






 本文介绍了如何使用ApacheFlink1.13的JavaAPI在本地模式下消费Kafka主题,并将数据实时写入HadoopHDFS。详细步骤包括启动相关服务、配置依赖、编写代码以及实验验证和时间窗口处理。
本文介绍了如何使用ApacheFlink1.13的JavaAPI在本地模式下消费Kafka主题,并将数据实时写入HadoopHDFS。详细步骤包括启动相关服务、配置依赖、编写代码以及实验验证和时间窗口处理。
1 需求分析
在Java api中,使用flink本地模式,消费kafka主题,并直接将数据存入hdfs中。
flink版本1.13
kafka版本0.8
hadoop版本3.1.4
2 实验过程
2.1 启动服务程序
为了完成 Flink 从 Kafka 消费数据并实时写入 HDFS 的需求,通常需要启动以下组件:
[root@hadoop10 ~]# jps
3073 SecondaryNameNode
2851 DataNode
2708 NameNode
12854 Jps
1975 StandaloneSessionClusterEntrypoint
2391 QuorumPeerMain
2265 TaskManagerRunner
9882 ConsoleProducer
9035 Kafka
3517 NodeManager
3375 ResourceManager
确保 Zookeeper 在运行,因为 Flink 的 Kafka Consumer 需要依赖 Zookeeper。
确保 Kafka Server 在运行,因为 Flink 的 Kafka Consumer 需要连接到 Kafka Broker。
