









上次的例子https://blog.csdn.net/xxkalychen/article/details/117149540?spm=1001.2014.3001.5502将Flink的数据源设置为Socket,只是为了测试提供流式数据。生产中一般不会这么用,标准模型是从消息队列获取流式数据。Flink提供了跟kafka连接的封装,我们只需要一点小小的改动就可以实现从Kafka获取数据。
不过修改之前,需要搭建一个Kafka服务器。具体搭建过程这里不做详述。现在我们来修改程序。
一、添加pom依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>其版本要和flink保持一致。
二、修改测试类。我们另外创建一个测试类。
package com.chris.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Arrays;
import java.util.Properties;
/**
* @author Chris Chan
* Create on 2021/5/22 7:23
* Use for:
* Explain: Flink流式处理从Kafka获取的数据
*/
public class KafkaStreamTest {
public static void main(String[] args) throws Exception {
new KafkaStreamTest().execute(args);
}
private void execute(String[] args) throws Exception {
//获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//配置kafka
Properties properties = new Properties();
properties.put("bootstrap.servers", "flink.chris.com:9092");
properties.put("group.id", "flink_group_1");
//从socket获取数据
DataStreamSource<String> streamSource = env.addSource(new FlinkKafkaConsumer<String>("topic_flink", new SimpleStringSchema(), properties));
//wordcount计算
SingleOutputStreamOperator<Tuple2<String, Integer>> operator = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
/**
* map计算
* @param value 输入数据 用空格分隔的句子
* @param out map计算之后的收集器
* @throws Exception
*/
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//用空格分隔为单词
String[] words = value.split(" ");
//统计单词使用频次,放入收集器
Arrays.stream(words)
//洗去前后空格
.map(String::trim)
//过滤掉空字符串
.filter(word -> !"".equals(word))
//加入收集器
.forEach(word -> out.collect(new Tuple2<>(word, 1)));
}
})
//按照二元组第一个字段word分组,把第二个字段统计出来
.keyBy(0).sum(1);
operator.print();
env.execute();
}
}
修改的部分也是四行。
//配置kafka
Properties properties = new Properties();
properties.put("bootstrap.servers", "flink.chris.com:9092");
properties.put("group.id", "flink_group_1");
//从socket获取数据
DataStreamSource<String> streamSource = env.addSource(new FlinkKafkaConsumer<String>("topic_flink", new SimpleStringSchema(), properties));配置一下Kafka的服务器和消费者分组,然后创建消费者,从Kafka获取数据。
三、测试。
测试之前,首先启动zookeeper和kafka,并且让kafka处于主题消息生产发送状态。
nohup /var/app/kafka_2.13-2.8.0/bin/zookeeper-server-start.sh /var/app/kafka_2.13-2.8.0/config/zookeeper.properties > /var/app/kafka_2.13-2.8.0/logs/zookeeper.log 2>&1 &
nohup /var/app/kafka_2.13-2.8.0/bin/kafka-server-start.sh /var/app/kafka_2.13-2.8.0/config/server.properties > /var/app/kafka_2.13-2.8.0/logs/kafka.log 2>&1 &/var/app/kafka_2.13-2.8.0/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic_flink运行程序,在kafka输入数据。

查看后台。
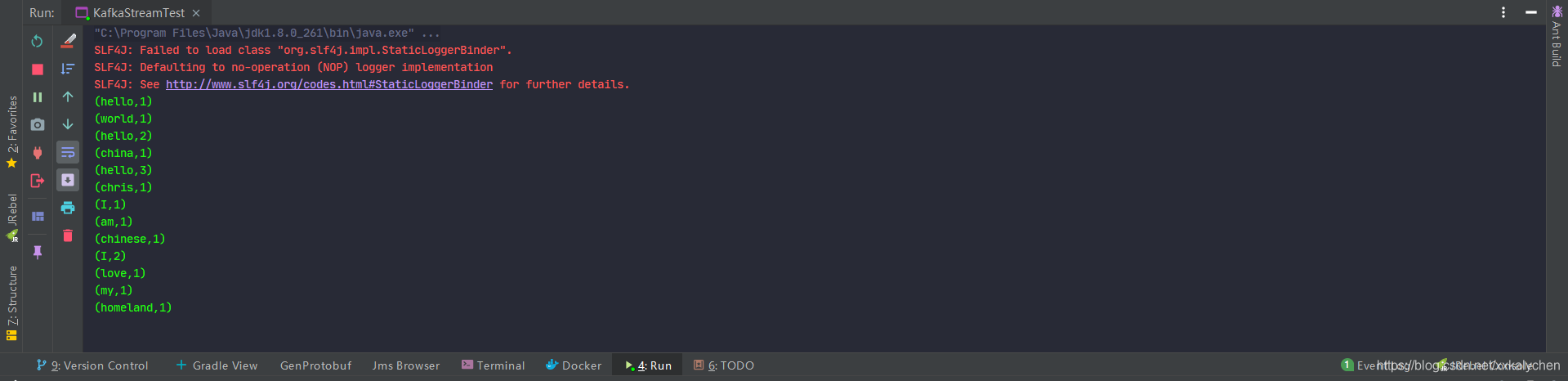
提交到集群执行效果。
可是并不成功,原因很简单,Flink集群只包含Flink基本必须的包,对于工程中使用的其他包是不包含的,所以会出现找不到相关类的异常。因此我们还需要配置maven的assmbly插件,采用完全打包的方式。
在pom中添加
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.chris.flink.KafkaStreamTest</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>这个配置指定了一个主类。
然后打包。
mvn clean package assembly:assembly打包过程耗时比较长,因为这种方法需要把依赖包全都打包进去。打包完成之后,在target下有个
flink-demo-20210522-1.0.0-SNAPSHOT-jar-with-dependencies.jar这就是我们需要的完整jar包了。
把这个包从页面传上去,创建任务时发现主类已经填好了,就是因为我们已经在清单中配置了一个主类。如果要使用其他主类,就修改。
提交之后,稍等一会,就处于运行状态,等待数据。
我们在kafka输入数据。

查看线上标准输出。

测完之后,发现之前有个小担心不存在。原来在测试storm时,本地需要的基础包在线上不能有,否则会冲突,所以不停在改pom中的作用域,很是折腾人。原以为flink也会出现这种问题,结果没有,轻松好多。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









