







 本文介绍了决策树算法的核心,包括信息熵的概念和计算,详细解释了ID3算法的步骤,并探讨了过拟合的处理方法及决策树的优缺点。通过一个实例展示了如何构建决策树,并提到了其他如C4.5、CART等决策树算法。
本文介绍了决策树算法的核心,包括信息熵的概念和计算,详细解释了ID3算法的步骤,并探讨了过拟合的处理方法及决策树的优缺点。通过一个实例展示了如何构建决策树,并提到了其他如C4.5、CART等决策树算法。
机器学习算法及代码实现–决策树
1、决策树
决策树算法的核心在于决策树的构建,每次选择让整体数据香农熵(描述数据的混乱程度)减小最多的特征,使用其特征值对数据进行划分,每次消耗一个特征,不断迭代分类,直到所有特征消耗完(选择剩下数据中出现次数最多的类别作为这堆数据的类别),或剩下的数据全为同一类别,不必继续划分,至此决策树构建完成,之后我们依照这颗决策树对新进数据进行分类。
2、信息熵
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==>信息量的度量就等于不确定性的多少
例子:猜世界杯冠军,假如一无所知,猜多少次?实际中每个队夺冠的几率不是相等的,如果我们对其有足够了解,是否猜中的概率会增大?
信息熵用比特(bit)来衡量信息的多少,变量的不确定性越大,熵也就越大。
公式:

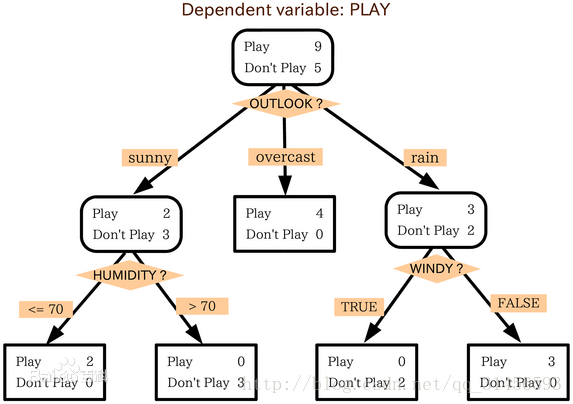
3、决策树算法(ID3)
我们以一个例子来讲述决策树的算法(判断该用户是否买电脑)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









