







决策树
文章目录
1.决策树模型
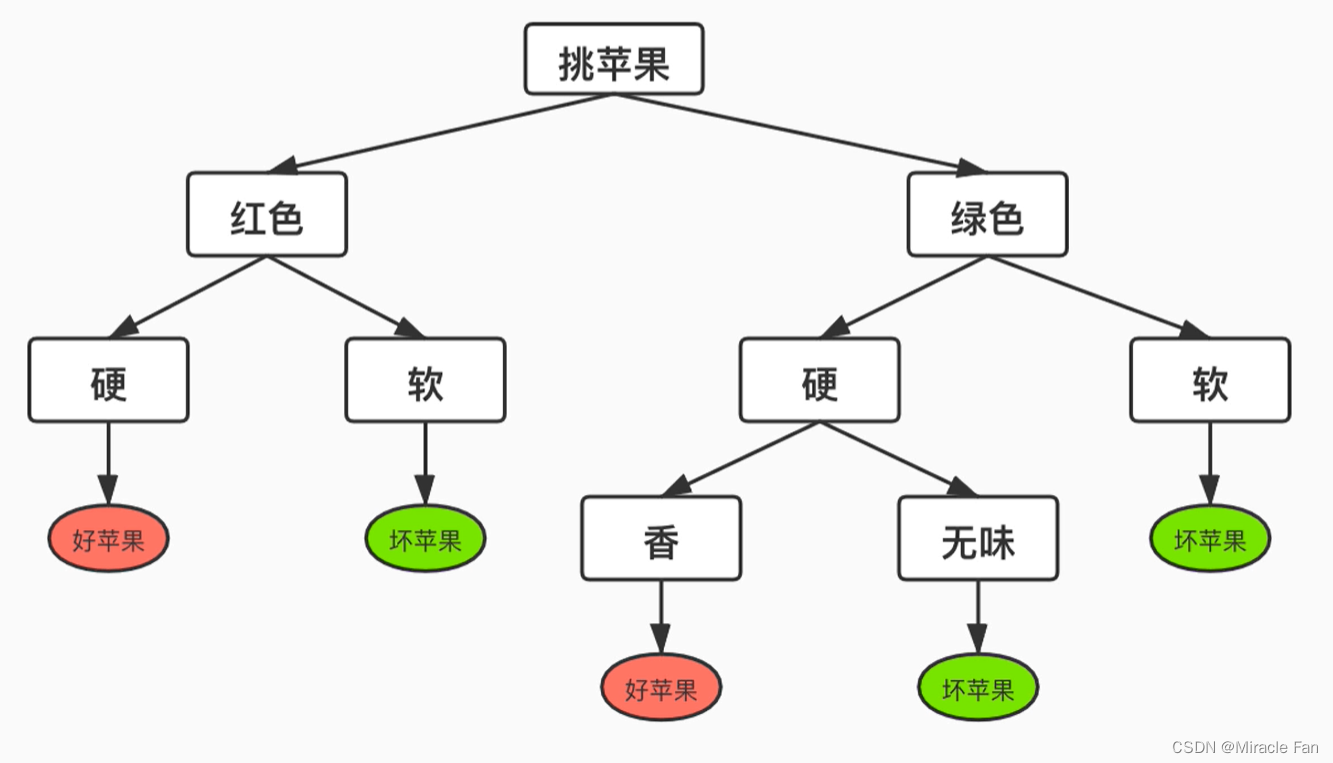
在决策树模型中,一般存在两种结点,一种及为下图矩形所表示的样本特征,一种即为椭圆表示的样本标签。如果用决策树进行分类,则是将一组给定数据从根节点开始,对样本的某一特征进行测试,判断其隶属于哪一个子节点,然后循环往复,直至没有子节点出现,也就是到达叶节点,最终实现分类效果。
2.决策树相关名词
2.1信息熵:
- 定义:用于衡量信息的不确定性,也就是类似于样本属于哪一类的概率
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量.设X是一个取有限个值的离散随机变量,其概率分布为
P
(
X
=
x
i
)
=
p
i
,
i
=
1
,
2
,
⋯
,
n
P\left(X=x_{i}\right)=p_{i},\quad i=1,2,\cdots,n
P(X=xi)=pi,i=1,2,⋯,n
则随机变量X的熵定义为:
H
(
X
)
=
−
∑
i
=
1
n
p
i
log
2
p
i
H(X)=-\sum^{n}_{i=1}p_{i}\log_2 p_{i}
H(X)=−i=1∑npilog2pi
当信息熵越大时,也就代表这随机变量的不确定性越大:
0
≤
H
(
P
)
≤
log
2
n
0\leq H(P)\leq \log_2^n
0≤H(P)≤log2n
也就是表明,当随机变量均匀分布的时候,熵最大。对于log所取得底数,一般情况下如果不做说明,默认取2
2.2信息增益
在我们了解了信息熵之后,我们可以对一棵决策树作出如下假设:
- 在根节点处,其 H ( P ) H(P) H(P)为最大,也可令其为1,也就是不确定性为100%
