 信息只是为了实现目标的分割任务,只要将一幅图中的分割目标显示出来即可,而不需要对物体进行类别标记。
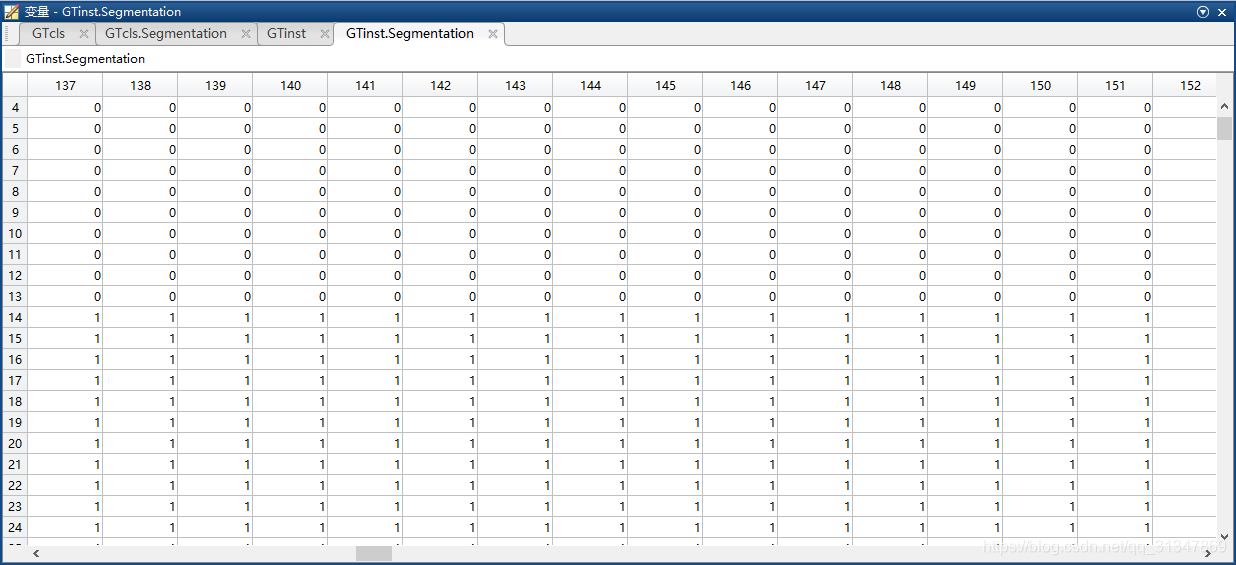
再查看另一个 inst 中的例子:2008_000036.mat
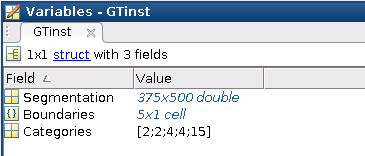
看到其 Categories 值为 [2;2;4;4;15],说明这幅图里包括 3 类物体,其中属于 2 类和 4 类的物体分别有两个,属于 15 类的物体有 1 个,打开 Segmentaion 如下:
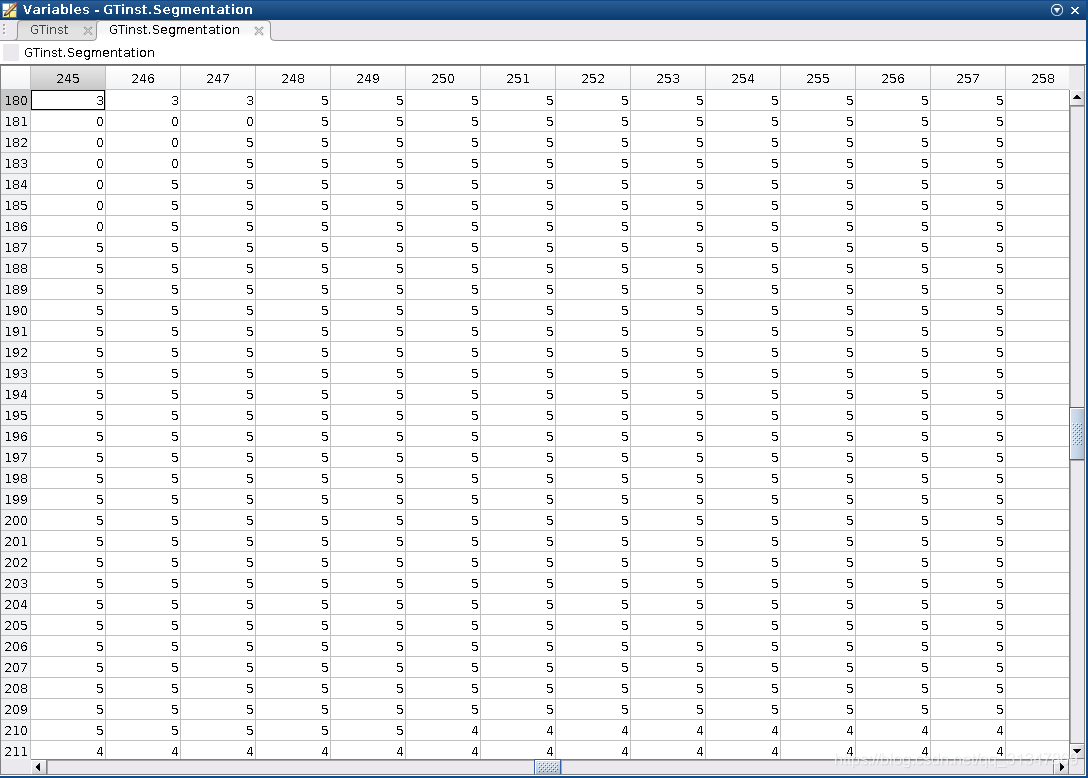
发现像素点范围是 0 ~ 5,其中 0 代表背景,1 ~ 5 代表图中的 5 个物体,但是这里仅仅是对不同物体做出了区分,并未进行分类标记,如果从 cls 中打开对应的 label 信息,那么上面 1 ~ 5 对应的像素应该分别对应 2,2,4,4,15。
PASCAL VOC 2012
PASCAL VOC2012 数据集官网:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
不过官网的下载链接总是挂掉的状态,所以下载数据集用下面的镜像地址
Pascal VOC Dataset Mirror:https://pjreddie.com/projects/pascal-voc-dataset-mirror/
VOC2012 数据集可以做很多任务,包括图像分类,目标检测,目标分割等。这里主要介绍用于分割任务的数据。官方划分 VOC2012 为两个压缩包,分别用于训练验证(trainval)和测试(test),数据分布如下:
| 训练+验证(trainval) | 测试(test) | |
|---|---|---|
| 可用于分割任务 | 2913 张 | 1456 张(ground truth未公开) |
| 总计 | 17125 张 | 16135 张 |
VOC2012 数据集共有 20 + 1 = 21 个类,其中 1 是背景类,20 个类分别为:
- Person:person
- Animal:bird, cat, cow, dog, horse, sheep
- Vehicle:aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor:bottle, chair, dining table, potted plant, sofa, tv/monitor
1. JPEGImages 中是原始图像。
2. Annotation 中包含图像对应的标记信息:存储为 xml 格式,其中 segmented 为1,意思是这幅图可以用于分割任务(因为VOC2012 中一共有 10000+ 图,但并不都用于分割任务,有的用以目标检测或动作识别等),若这一栏为 0 则说明这幅图不能用于分割任务。
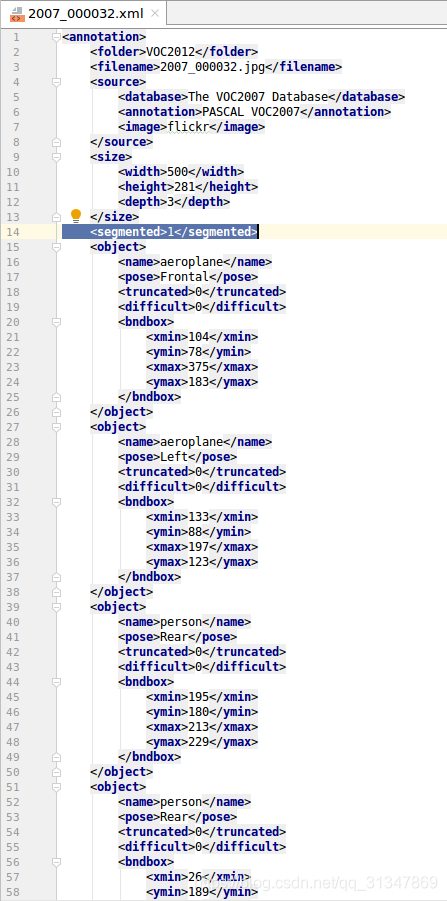
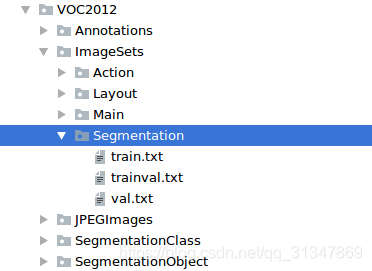