启动 Flink 的 JobManager 和 TaskManager,这是执行 Flink 任务的核心组件。
确保这些组件都在运行,以便 Flink 作业能够正常消费 Kafka 中的数据并将其写入 HDFS。
- 具体的启动命令在此不再赘述。
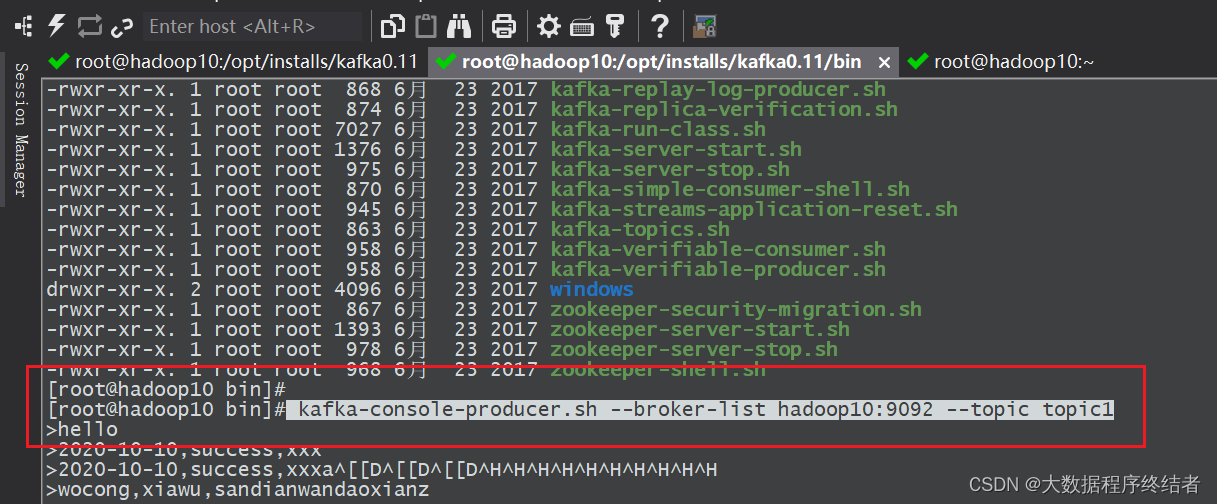
2.2 启动kafka生产
- 当前kafka没有在守护进程后台运行;
- 创建主题,启动该主题的生产者,在kafka的bin目录下执行;
- 此时可以生产数据,从该窗口键入任意数据进行发送。
kafka-topics.sh --zookeeper hadoop10:2181 --create --topic topic1 --partitions 1 --replication-factor 1
kafka-console-producer.sh --broker-list hadoop10:9092 --topic topic1
3 Java API 开发
3.1 依赖
此为项目的所有依赖,包括flink、spark、hbase、ck等,实际本需求无需全部依赖,均可在阿里云或者maven开源镜像站下载。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink-test</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<flink.version>1.13.6</flink.version>