- 在样本遍历到叶节点时,假设 H ( P ) H(P) H(P)为0,表示非常稳定,也就是确定了样本属于哪一个类别
- 为了避免造成一头大一头小的决策树,可能会导致部分样本训练快,部分样本训练慢的情况,而从总体来看像这样构建的决策树模型很低效,再进行构建时一般尽可能让一半进入A分支,一半进入B分支。
- 为了快速对样本进行判别,我们希望每个节点下降得快一些,而这个下降速度在决策树中采用信息增益进行这个下降速度得表示。
下面就是信息增益的定义:
定义:在已知X特征A的信息而使得分类结果Y的信息熵下降的程度。
特征A对训练数据集D的信息增益
g
(
D
,
A
)
g(D,A)
g(D,A),定义为集合D的经验熵
H
(
D
)
H(D)
H(D)与特征A给定条件下D的经验条件樀
H
(
D
∣
A
)
H(D\mid A)
H(D∣A)之差,即
g
(
D
,
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
g(D,A)=H(D)-H(D\mid A)
g(D,A)=H(D)−H(D∣A)
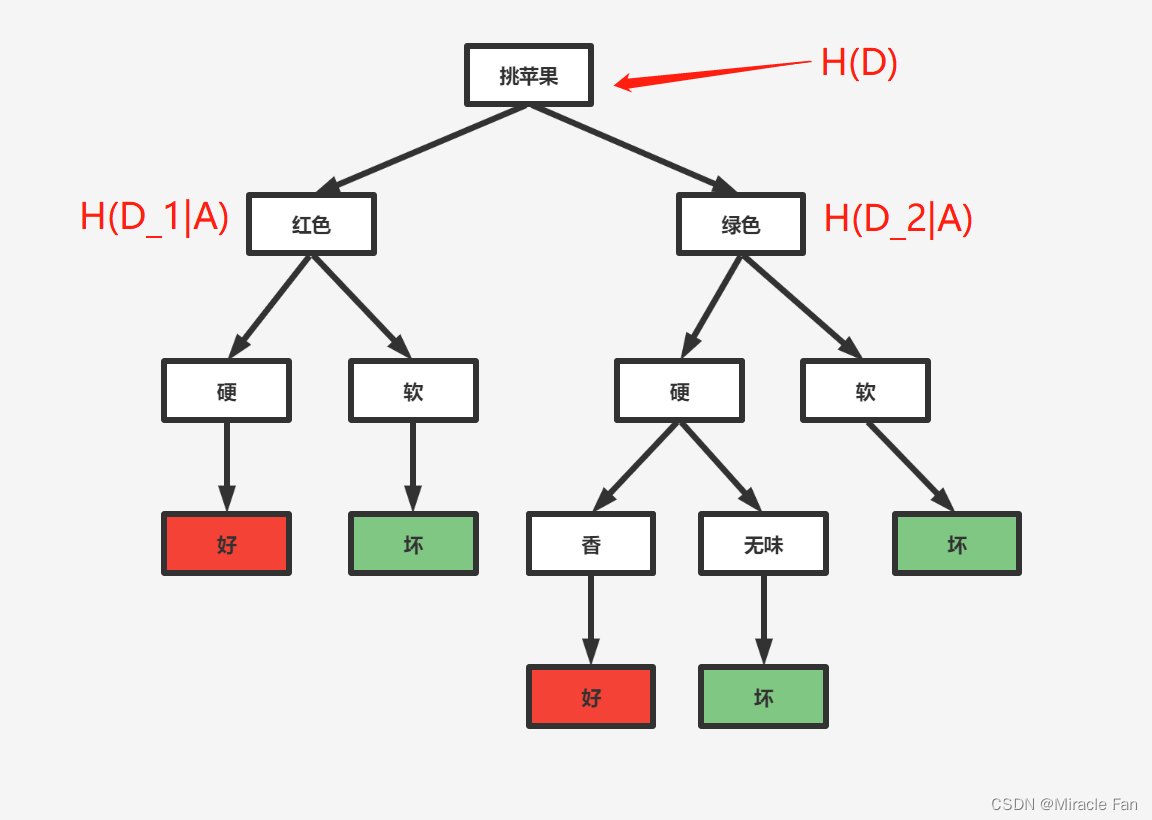
对于二分类问题:
g
(
D
,
A
)
=
H
(
D
)
−
[
H
(
D
1
∣
A
)
+
H
(
D
2
∣
A
)
g(D,A)=H(D)-[H(D_1\mid A)+H(D_2\mid A)
g(D,A)=H(D)−[H(D1∣A)+H(D2∣A)
2.3信息增益计算方法:
输入:训练数据集D和特征A
输出:特征A对训练数据集D的信息增益 g ( D , A ) g(D,A) g(D,A).
