







1. 下载和准备工作
1.1 安装包下载
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/
访问apche官网源,下载3.3.4版本,我们用二进制通用版即可,因为hadoop运行在java环境,跨平台性使得无需编译arm架构版本。Hadoop 3.3.4 是当前稳定版本,兼容性和长期支持较好。此版本对最新的Spark和Flink以及Hive也有良好的支持。
然后将文件传到服务器ubuntu1节点。
1.2 前提条件
本次安装实验基于苹果m2芯片的mac系统,使用vmware fusion搭建三台ubuntu24分布式虚拟机,确保在三台机器上安装了Java jdk8,并配置了免密码登录,网络互通,防火墙关闭,授时服务器已经同步。如无提示,本次所有安装步骤均在root用户权限下进行。
| hostname | ip |
|---|---|
| ubuntu1 | 172.16.167.131 |
| ubuntu2 | 172.16.167.132 |
| ubuntu3 | 172.16.167.133 |
2. 安装过程
安装过程中遇到的报错已经在5. 安装报错小节中体现。本小节的所有配置和步骤均为优化后的无坑版安装方式。
STEP 1: 解压并配置Hadoop
首先,使用su rootroot权限,在Ubuntu1上解压Hadoop并配置环境变量:
tar -xzf hadoop-3.3.4.tar.gz
mv hadoop-3.3.4 /usr/local/hadoop
# 配置环境变量
vim ~/.bashrc
# 添加JDK路径到PATH
export JAVA_HOME=/usr/local/jdk1.8.0_411
export PATH=$PATH:$JAVA_HOME/bin
# 设置Hadoop环境变量
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
# 添加Hadoop路径到PATH
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 刷新环境
source ~/.bashrc
首先要有java jdk的环境变量,java在此前已经成功配置。
如果已经在 ~/.bashrc 中添加了Hadoop和JDK的环境变量,并且是以 root 用户登录和运行Hadoop,那么通常情况下不需要在 /etc/profile 中再次添加这些环境变量。配置在 ~/.bashrc 中已经足够确保在每次以 root 用户打开新的终端时,这些环境变量都会生效。
选择环境变量添加位置的原则
- 仅需要特定用户生效:在用户的
~/.bashrc文件中添加环境变量,当前我们以root用户权限登录。 - 需要所有用户生效:在
/etc/profile文件中添加环境变量。
如果你希望这些环境变量在所有用户登录时都生效(例如,你有多个用户需要运行Hadoop),可以考虑将这些配置添加到 /etc/profile 中。这可以确保所有用户登录时都能够使用这些环境变量。
检查环境变量是否生效
在控制台打印以下内容,如果回显出正确路径,即为配置成功。
echo $JAVA_HOME
echo $HADOOP_HOME
echo $PATH
STEP 2: 配置Hadoop
修改Hadoop配置文件。其中HADOOP_HOME已经设置为/usr/local/hadoop。
2.1. 修改core-site.xml
请在三台服务器上创建目录/home/hadoop/tmp并赋予777权限,赋予777权限在生产环境并不是安全的方式,请注意。
目录权限的推荐分配方式:
- 专用用户和组:通常情况下,Hadoop会运行在一个专用用户(例如,