3. ImageSets 文件夹下的 Segmentation 保存了三个 txt 文件,用于记录用于分割任务的图片名,这样在跑程序时用 train.txt 就可以直接从 10000+ 图片中挑出可以用于分割训练的图片。
4. SegmentationClass 中的 PNG 图片用于语义分割任务,每个类别都有固定的颜色。
5. SegmentationObject 中的 PNG 图片用于实例分割任务,对图中不同的物体进行区分。
PASCAL VOC 2012 Augmented Dataset
PASCAL VOC 2012 增强数据集(PASCAL VOC 2012 Augmented Dataset)是目前语义分割和实例分割领域最常用、也是最基础的 benchmark 数据集,它是由两个数据集合二为一制作的,下面只针对分割任务进行说明:
- PASCAL VOC 2012:用于分割任务中训练+验证的图像有 2913 张,用于测试的图像有 1456 张
- Semantic Boundaries Dataset(SBD):用于训练和验证分别有 8498 张和 2857 张
| 数据集 | 训练+验证(trainval) | 测试(test) | 类别数 |
|---|---|---|---|
| PASCAL VOC 2012 | 2913 | 1456 | 21 |
| SBD | 11355 | / | 21 |
| PASCAL VOC 2012 Augmented Dataset | 12031 | 1456 | 21 |
说明:
- SDB 数据集的 11355 张图片实际上是包含在原 VOC 2012 数据集当中的,区别在于原 VOC 2012 数据集只有 1462 张图片可以用于做语义分割,而 SBD 数据集的 11355 张图片全是用来做语义分割的
- 为什么 VOC2012 和 SBD 合起来之后,用于trainval 的数据不是 2913+11355,而是 12031,看一下具体数据就会发现,SBD 中有一部分数据和 VOC2012 的 2913 张是重复的
- PASCAL VOC 2012 Augmented Dataset 的测试数据与原 VOC 2012 数据集一致,仍是 1456 张图像
- VOC 2012 测试数据集的 ground truth 未公开,要测试性能需要向官网提交结果,在线评估模型性能
因此,如果你要需要使用 PASCAL VOC 2012 Augmented Dataset 进行实验,其实不用把 benchmark 和 VOC 2012 分别下载下来再手动合并,只需要下载 SegmentationClass & ImageSets 和 VOCtrainval_11-May-2012.tar,然后替换掉 VOC 2012 中的对应文件即可,这样就是增强数据集了。
SegmentationClass & ImageSets 下载链接:
数据处理脚本下载: tools.zip
# 脚本包含
mat2png.py
convert_labels.py
utils.py
PASCAL VOC 2012 数据集下载:
Pascal voc 数据文件组织如下:
+ VOCdevkit
+ VOC2012
+ Annotations # 数据标签
+ ImageSets # 数据集索引
+ JPEGImages # 17125张图片
+ SegmentationClass # 用于语义分割的mask,2913张
+ SegmentationObject # 用于实例分割的mask
+ tools # 用于数据转换的脚本
+ convert_labels.py
+ utils.py
SBD 数据集下载:benchmark.tgz,官网:download.html
SBD 数据文件组织如下:
+ benchmark_RELEASE
+ cls # 用于语义分割的mask,11355个.mat文件
+ img # 11355张图片
+ inst # 用于实例分割的mask,11355个.mat文件
+ tools # 用于数据转换的脚本
+ mat2png.py
train.txt # 训练数据索引,8498个图片索引
val.txt # 验证数据索引,2857个图片索引
说明:tools 文件夹下放脚本文件
制作 VOC 数据集
跑代码大部分用到的数据集格式都是 VOC,所以记录一下整理自己的数据集为 VOC 格式的一些代码~
# 提取文件名保存在txt文件
import random
import glob
img_path = glob.glob('/root/data/image/*.jpg')
for each in img_path:
with open('/root/data/image/all.txt','a')as f:
f.write(each[15:-4]+'\n')# 切片换成自己路径对应的文件名位置
# 将上面的txt文件内容随机划分为三个txt
import random
with open('/root/data/image/all.txt','r')as f:
lines = f.readlines()
g = [i for i in range(1, 2172)]# 设置文件总数
random.shuffle(g)
# 设置需要的文件数
train = g[:1500]
trainval = g[1500:1900]
val = g[1900:]
for index, line in enumerate(lines,1):
if index in train:
with open('/root/data/index/train.txt','a')as trainf:
trainf.write(line)
elif index in trainval:
with open('/root/data/index/trainval.txt','a')as trainvalf:
trainvalf.write(line)
elif index in val:
with open('/root/data/index/val.txt','a')as valf:
valf.write(line)
原图、标签、XML文件的命名一一对应。xml标注文件的基本格式:
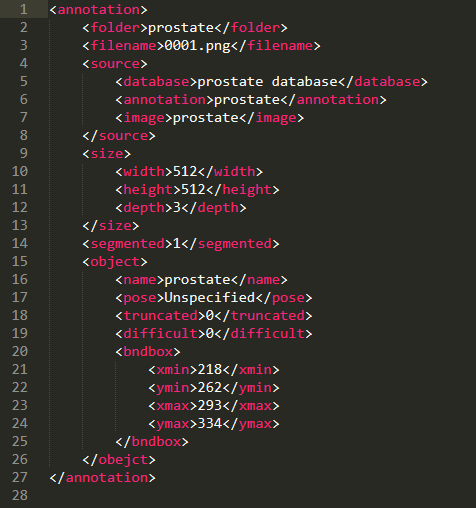
1)xmin 和 ymin 是目标物体 bounding box 的左上角坐标,xmax 和 ymax 是目标物体 bounding box 的右下角坐标;
2)这里每张图片只有一个目标,信息量还是很小的。
增强数据集组织格式:
pascal_voc_aug
├── pascal # 原voc数据
│ └── voc2012
└── sbd # 原sbd数据
│ └── ...
└── pascal_aug # 增强voc数据
└── cls_aug # 17125张
└── img_aug # 12031张
└── list
└── test.txt # 测试数据索引
└── train.txt
└── train_aug.txt # 训练数据索引
└── trainval.txt
└── trainval_aug.txt
└── val.txt # 验证数据索引
1. 数据集格式转换
SBD 数据的 mask 是 .mat 格式,先将其转换为 .png 格式。
在 benchmark_RELEASE 目录下创建 cls_png 文件夹用于存放转换后的 sbd png 图片,然后在该目录下执行脚本 mat2png.py 进行数据转换,转换后的图片是 8-bit 的灰度图。
python tools/mat2png.py cls cls_png
Pascal VOC 2012 数据的 mask 为 RGB 图像,将它们也转换为 8-bit 的灰度图。
在 VOCdevkit/VOC2012 目录下创建 SegmentationClass_1D 文件夹用于存放转换后的 mask 图片,
python tools/convert_labels.py SegmentationClass ImageSets/Segmentation/trainval.txt SegmentationClass_1D
两个数据集已经转换好的 Label 标注文件,下载链接:
2. 合并数据
创建文件夹 pascal_voc_aug/img_aug 和 pascal_voc_aug/cls_aug,分别存放增强后的图片数据和对应的标签文件,数量分别为 17125 张和 12031 张,这里图片数据(img_aug)其实仍然是原 VOC 2012 数据集的 JPEGImages,标签文件(cls_aug)是转换后的 VOC 和 SBD 灰度图标注文件。
这里由于 txt 文件中路径名的问题,将 img_aug 和 cls_aug 分别改名为 JPEGImages 和 SegmentationClassAug,这样就不用再改 txt 文件啦。
VOC 增强数据集所使用的验证数据和测试数据集与原始 VOC 2012 一致,所以直接将原本的 val.txt 和 test.txt 文件放在增强数据集目录下即可。
数据索引文件下载链接:VOC增强数据集数据索引文件



















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