<hbase.version>2.4.0</hbase.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.14.6</version>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
<exclusions>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>${hbase.version}</version>
<exclusions>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.32</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
</dependencies>
<build>
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<!--上传的本地jar的位置-->
<fromFile>target/${project.build.finalName}.jar</fromFile>
<!--远程拷贝的地址-->
<url>scp://root:root@hadoop10:/opt/app</url>
</configuration>
</plugin>
</plugins>
</build>
</project>
- 依赖参考
3.2 代码部分
- 请注意kafka和hdfs的部分需要配置服务器地址,域名映射。
- 此代码的功能是消费
topic1主题,将数据直接写入hdfs中。
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class Test9_kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop10:9092");
properties.setProperty("group.id", "test");
// 使用FlinkKafkaConsumer作为数据源
DataStream<String> ds1 = env.addSource(new FlinkKafkaConsumer<>("topic1", new SimpleStringSchema(), properties));
String outputPath = "hdfs://hadoop10:8020/out240102";
// 使用StreamingFileSink将数据写入HDFS
StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.build();
// 添加Sink,将Kafka数据直接写入HDFS
ds1.addSink(sink);
ds1.print();
env.execute("Flink Kafka HDFS");
}
}
4 实验验证
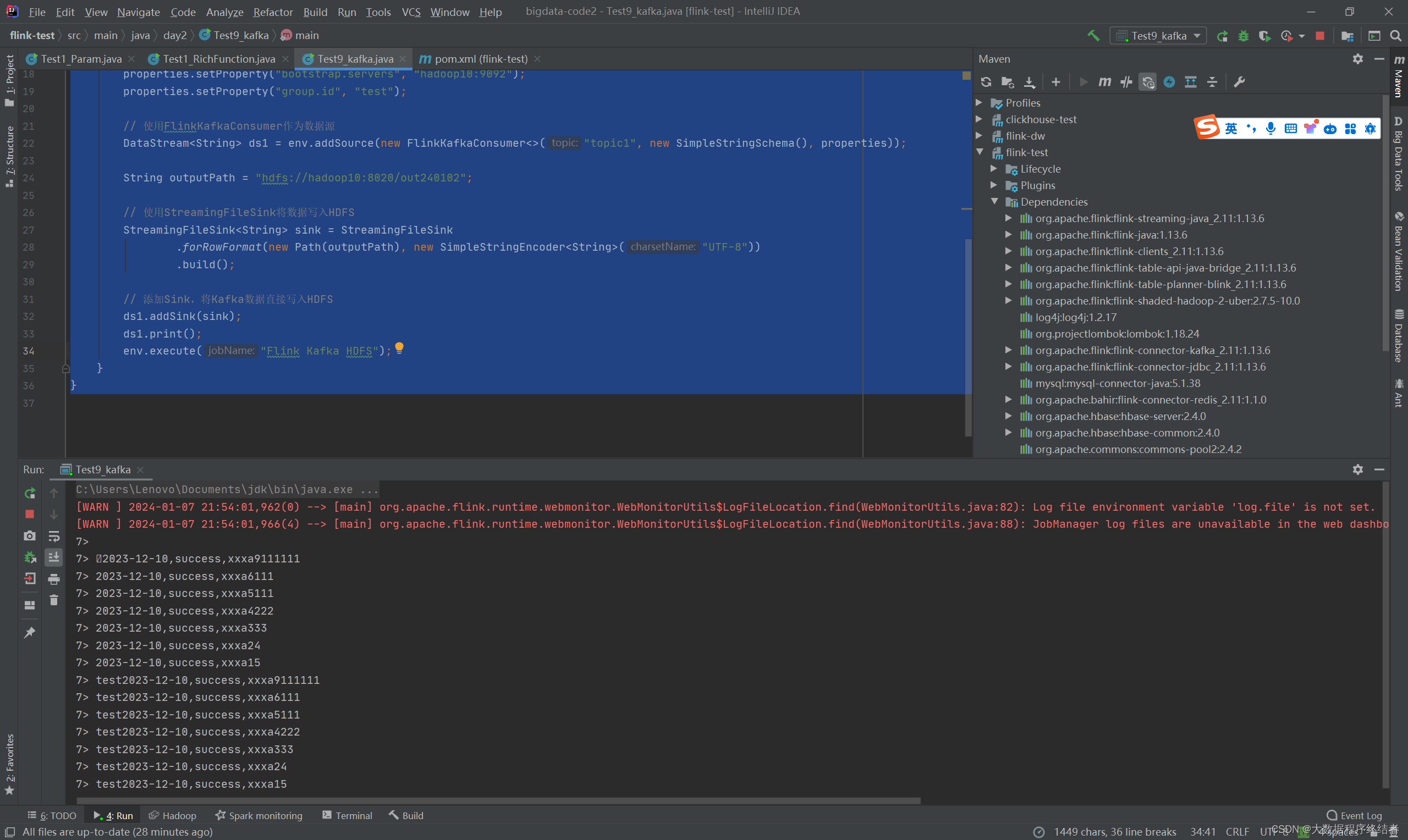
STEP1
运行idea代码,程序开始执行,控制台除了日志外为空。下图是已经接收到生产者的数据后,消费在控制台的截图。
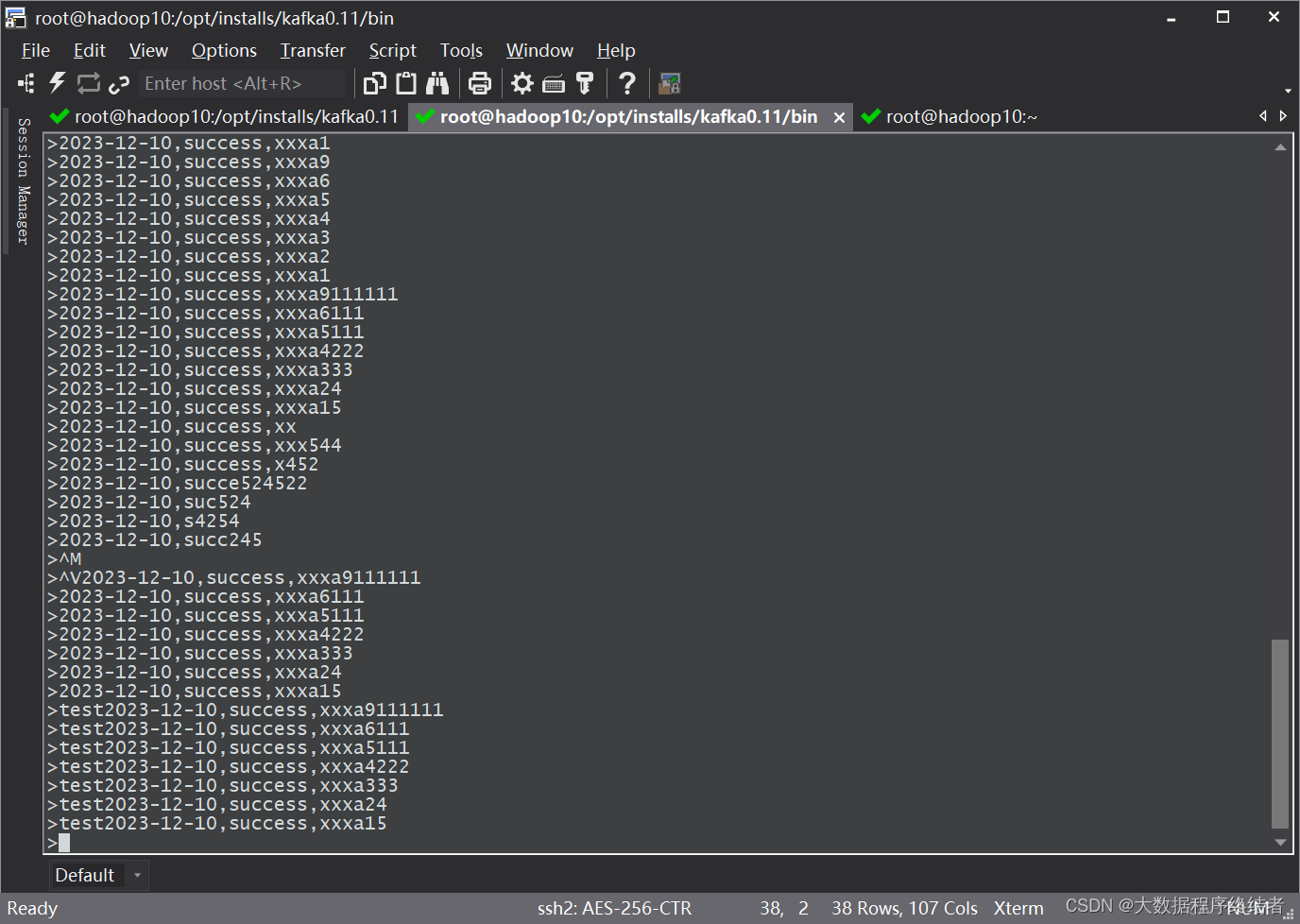
STEP2
启动生产者,将数据写入,数据无格式限制,随意填写。此时发送的数据,是可以在STEP1中的控制台中看到屏幕打印结果的。