hadoop用户)和一个专用组(例如,hadoop组)下。确保这些目录的所有者是该用户和组,在这里我们为了方便,只用root用户。 - 适当的权限设置:通常情况下,目录的权限设置为750(即,所有者具有读、写和执行权限,组具有读和执行权限,其他人没有任何权限)或700(即,只有所有者具有读、写和执行权限)。这可以有效地保护数据不被非授权用户访问和修改。
vim $HADOOP_HOME/etc/hadoop/core-site.xml添加以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ubuntu1:9000</value>
</property>
<!--指定hadoop 数据的存储目录默认为/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<!--hive.hosts 允许 root 代理用户访问 Hadoop 文件系统设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--hive.groups 允许 Hive 代理用户访问 Hadoop 文件系统设置 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--配置缓存区的大小,实际可根据服务器的性能动态做调整-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--开启hdfs垃圾回收机制,可以将删除数据从其中回收,单位为分钟-->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
配置Hadoop核心的通用设置:
fs.defaultFS:指定HDFS的默认文件系统URI。hadoop.tmp.dir:Hadoop的临时文件目录。hadoop.proxyuser.root.hosts和hadoop.proxyuser.root.groups:允许root代理用户访问Hadoop文件系统。hadoop.http.staticuser.user:配置HDFS网页登录的静态用户为root。io.file.buffer.size:配置文件缓冲区大小。fs.trash.interval:设置HDFS垃圾回收机制的时间间隔。
2.2. 修改hdfs-site.xml
在$HADOOP_HOME/etc/hadoop/hdfs-site.xml中添加以下内容:
请在三台服务器创建目录/home/hadoop/dfs/name和/home/hadoop/dfs/data并赋予777权限。
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ubuntu2:9868</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<!--指定datanode数据存储节点位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
</configuration>
配置HDFS的相关设置:
dfs.replication:HDFS中每个块的副本数。dfs.namenode.secondary.http-address:Secondary NameNode的HTTP地址。dfs.namenode.name.dir:NameNode数据的存储路径。dfs.datanode.data.dir:DataNode数据的存储路径。
2.3. 修改mapred-site.xml
在$HADOOP_HOME/etc/hadoop/mapred-site.xml中添加以下内容:
<configuration>
<property>
<name>mapred.local.dir</name>
<value>/home/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