-
计算数据集D的经验熵H(D)
C k C_k Ck为样本中某类别数目,也就是标签有多少类别。
H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ log 2 ∣ C k ∣ ∣ D ∣ H(D)=-\sum_{k=1}^{K}\frac{\left|C_{k}\right|}{|D|}\log_{2}\frac{\left|C_{k}\right|}{|D|} H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣
def calc_H_D(trainLabelArr):
"""
:param trainLabelArr:当前数据集的标签集
:return: 经验熵
"""
H_D = 0
#为了避免出现log0的情况,比如某一个类别在当前子集没有出现,所以需要统计当前子集中类别数目
trainLabelSet = set([label for label in trainLabelArr])
for i in trainLabelSet:
#求出每一个类别占整体的概率值
p = trainLabelArr[trainLabelArr == i].size / trainLabelArr.size
# 对经验熵的每一项累加求和
H_D += p * np.log2(p)
H_D = -1 * H_D
return H_D
-
计算特征A对数据集D的经验条件熵 H ( D ∣ A ) H(D\mid A) H(D∣A)
D i D_i Di代表在经过特征A筛选之后,分出来的第i类包含的数据集
H ( D ∣ A ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ H ( D i ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ ∑ k = 1 K ∣ D i k ∣ ∣ D i ∣ log 2 ∣ D i k ∣ ∣ D i ∣ H(D\mid A)=\sum_{i=1}^{n}\frac{\left|D_{i}\right|}{|D|}H\left(D_{i}\right)=-\sum_{i=1}^{n}\frac{\left|D_{i}\right|}{|D|}\sum_{k=1}^{K}\frac{\left|D_{ik}\right|}{\left|D_{i}\right|}\log_{2}\frac{\left|D_{ik}\right|}{\left|D_{i}\right|} H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣
-
∣
D
i
∣
∣
D
∣
\frac{\left|D_{i}\right|}{|D|}
∣D∣∣Di∣:
trainDataArr_DevFeature[trainDataArr_DevFeature == i].size / trainDataArr_DevFeature.size
def calcH_D_A(trainDataArr_DevFeature, trainLabelArr):
'''
计算经验条件熵
:param trainDataArr_DevFeature:切割后只有feature那列数据的数组
:param trainLabelArr: 标签集数组
:return: 经验条件熵
'''
H_D_A = 0
# 在featue那列放入集合中,是为了根据集合中的数目知道该feature目前可取值数目是多少
trainDataSet = set([label for label in trainDataArr_DevFeature])
# 对于每一个特征取值遍历计算条件经验熵的每一项
for i in trainDataSet:
H_D_A += trainDataArr_DevFeature[trainDataArr_DevFeature == i].size / trainDataArr_DevFeature.size \
* calc_H_D(trainLabelArr[trainDataArr_DevFeature == i])
return H_D_A
- 计算信息增益:
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D\mid A) g(D,A)=H(D)−H(D∣A)
np.array(trainDataArr[:, feature].flat):再转换成一条竖着的矩阵,大小为
60000
×
1
60000\times1
60000×1的形式,便于矩阵运算。