STEP3
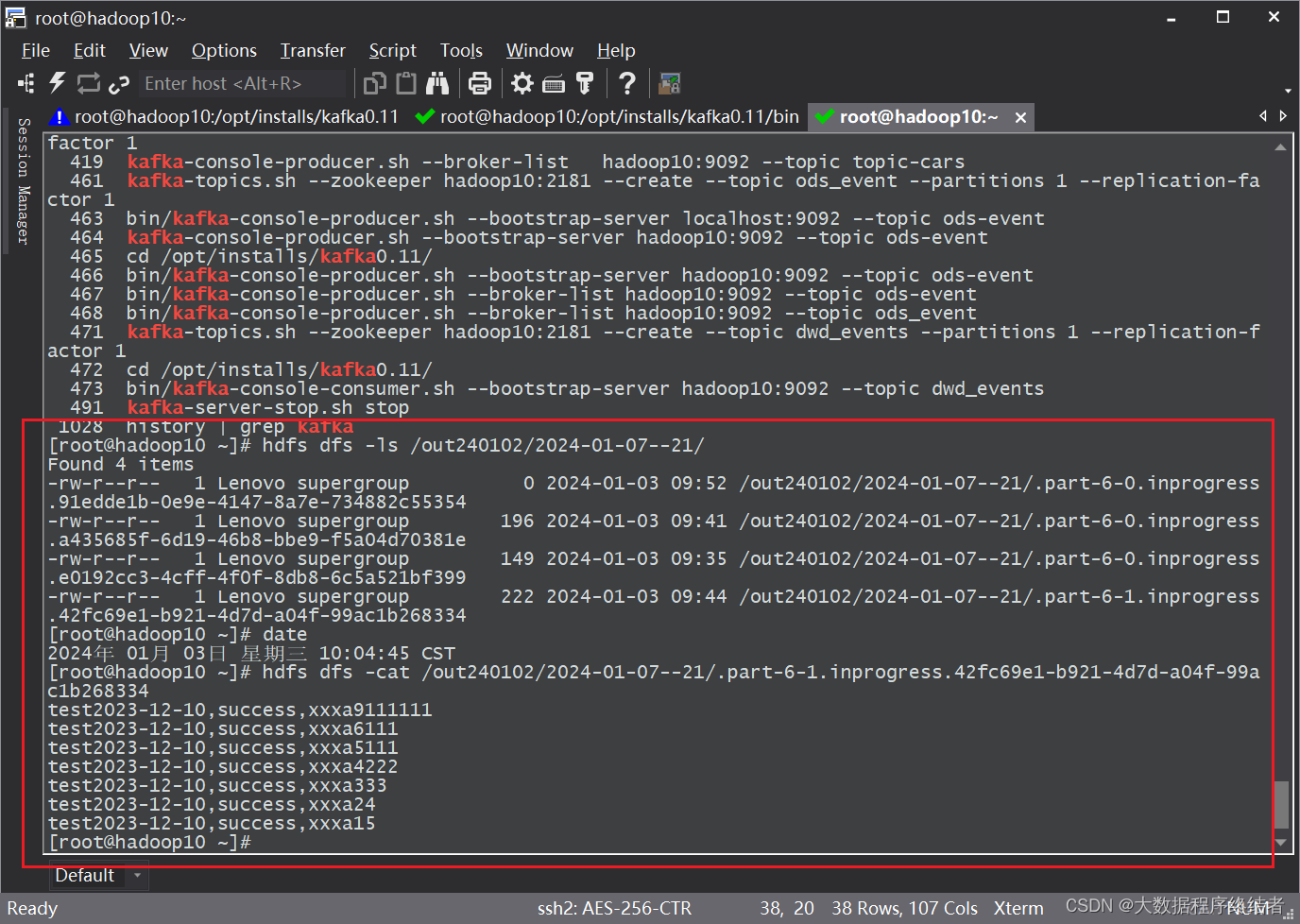
在HDFS中查看对应的目录,可以看到数据已经写入完成。
我这里生成了多个inprogress文件,是因为我测试了多次,断码运行了多次。ide打印在屏幕后,到hdfs落盘写入,中间有一定时间,需要等待,在HDFS中刷新数据,可以看到文件大小从0到被写入数据的过程。
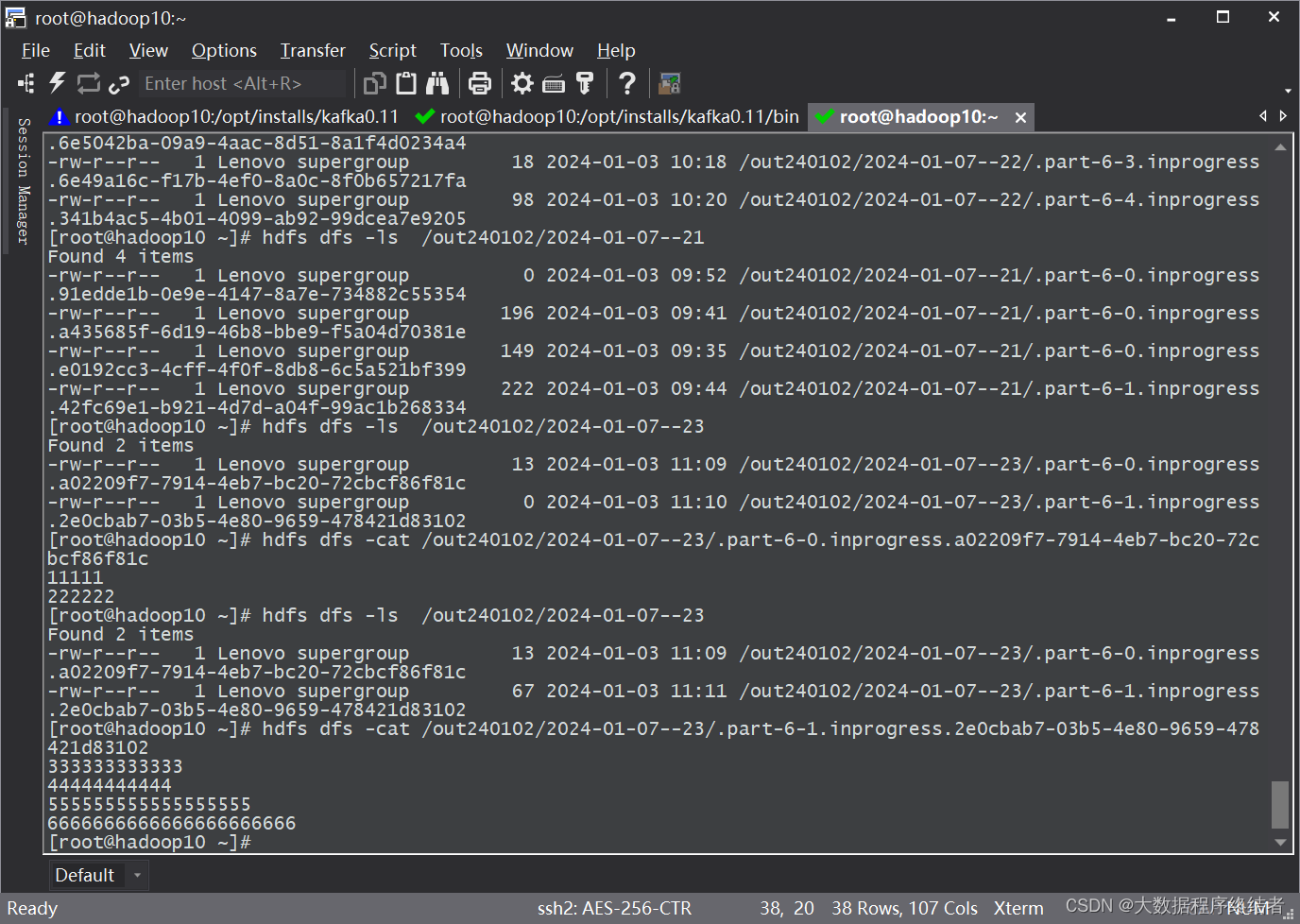
5 时间窗口
- 使用另一种思路实现,以时间窗口的形式,将数据实时写入HDFS,实验方法同上。截图为发送数据消费,并且在HDFS中查看到数据。
package day2;
import day2.CustomProcessFunction;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class Test9_kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop10:9092");
properties.setProperty("group.id", "test");
// 使用FlinkKafkaConsumer作为数据源
DataStream<String> ds1 = env.addSource(new FlinkKafkaConsumer<>("topic1", new SimpleStringSchema(), properties));
String outputPath = "hdfs://hadoop10:8020/out240102";