配置MapReduce框架的相关设置:
mapred.local.dir:MapReduce本地目录。mapreduce.framework.name:MapReduce框架名称(这里设置为YARN)。yarn.app.mapreduce.am.env、mapreduce.map.env、mapreduce.reduce.env:指定MapReduce的环境变量。
2.4. 修改yarn-site.xml
在$HADOOP_HOME/etc/hadoop/yarn-site.xml中添加以下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>172.16.167.131</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置YARN的相关设置:
yarn.resourcemanager.hostname:ResourceManager的主机名。yarn.nodemanager.aux-services:NodeManager的辅助服务(如MapReduce Shuffle)。
2.5. 修改hadoop-env.sh
在$HADOOP_HOME/etc/hadoop/hadoop-env.sh中添加以下内容:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# Java path
export JAVA_HOME=/usr/local/jdk1.8.0_411
# Hadoop Heap Size
export HADOOP_HEAPSIZE=1024
# Log Directory
export HADOOP_LOG_DIR=/var/log/hadoop
HDFS_NAMENODE_USER、HDFS_DATANODE_USER、HDFS_SECONDARYNAMENODE_USER、YARN_RESOURCEMANAGER_USER、YARN_NODEMANAGER_USER:Hadoop和YARN组件的用户为root。JAVA_HOME:Java路径。HADOOP_HEAPSIZE:Hadoop的堆内存大小。HADOOP_LOG_DIR:Hadoop日志目录。
STEP 3: 配置workers和slaves文件
在$HADOOP_HOME/etc/hadoop/workers和$HADOOP_HOME/etc/hadoop/slaves文件中添加以下内容:
ubuntu1
ubuntu2
ubuntu3
用于指定Hadoop和YARN集群中工作节点的列表。slaves为集群中的所有DataNode和NodeManager节点的主机名。workers为YARN集群中的所有NodeManager节点的主机名。
STEP 4: 分发Hadoop到其他节点
将Hadoop分发到其他两台机器,即为ubuntu2和ubuntu3:
scp -r /usr/local/hadoop root@172.16.167.132:/usr/local/
scp -r /usr/local/hadoop root@172.16.167.133:/usr/local/
STEP 5: 格式化Hadoop文件系统
这一步是必须的,因为它在HDFS的NameNode上创建文件系统元数据,并设置基本的存储结构 。
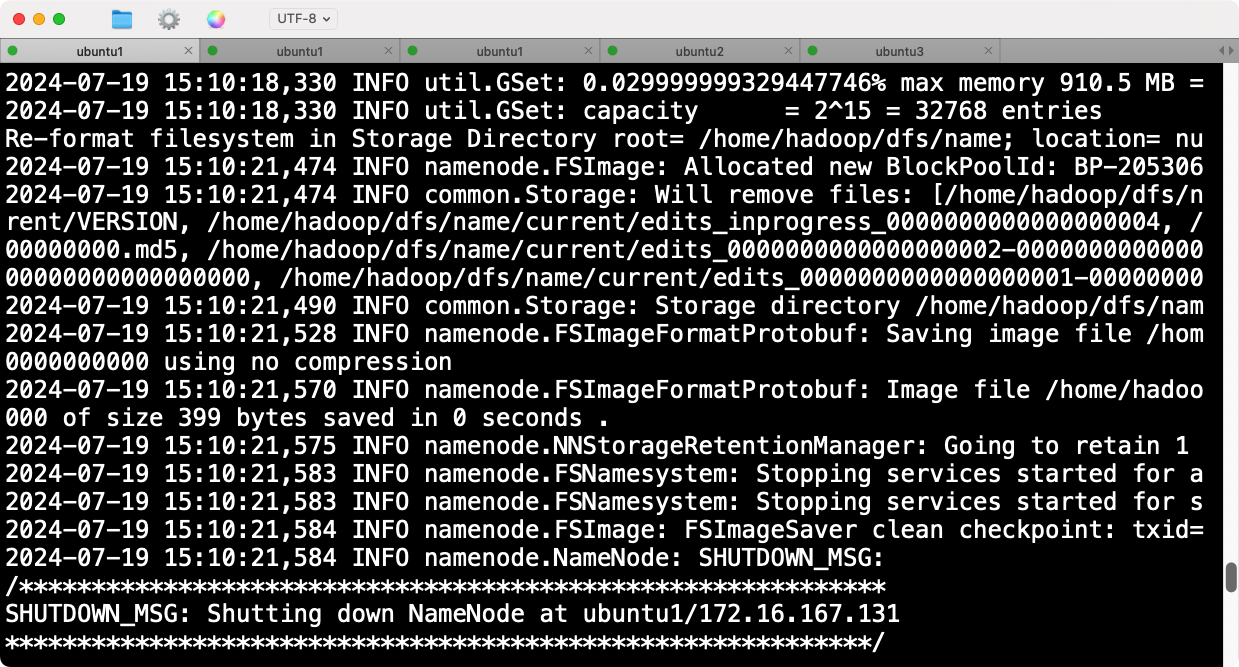
在主节点(Ubuntu1)上格式化HDFS:
hdfs namenode -format
STEP 6: 启动Hadoop
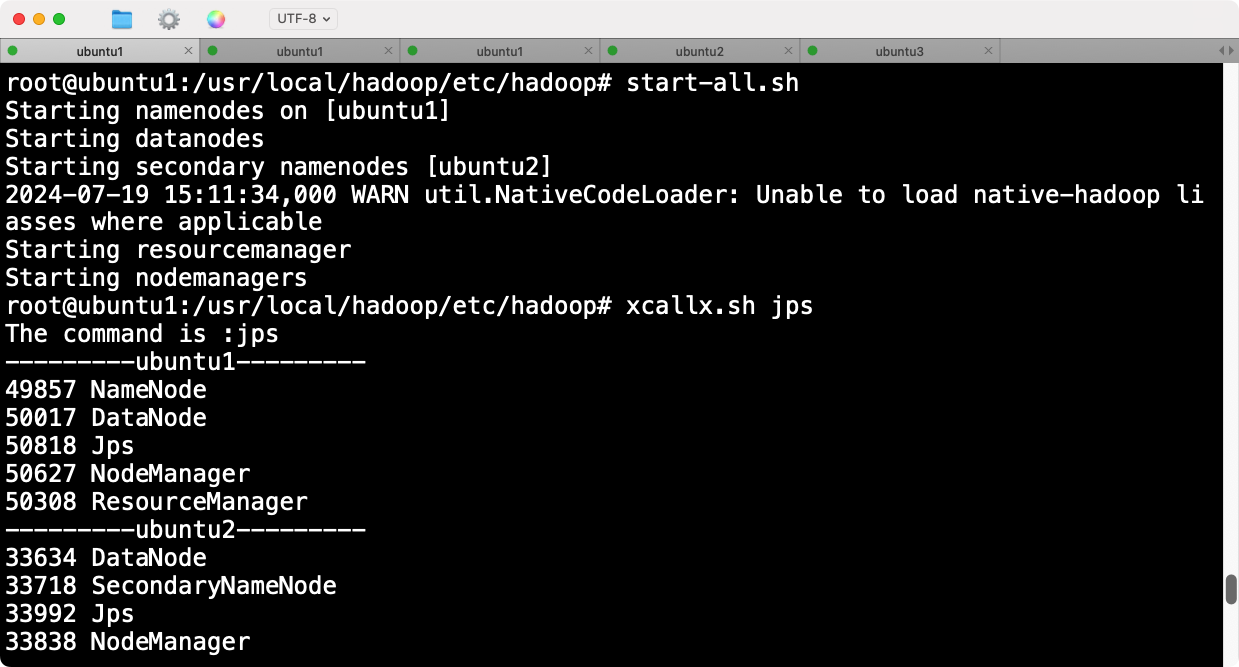
在主节点(Ubuntu1)上启动Hadoop:
start-all.sh
3. 验证HDFS
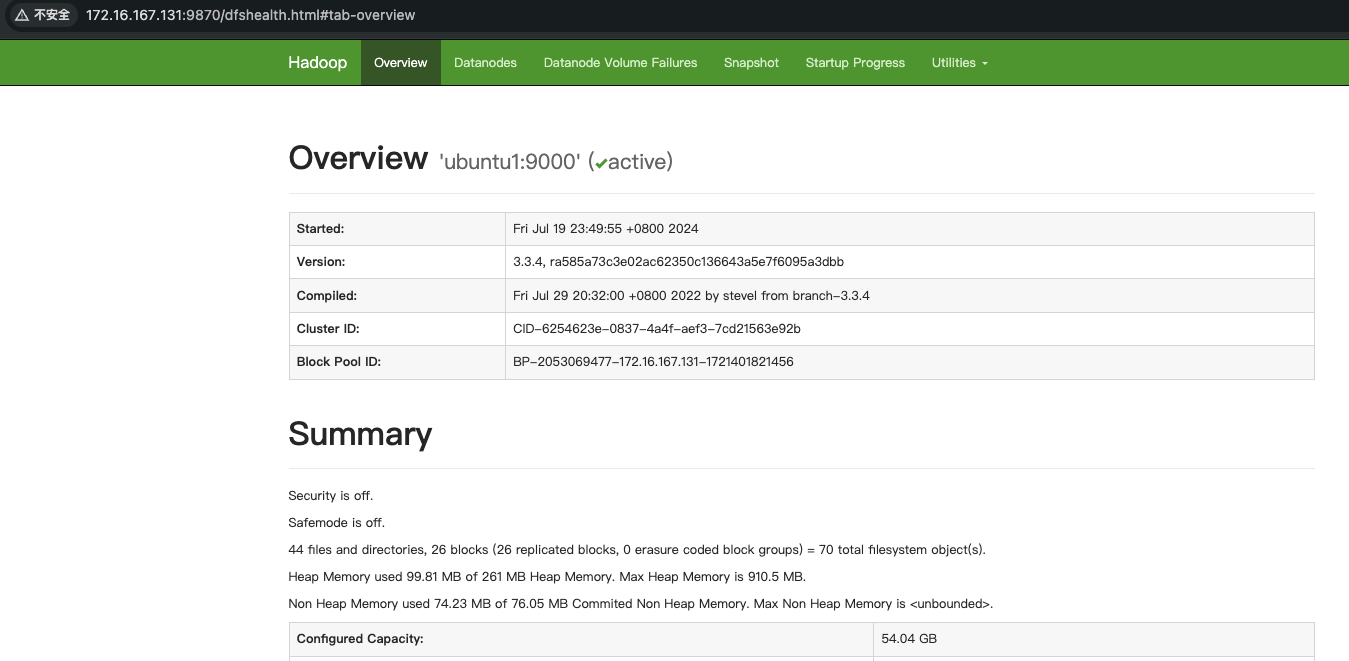