trainDataArr_DevideByFeature = np.array(trainDataArr[:, feature].flat)
G_D_A = H_D - calcH_D_A(trainDataArr_DevideByFeature, trainLabelArr)
2.4信息增益比:
由来:信息增益其存在偏向取值较多的特征类别,比如说在某次分类中,每个样本都有一个自己的id号,为了使得信息熵下降最快,决策树会认为按这个id号作为分类最快,但这也因此引发了模型的错误。
定义:特征A对训练集D的信息增益比(information gain ratio),
g
R
(
D
,
A
)
g_R(D,A)
gR(D,A)定义为其信息增益
g
(
D
,
A
)
g(D,A)
g(D,A)与训练数据D关于特征A的经验熵
H
(
D
)
H(D)
H(D)之比
g
R
(
D
,
A
)
=
g
(
D
,
A
)
H
A
(
D
)
g_{R}(D, A)=\frac{g(D, A)}{H_A(D)}
gR(D,A)=HA(D)g(D,A)
- H A ( D ) : H_A(D): HA(D):类别换成再通过特征A筛选后的数据集,再重新进行熵的计算
trainDataArr_DevideByFeature = np.array(trainDataArr[:, feature].flat)
G_D_A = H_D - calcH_D_A(trainDataArr_DevideByFeature, trainLabelArr)
G_R_D_A=G_D_A/calc_H_D(trainDataArr_DevideByFeature)
3.决策树生成算法
ID3算法:
-
输入:训练数据集D,特征集A,阈值 ε \varepsilon ε;
-
输出:决策树T.
-
计算步骤:
- 若D中所有实例属于同一类 C k C_{k} Ck,则T为单结点树,并将类 C k C_{k} Ck作为该结点的类标记,返回T;
- 若A= ∅ \varnothing ∅,则T为单结点树,并将D中实例数最大的类 C k C_{k} Ck作为该结点的类标记,返回T;
- 否则,按算法5.1计算A中各特征对D的信息增益,选择信息增益最大的特征 A g A_{g} Ag;
- 如果 A g A_{g} Ag的信息增益小于阈值 ε \varepsilon ε,则置T为单结点树,并将D中实例数最大的类 C k C_{k} Ck作为该结点的类标记,返回T;
- 否则,对 A g A_{g} Ag的每一可能值 a i a_{i} ai,依 A g = a i A_{g}=a_{i} Ag=ai将D分割为若干非空子集 D i D_{i} Di,将 D i D_{i} Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
- 对第 i i i个子结点,以 D i D_{i} Di为训练集,以 A − { A g } A-\left\{A_{g}\right\} A−{Ag}为特征集,递归地调用步(1)〜步(5),得到子树 T i T_{i} Ti,返回 T i T_{i} Ti.
阈值 ε \varepsilon ε应该是表示就是当前最优特征对决策树的不确定性下降多少给的一个阈值,防止模型复杂
C4.5算法:
- 输入:训练数据集D,特征集A,阈值 ε \varepsilon ε;
- 输出:决策树T.
- 计算步骤:
- 若D中所有实例属于同一类 C k C_{k} Ck,则T为单结点树,并将类 C k C_{k} Ck作为该结点的类标记,返回T;
- 若A= ∅ \varnothing ∅,则T为单结点树,并将D中实例数最大的类 C k C_{k} Ck作为该结点的类标记,返回T;
- 否则,按算法5.1计算A中各特征对D的信息增益比,选择信息增益最大的特征 A g A_{g} Ag;
- 如果 A g A_{g} Ag的信息增益小于阈值 ε \varepsilon ε,则置T为单结点树,并将D中实例数最大的类 C k C_{k} Ck作为该结点的类标记,返回T;
- 否则,对 A g A_{g} Ag的每一可能值 a i a_{i} ai,依 A g = a i A_{g}=a_{i} Ag=ai将D分割为若干非空子集 D i D_{i} Di,将 D i D_{i} Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
- 对第 i i i个子结点,以 D i D_{i} Di为训练集,以 A − { A g } A-\left\{A_{g}\right\} A−{Ag}为特征集,递归地调用步(1)〜步(5),得到子树 T i T_{i} Ti,返回 T i T_{i} Ti.