// 使用StreamingFileSink将数据写入HDFS
StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.build();
// 在一个时间窗口内将数据写入HDFS
ds1.process(new CustomProcessFunction()) // 使用自定义 ProcessFunction
.addSink(sink);
// 执行程序
env.execute("Flink Kafka HDFS");
}
}
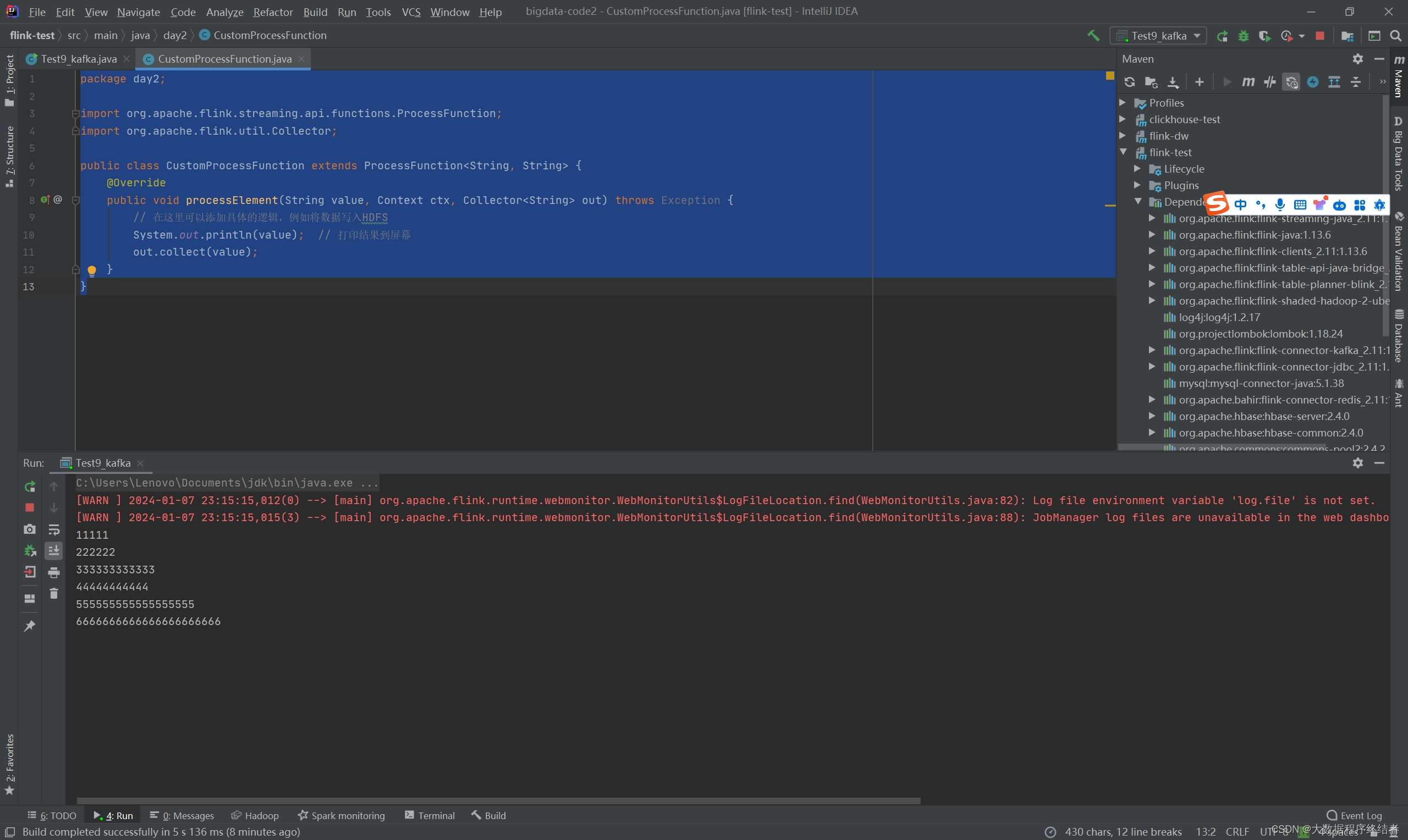
package day2;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
public class CustomProcessFunction extends ProcessFunction<String, String> {
@Override
public void processElement(String value, Context ctx, Collector<String> out) throws Exception {
// 在这里可以添加具体的逻辑,例如将数据写入HDFS
System.out.println(value); // 打印结果到屏幕
out.collect(value);
}
}
















 1710
1710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