通过Web界面验证Hadoop集群状态:
- NameNode:
http://172.16.167.131:9870 - ResourceManager:
http://172.16.167.131:8088
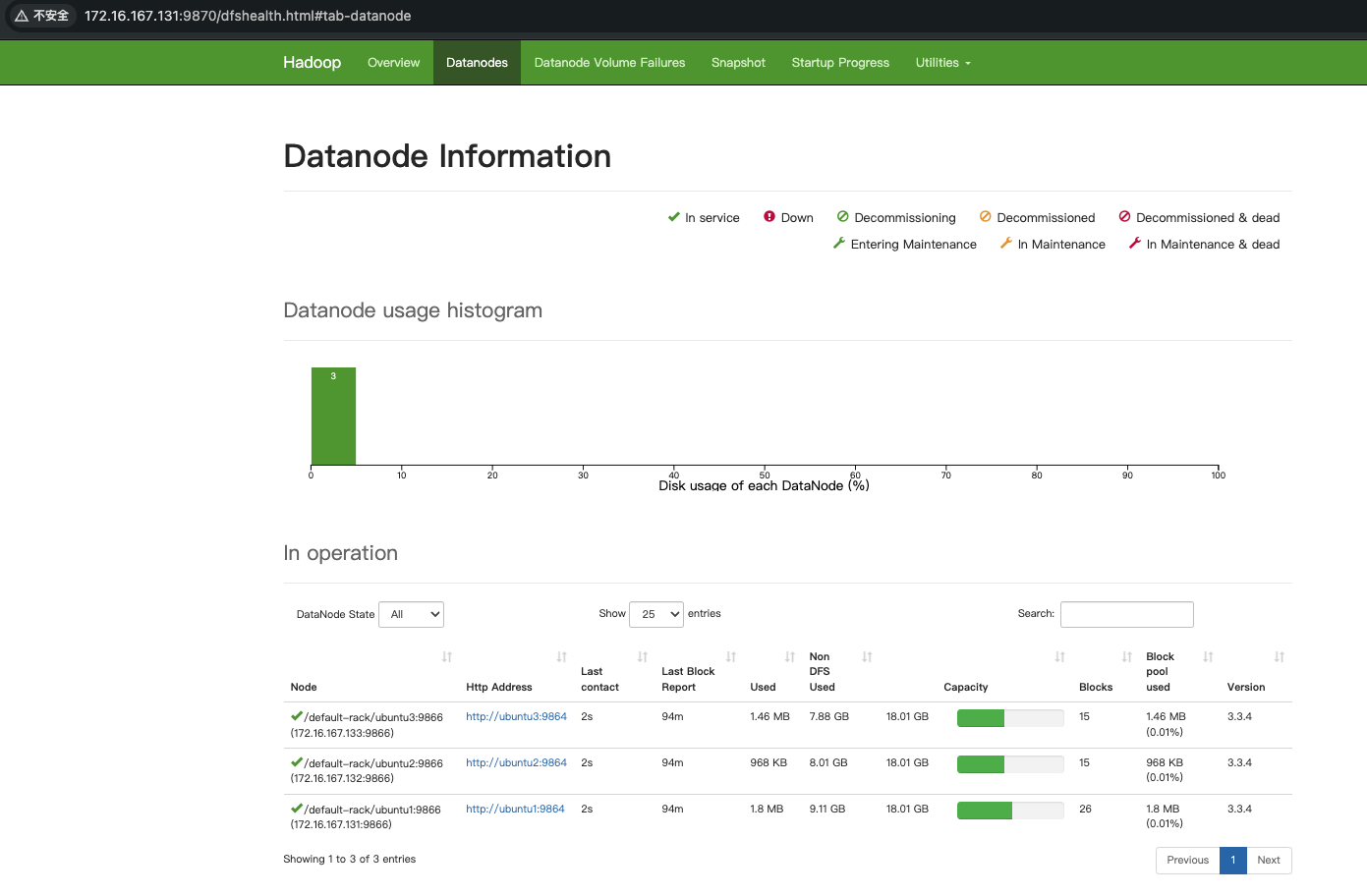
通过命令行验证:
hdfs dfsadmin -report
root@ubuntu1:/usr/local/hadoop/etc/hadoop# hdfs dfsadmin -report
2024-07-19 15:12:18,038 WARN util.NativeCodeLoader: Unable to load native-hadoop liasses where applicable
Configured Capacity: 58028212224 (54.04 GB)
Present Capacity: 28156723200 (26.22 GB)
DFS Remaining: 28156649472 (26.22 GB)
DFS Used: 73728 (72 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (3):
Name: 172.16.167.131:9866 (ubuntu1)
Hostname: ubuntu1
Decommission Status : Normal
Configured Capacity: 19342737408 (18.01 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 9780330496 (9.11 GB)
DFS Remaining: 8553865216 (7.97 GB)
DFS Used%: 0.00%
DFS Remaining%: 44.22%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Fri Jul 19 15:12:18 UTC 2024
Last Block Report: Fri Jul 19 15:11:30 UTC 2024
Num of Blocks: 0
Name: 172.16.167.132:9866 (ubuntu2)
Hostname: ubuntu2
Decommission Status : Normal
Configured Capacity: 19342737408 (18.01 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 8600797184 (8.01 GB)
DFS Remaining: 9733398528 (9.06 GB)
DFS Used%: 0.00%
DFS Remaining%: 50.32%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Fri Jul 19 15:12:17 UTC 2024
Last Block Report: Fri Jul 19 15:11:35 UTC 2024
Num of Blocks: 0
Name: 172.16.167.133:9866 (ubuntu3)
Hostname: ubuntu3
Decommission Status : Normal
Configured Capacity: 19342737408 (18.01 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 8464809984 (7.88 GB)
DFS Remaining: 9869385728 (9.19 GB)
DFS Used%: 0.00%