4.树的剪枝
引入剪枝:
- 复杂的模型结构往往可能会造成过拟合现象的发生,比如给定一个二次数据样本,当样本用三次函数进行拟合或者更加高次进行拟合可能会导致样本在训练集上表现在很好,但是其泛化能力差。
- 引入剪枝的目的:就是为了在决策树构建结束后,去裁剪掉部分枝桠,以降低模型的复杂度
决策树的前枝往往通过极小化决策树整体的损失函数(loss function)或代价函数(cost function)来实现.设树T的叶结点个数为|T|,t是树T的叶结点,该叶结点有
N
t
N_{t}
Nt个样本点,其中k类的样本点有
N
t
k
N_{tk}
Ntk个,
k
=
1
,
2
,
⋯
,
K
,
H
t
(
T
)
k=1,2,\cdots,K,H_{t}(T)
k=1,2,⋯,K,Ht(T)为叶结点t上的经验熵,
α
⩾
0
\alpha\geqslant0
α⩾0为参数,则决策树学习的损失函数可以定义为:
C
α
(
T
)
=
∑
t
=
1
∣
T
∣
N
t
H
t
(
T
)
N
+
α
∣
T
∣
C_{\alpha}(T)=\sum_{t=1}^{|T|}\frac{N_{t}H_{t}(T)}{N}+\alpha|T|
Cα(T)=t=1∑∣T∣NNtHt(T)+α∣T∣
- N t N \frac{N_t}{N} NNt代表这个叶节点占总体样本中的概率,去赋予在叶节点t上的熵
- α \alpha α代表正则项,也就是构造了一个结构风险损失函数,用来给模型复杂度加以惩罚。
其中经验熵为
H
t
(
T
)
=
−
∑
k
N
t
k
N
t
log
N
t
k
N
t
H_{t}(T)=-\sum_{k}\frac{N_{tk}}{N_{t}}\log\frac{N_{tk}}{N_{t}}
Ht(T)=−k∑NtNtklogNtNtk
在损失函数中
C
(
T
)
=
∑
t
=
1
∣
T
∣
N
t
H
t
(
T
)
=
−
∑
t
=
1
∣
T
∣
∑
k
=
1
K
N
t
k
log
N
t
k
N
t
C(T)=\sum_{t=1}^{|T|}N_{t}H_{t}(T)=-\sum_{t=1}^{|T|}\sum_{k=1}^{K}N_{tk}\log\frac{N_{tk}}{N_{t}}
C(T)=t=1∑∣T∣NtHt(T)=−t=1∑∣T∣k=1∑KNtklogNtNtk
这时有
C α ( T ) = C ( T ) + α ∣ T ∣ C_{\alpha}(T)=C(T)+\alpha|T| Cα(T)=C(T)+α∣T∣
剪枝算法:
-
输入: 生成算法产生的整个树 T , 参数 α \alpha α ;
-
输出: 修剪后的子树 T α T_{\alpha} Tα
计算步骤:
-
计算每个结点的经验熵.
-
递归地从树的叶结点向上回缩.
设一组叶结点回缩到其父结点之前与之后的整体树分别为 T B T_{B} TB与 T A T_{A} TA,其对应的损失函数值分别是 C α ( T B ) C_{\alpha}\left(T_{B}\right) Cα(TB)与 C α ( T A ) C_{\alpha}\left(T_{A}\right) Cα(TA),如果
C α ( T A ) ≤ C α ( T B ) C_{\alpha}\left(T_{A}\right)\leq C_{\alpha}\left(T_{B}\right) Cα(TA)≤Cα(TB)
则进行剪枝,即将父结点变为新的叶结点也就是,当决策树对某个叶节点在未进行剪枝前的损失函数大于在进行剪枝操作后的决策树,也就是返回到其父节点去计算损失函数,就进行剪枝操作
- 返回(2),直至不能继续为止,得到损失函数最小的子树 T α T_{\alpha} Tα.