DFS Remaining%: 51.02%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Fri Jul 19 15:12:18 UTC 2024
Last Block Report: Fri Jul 19 15:11:30 UTC 2024
Num of Blocks: 0
能够看到三个节点的信息,至此,Hadoop分布式安装完成。
4. 用world count和pi测试mapreduce
我们可以使用Hadoop自带的示例程序进行测试,如pi或wordcount。以下是STEP:
4.1 运行Pi计算示例
- 运行Pi计算示例 在
ubuntu1节点上执行以下命令:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar pi 10 100
- 查看输出 执行上述命令后:
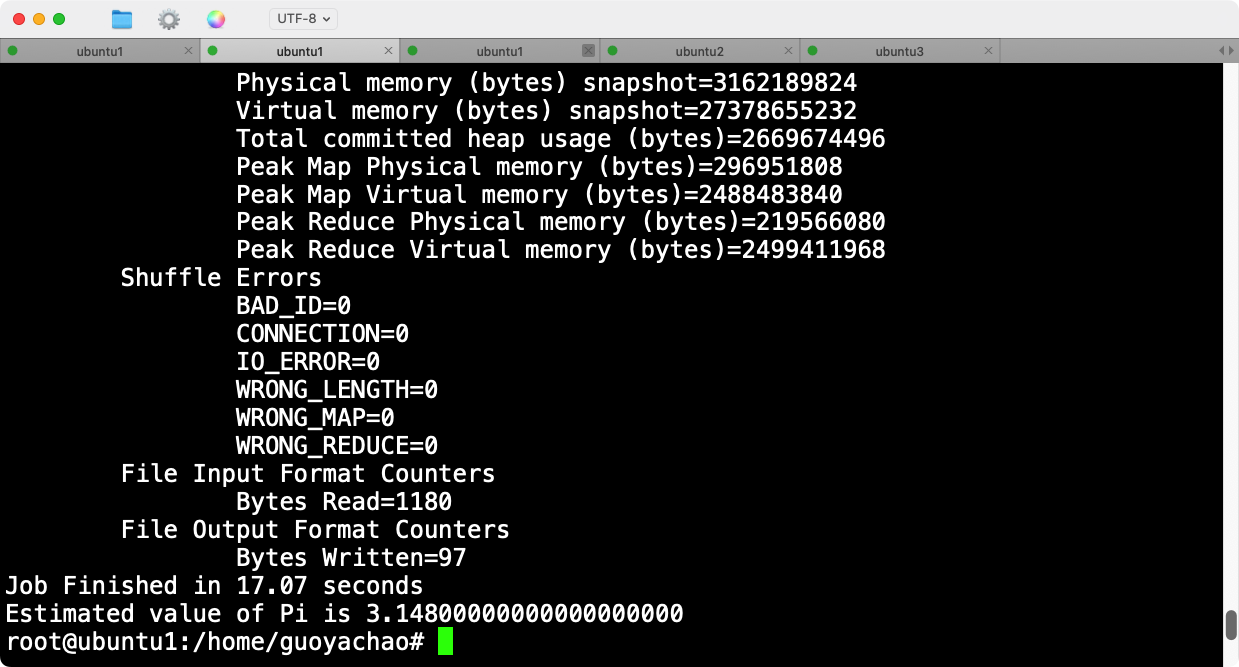
4.2 运行WordCount示例
- 准备输入文件 创建一个输入文件夹并准备一个输入文件:
hadoop fs -mkdir -p /user/root/input
echo "Hello Hadoop" > input.txt
hadoop fs -put input.txt /user/root/input/
- 运行WordCount示例 在
ubuntu1节点上执行以下命令:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/root/input /user/root/output
- 查看输出 运行上述命令后,查看输出结果:
hadoop fs -cat /user/root/output/part-r-00000
会看到如下的输出: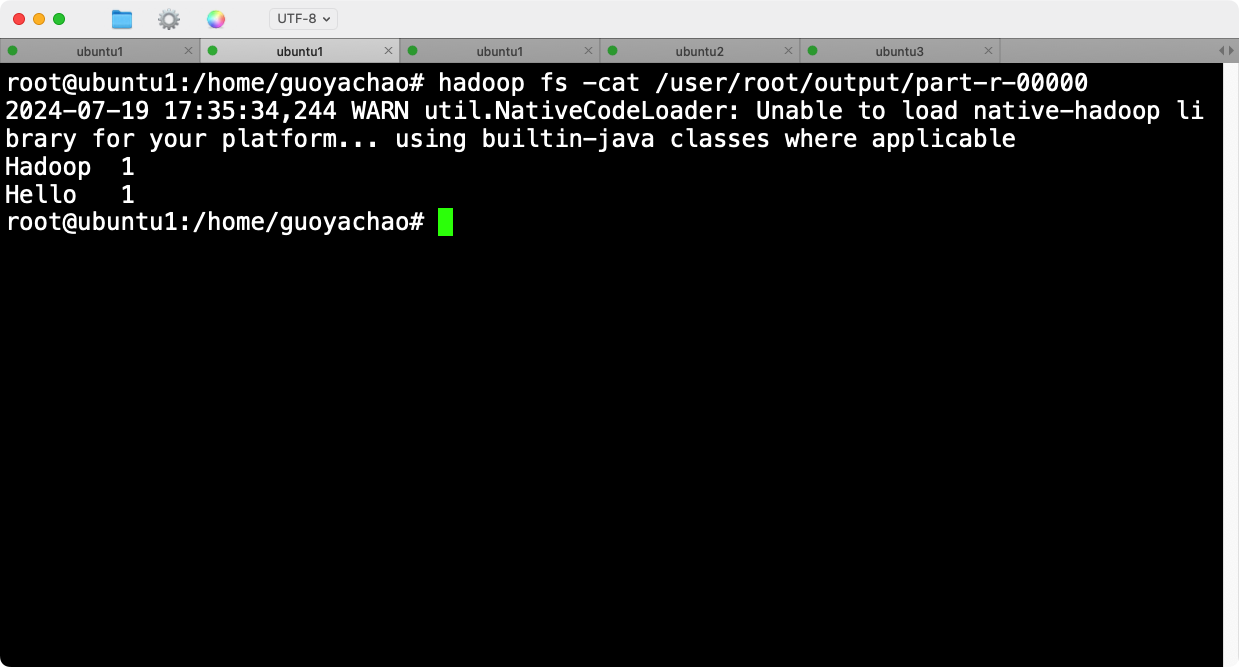
验证集群状态
- 检查JobTracker和TaskTracker状态 通过Hadoop Web UI来检查集群状态。默认端口为9870和8088,分别用于HDFS和YARN资源管理器。可以在浏览器中访问
http://ubuntu1:9870和http://ubuntu1:8088。
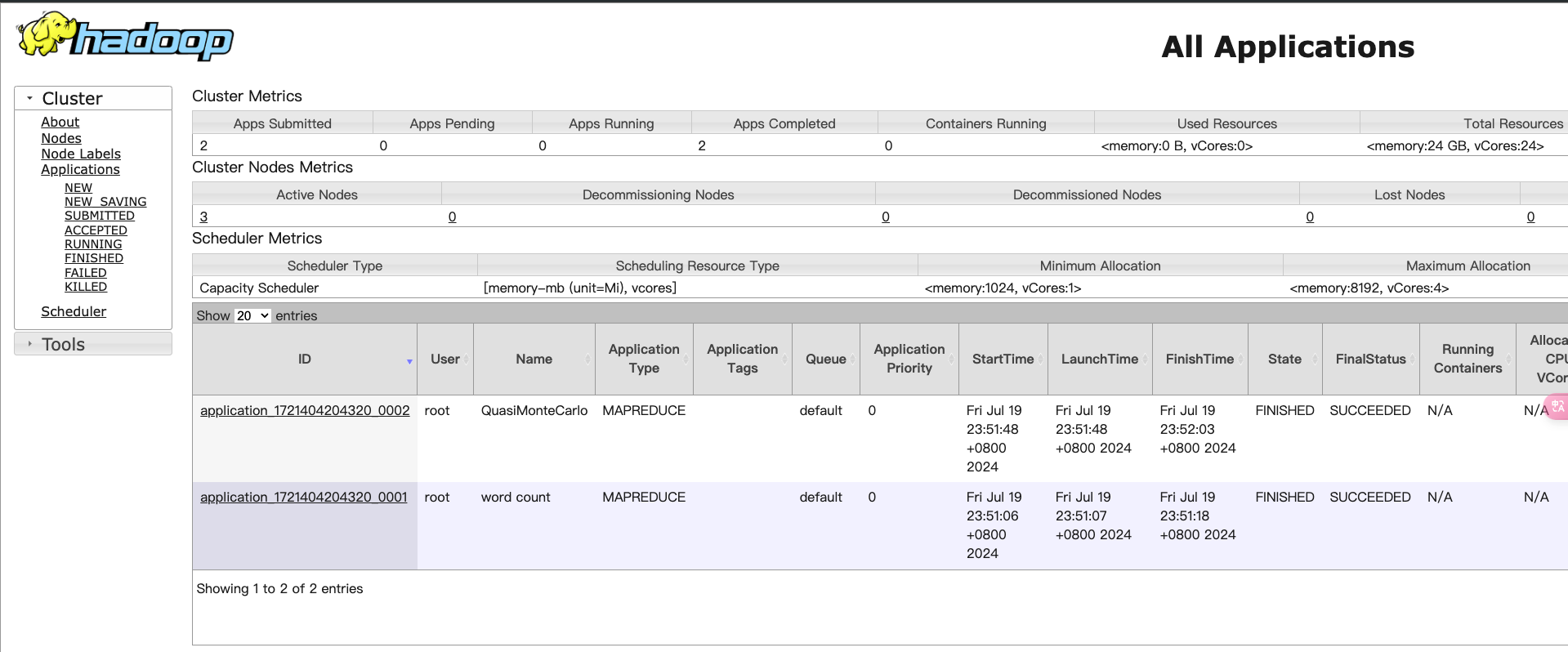
- 检查日志 如果有任务失败,请查看相关日志文件。可以通过以下命令查看日志:
yarn logs -applicationId <application_id>
通过上述STEP,你可以验证Hadoop集群是否配置正确并正常运行。如果示例程序运行成功,则说明集群配置和操作均正常。
5. 安装报错
5.1 datanode无法通信
问题描述
在执行完hadoop namenode -format后,显示成功: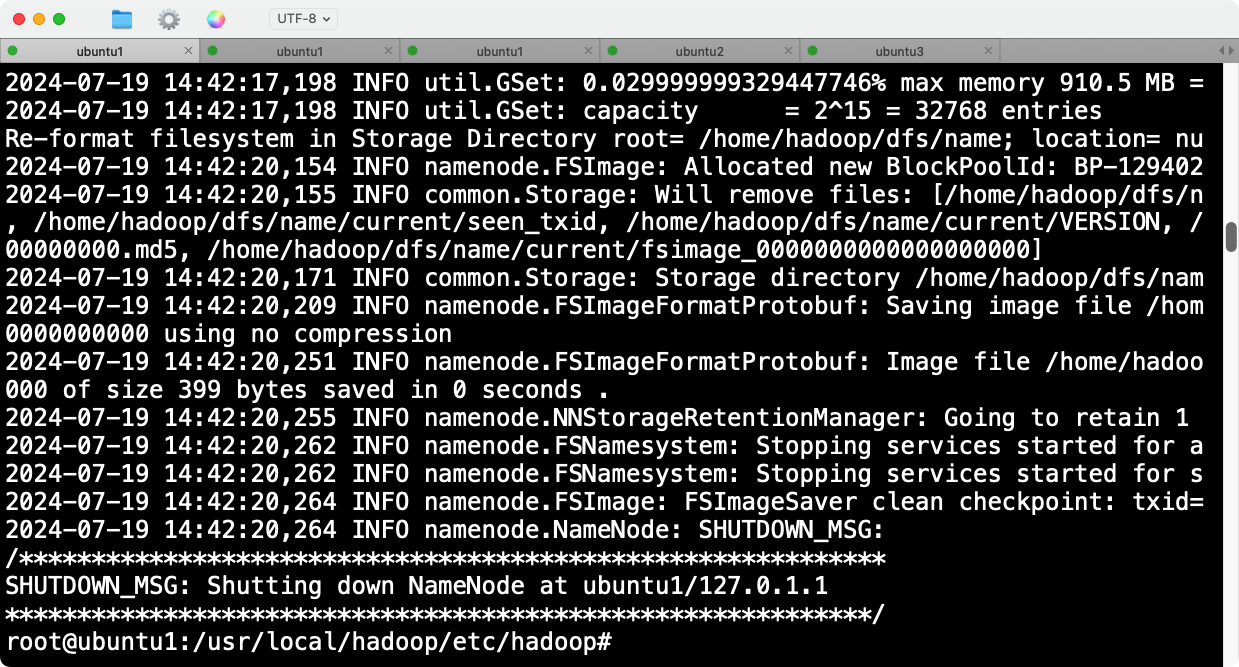
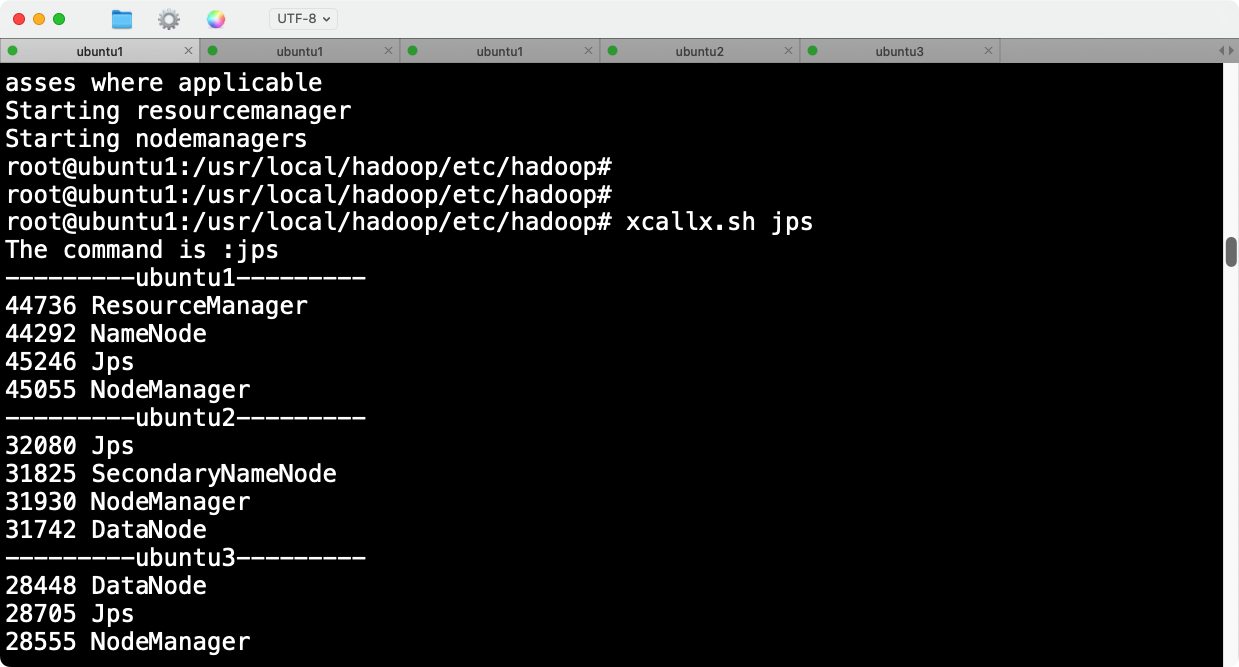
但是此时是有问题的,start-all.sh之后,虽然三台机器的jps组件都启动了,但是节点没有正确挂载。
执行hdfs dfsadmin -report时,hdfs显示空间都是0B。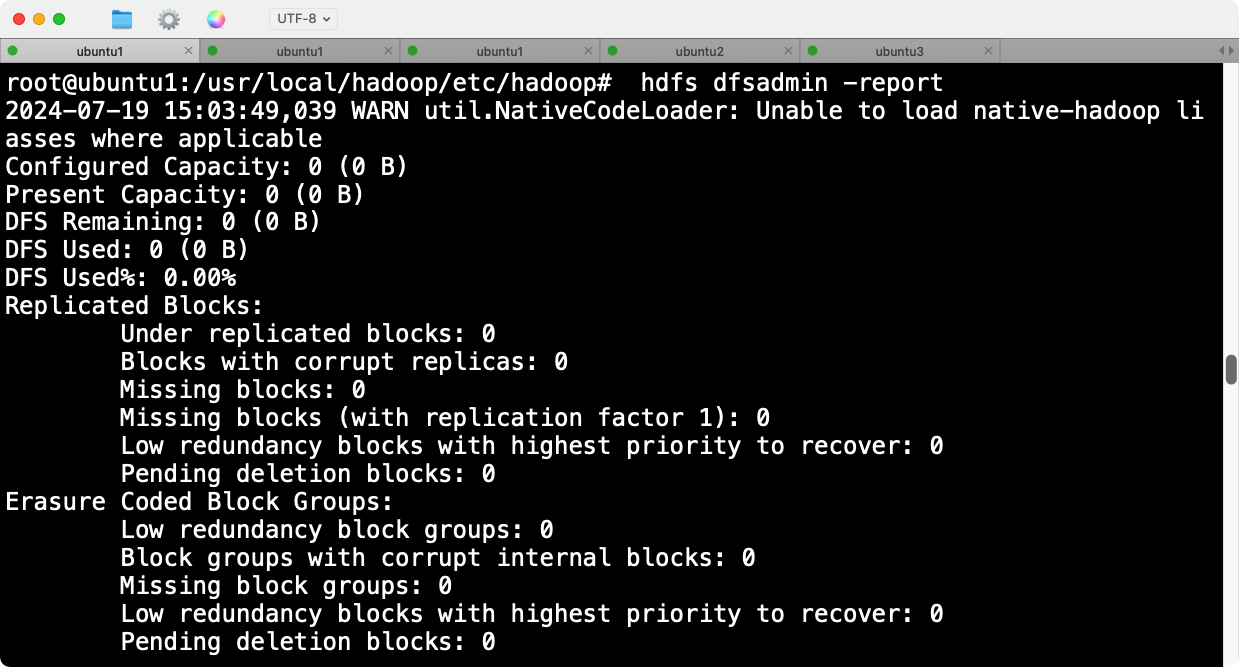
在web界面查看时,也会发现没有datanode被挂载。
解决方案
检查日志后发现,最后一行回显SHUTDOWN_MSG: Shutting down DataNode at ubuntu1/127.0.1.1问题很大,ubuntu1的ip地址疑似错误,部分报错回显如下:
2024-07-19 15:03:16,943 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/hadoop/dfs/data
java.io.IOException: Incompatible clusterIDs in /home/hadoop/dfs/data: namenode clusterID = CID-350e5541-e6fd-4878-97eb-99e5f49ce6bc; datanode clusterID = CID-74ae0627-07d0-42e3-88d2-80192d548e60
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:746)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:296)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:409)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:389)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:561)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1739)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1675)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:394)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:295)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:854)
at java.lang.Thread.run(Thread.java:750)
2024-07-19 15:03:16,945 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid 472a02d9-87da-4dfd-8869-b82769b840f7) service to ubuntu1/127.0.1.1:9000. Exiting.
java.io.IOException: All specified directories have failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:562)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1739)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1675)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:394)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:295)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:854)
at java.lang.Thread.run(Thread.java:750)
2024-07-19 15:03:16,945 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool <registering> (Datanode Uuid 472a02d9-87da-4dfd-8869-b82769b840f7) service to ubuntu1/127.0.1.1:9000
2024-07-19 15:03:16,946 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Removed Block pool <registering> (Datanode Uuid 472a02d9-87da-4dfd-8869-b82769b840f7)
2024-07-19 15:03:18,947 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Exiting Datanode
2024-07-19 15:03:18,950 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at ubuntu1/127.0.1.1
************************************************************/
从日志中可以看出,问题的关键是namenode和datanode的clusterID不匹配,导致datanode无法启动。每个HDFS集群都有一个唯一的clusterID,在集群初始化时会生成。如果clusterID不匹配,datanode将拒绝连接到namenode。
由于挂载datanode时的报错,我已经重启了多次,格式化了多次,会出现clusterID问题。要解决这个问题,我们需要确保所有节点的clusterID一致。以下是修复步骤:
修复ClusterID不匹配问题
停止所有Hadoop服务
stop-all.sh
在所有节点上删除datanode数据目录
rm -rf /home/hadoop/dfs/data/*
格式化namenode
在ubuntu1上执行:
hdfs namenode -format
确保所有配置文件在所有节点上一致
core-site.xmlhdfs-site.xml
如果不放心,可以scp hadoop文件重新分法到两个节点。
- 确保所有节点的hosts文件一致
在所有节点上检查并编辑/etc/hosts文件,确保如下配置:
127.0.0.1 localhost
172.16.167.131 ubuntu1
172.16.167.132 ubuntu2
172.16.167.133 ubuntu3
而我的ubuntu原先的hosts配置如下:
域名映射127.0.1.1 ubuntu1确实存在问题,随即删除该行,同理ubuntu2和ubuntu3的hosts文件也有这个错误的配置。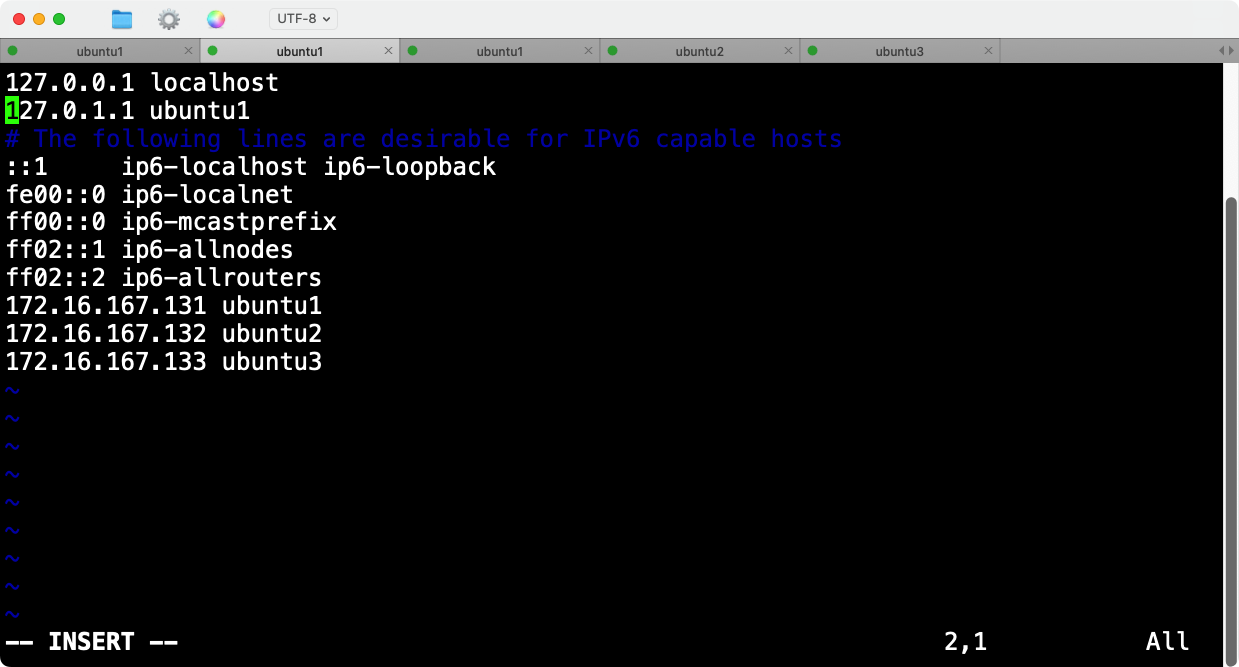
重新格式化namenode
hadoop namenode -format
再次格式化后ubuntu1的ip已经正确。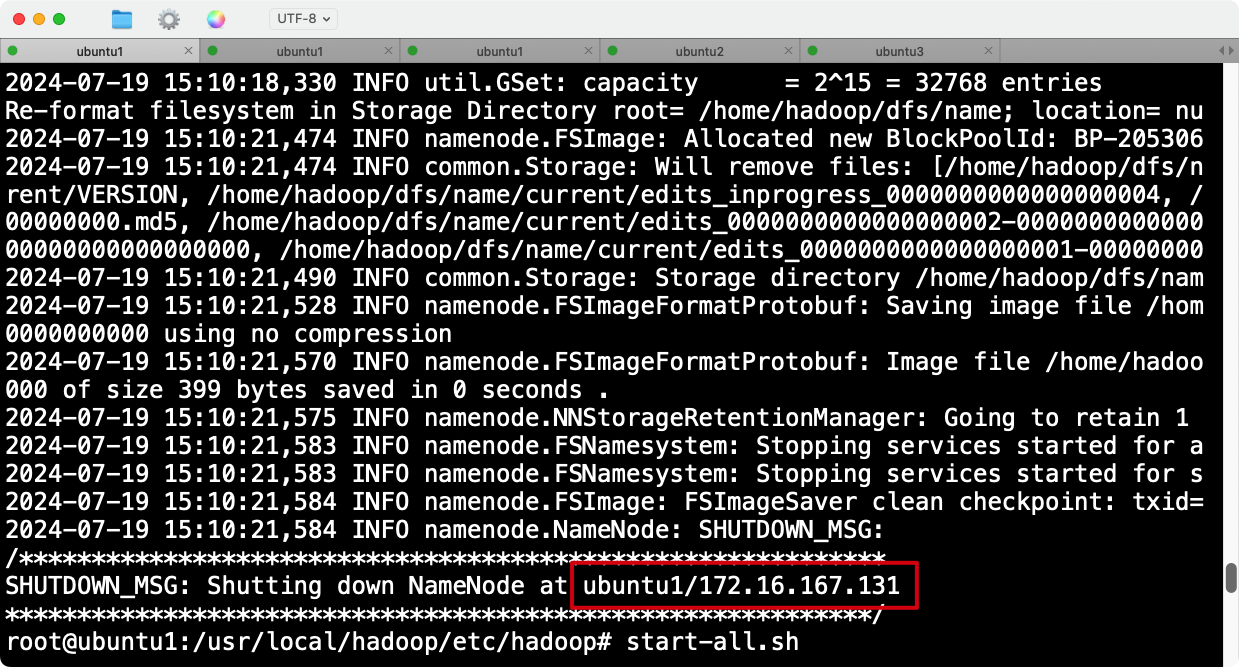
启动Hadoop集群
在ubuntu1上执行:
start-all.sh
验证修复
- 验证所有节点的状态
xcallx.sh jps
确认所有节点都启动了相关的Hadoop服务。
- 检查HDFS状态
hdfs dfsadmin -report
hdfs dfs -ls /
确认DataNode已经注册并且HDFS工作正常。进入web界面,三台datanode也正常挂载并在线。
5.2 mapreduce报错
问题描述
在用hadoop自带案例测试worldcount时,报如下错误Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster,根据错误回显提示,是因为少了配置文件内容。
state FAILED due to: Application application_1721401895971_0001 failed 2 times due to AM Container for appattempt_1721401895971_0001_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2024-07-19 15:32:36.368]Exception from container-launch.