代码参考
1.计算最好特征:
def calcBestFeature(trainDataList, trainLabelList,algorithm="C_45"):
'''
计算信息增益最大的特征
:param trainDataList: 当前数据集
:param trainLabelList: 当前标签集
:return: 信息增益最大的特征及最大信息增益值
'''
# 将数据集和标签集转换为数组形式
trainDataArr = np.array(trainDataList)
trainLabelArr = np.array(trainLabelList)
# 获取当前特征数目,也就是数据集的横轴大小
featureNum = trainDataArr.shape[1]
# 初始化最大信息增益
maxG_D_A = -1
maxG_R_D_A = -1
# 初始化最大信息增益的特征
maxFeature = -1
# “5.2.2 信息增益”中“算法5.1(信息增益的算法)”第一步:
# 1.计算数据集D的经验熵H(D)
H_D = calc_H_D(trainLabelArr)
# 对每一个特征进行遍历计算
if algorithm=="C_45":
for feature in range(featureNum):
trainDataArr_DevideByFeature = np.array(trainDataArr[:, feature].flat)
G_D_A = H_D - calcH_D_A(trainDataArr_DevideByFeature, trainLabelArr)
G_R_D_A = G_D_A / calc_H_D(trainDataArr_DevideByFeature)
# 不断更新最大的信息增益以及对应的feature
if G_R_D_A > maxG_R_D_A:
maxG_R_D_A = G_R_D_A
maxFeature = feature
return maxFeature, maxG_R_D_A
elif algorithm=="ID3":
for feature in range(featureNum):
trainDataArr_DevideByFeature = np.array(trainDataArr[:, feature].flat)
G_D_A = H_D - calcH_D_A(trainDataArr_DevideByFeature, trainLabelArr)
# 不断更新最大的信息增益以及对应的feature
if G_D_A > maxG_D_A:
maxG_D_A = G_D_A
maxFeature = feature
return maxFeature, maxG_D_A
2.获取子结点数据集
def getSubDataArr(trainDataArr, trainLabelArr, A, a):
'''
更新数据集和标签集,获取子集数据集
:param trainDataArr:要更新的数据集
:param trainLabelArr: 要更新的标签集
:param A: 要去除的特征索引
:param a: 当data[A]== a时,说明该行样本时要保留的
:return: 新的数据集和标签集
'''
# 返回的数据集
retDataArr = []
# 返回的标签集
retLabelArr = []
# 对当前数据的每一个样本进行遍历
for i in range(len(trainDataArr)):
# 如果当前样本的特征为指定特征值a
if trainDataArr[i][A] == a:
# 那么将该样本的第A个特征切割掉,放入返回的数据集中
retDataArr.append(trainDataArr[i][0:A] + trainDataArr[i][A + 1:])
# 将该样本的标签放入返回标签集中
retLabelArr.append(trainLabelArr[i])
# 返回新的数据集和标签集
return retDataArr, retLabelArr
3.找到当前标签集中占数目最大的标签
也就是对应上述ID3算法和C4.5算法,置T为单结点树,并将D中实例数最大的类 C k C_{k} Ck作为该结点的类标记,该函数则是获取子数据集中占比最大数目的标签
def majorClass(labelArr):
'''
找到当前标签集中占数目最大的标签
:param labelArr: 标签集
:return: 最大的标签
'''
# 建立字典,用于不同类别的标签技术
classDict = {}
# 遍历所有标签
for i in range(len(labelArr)):
# 当第一次遇到A标签时,字典内还没有A标签,这时候直接幅值加1是错误的,
# 所以需要判断字典中是否有该键,没有则创建,有就直接自增
if labelArr[i] in classDict.keys():
# 若在字典中存在该标签,则直接加1
classDict[labelArr[i]] += 1
else:
# 若无该标签,设初值为1,表示出现了1次了
classDict[labelArr[i]] = 1
# 对字典依据值进行降序排序
classSort = sorted(classDict.items(), key=lambda x: x[1], reverse=True)
# 返回最大一项的标签,即占数目最多的标签
return classSort[0][0]
4.再特征筛选之后获取子节点数据集
def getSubDataArr(trainDataArr, trainLabelArr, A, a):
'''
更新数据集和标签集,获取子集数据集
:param trainDataArr:要更新的数据集
:param trainLabelArr: 要更新的标签集
:param A: 要去除的特征索引
:param a: 当data[A]== a时,说明该行样本时要保留的
:return: 新的数据集和标签集
'''
# 返回的数据集
retDataArr = []
# 返回的标签集
retLabelArr = []
# 对当前数据的每一个样本进行遍历
for i in range(len(trainDataArr)):
# 如果当前样本的特征为指定特征值a
if trainDataArr[i][A] == a:
# 那么将该样本的第A个特征切割掉,放入返回的数据集中
retDataArr.append(trainDataArr[i][0:A] + trainDataArr[i][A + 1:])
# 将该样本的标签放入返回标签集中
retLabelArr.append(trainLabelArr[i])
# 返回新的数据集和标签集
return retDataArr, retLabelArr
Dod-o/Statistical-Learning-Method_Code: 手写实现李航《统计学习方法》书中全部算法 (github.com)
















 1337
1337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