Container id: container_1721401895971_0001_02_000001
Exit code: 1
[2024-07-19 15:32:36.386]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your <HADOOP_HOME>/etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
[2024-07-19 15:32:36.387]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your <HADOOP_HOME>/etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
For more detailed output, check the application tracking page: http://ubuntu1:8088/cluster/app/application_1721401895971_0001 Then click on links to logs of each attempt.
. Failing the application.
2024-07-19 15:32:36,815 INFO mapreduce.Job: Counters: 0
Job job_1721401895971_0001 failed!
root@ubuntu1:/home/guoyachao#
根据错误日志,Hadoop在运行示例程序时无法找到或加载 org.apache.hadoop.mapreduce.v2.app.MRAppMaster 类。该问题通常与环境变量配置不正确有关。以下是解决该问题的步骤:
步骤一:编辑 mapred-site.xml
在 mapred-site.xml 文件<configuration>中添加以下配置,以确保 Hadoop 能正确找到 HADOOP_MAPRED_HOME 路径。已经在前文配置更新,按照前文配置,是不会有此报错的。
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
步骤二:验证环境变量
确保 HADOOP_HOME 和其他相关环境变量已经正确设置。
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME
export PATH=$HADOOP_HOME/bin:$PATH
将这些变量添加到 /etc/profile 或 ~/.bashrc 文件中,然后执行 source /etc/profile 或 source ~/.bashrc 以加载配置。
该配置也在前文中已经更新,要确保三台节点均更新成功。
步骤三:重启Hadoop和YARN服务
在所有节点上重启Hadoop和YARN服务。
stop-all.sh
start-all.sh
步骤四:再次运行示例程序
再次运行 pi 或 wordcount 示例程序。
# 运行Pi计算示例
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar pi 10 100
# 运行WordCount示例
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/root/input /user/root/output
此时,mapreduce已经可以正常运行计算程序。
至此,Hadoop的安装完成,包括hdfs文件存储系统,mapreduce计算框架,yarn资源管理系统均能正常、稳定使用。
















 2969
2969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











