







-
Hive 简介
以下的请深刻理解,如果理解不清楚请别看下一部分!
1、Hive可以将结构化数据文件映射为一张数据库的表(这一句必须要理解),是一个数据仓库工具()
结构化的数据 -------> 数据库的表
就是将 txt文件中的类容当成数据库的一张表进行操作
数据仓库工具------>这个需要实际的项目经验接触就可以理解了当前可以不用理解。
相信前面的你已经理解了,对Hive就使HQL语句操作这样的结构化表!
2、将HQL语句自动转换为MapReduce任务(这知道Hive的都知道,你要不记要不要理解自己看着办!)
01.因为编写MapReduce过程太过复杂要写map函数还要写Reduce函数,最后还得写一个关联的函数好麻烦!现在hive可以使用HQL(类似sql的语句)语句到达写MapReduce的一样的效果,因此我选择写SQL去操作。如果你觉得写MR比写sql简单,那么再见,hive不适合你学习!虽然你写的是sql但是底层Hive会自动将sql语句转换为MR任务,懂了吧!我估计你已经懂了~~不懂就再见!这篇博客不适合你~
3、Hive依赖于HDFS进行数据存储(Hive中所有的表的数据都是存储在HDFS上,元数据除外),依赖于MapReduce进行查询操作
Hive离不开HDFS,因为前面的那些数据全都要存在HDFS上,关于MapReduce进行查询操作就是sql语句转换为MR任务拿到结果。
4、以上你不懂的话,只能说明你的数据库和结构化数据以及MapReduce函数有问题强烈建议前面3点懂了再看后面的。
-
Hive架构
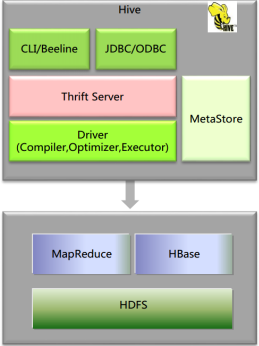
MetaStore:元数据(hive中的表的存在hdfs上的存储位置、这些表中有那些列、Partition(分区)、BUCKETS(分桶)),元数据的存储是存储在关系型数据库中的。
Driver:管理HiveQL执行的生命周期,贯穿Hive任务整个执行期间(包括:Compiler、Optimizer、Executor)
Compiler:将HQL转换为Map/Reduce任务(编译器)
Optimizer:优化HiveQL生成的执行计划和MapReduce任务进行优化(优化器)
Executor:执行Map/Reduce任务(执行器)
ThriftServer:提供thrift接口,将Hive作为一个服务端(服务器)其它访问(通过JDBC/ODBC访问)的机器作为客服端
Clients:Hive客户端,为用户访问提供接口。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-
Hive表的分类
临时表(TEMPORARY):可以看做特殊的管理表,作用域只在当前进程内有效
管理表、内部表、托管表(MANAGED):数据由hive管理,会将数据动到hive的数据仓库目录
外部表(EXTERNAL):hive会到仓库目录以外的位置访问数据
内部表与外部表的区别:
1、在删内部表时,会将元数据和数据文件(HDFS上的文件)一起删除(在删除表后再重新创建一张一模一样的表,表的数据不存在。)
2、在删除外部表时,只会删除元数据,数据文件不会删除(在删除表后再重新创建一张一模一样的表,表的数据还是存在。)
一般情况下
如果创建的表中的数据(存在HDFS的数据)只是hive使用,就创建内部表,
如果创建的表的数据(存在HDFS的数据)还有其它程序使用,就创建外部表。
-
Hive分区、分桶
1、分区:简单的讲,就是将一张表的中的数据按照指定字段的条件进行分类后放入到不同的文件下,目的是为了查询减少查询的范围,提供查询效率。
分区下面还能有分区,以子文件的形式存在。
分区的字段一般是常用的条件字段。
2、分桶:hive分桶就是将分桶字段的值取余桶的数量,然后放入到对应的桶中,形成一个文件。
3、分区下面还进行分桶操作,分区字段和分桶字段不可以相同
-
Hive加载数据、转换流程
1、当用户使用加载的方式将数据加载到hive表中,数据如果在hdfs中,那么将会将hdfs上的数据剪切到hive表的目录下;
如果数据是在本地,会将数据从本地复制到hdfs中hive表的目录下。
2、分桶表的加载:先创一张临时表(字段和分桶表的字段一样)、将数据加载到临时表、将临时表的数据加载到分桶表。
3、转换流程:解析器-->编译器-->优化器-->执行器
解析器:HQL词法进行分析(关键字是否错误),语法分析(表是否存在)
编译器:HQL转换为MR任务
优化器:对HQL和MR任务进行优化
执行器:执行MR任务(包括安排执行的MR任务的顺序等)
-
数据倾斜问题以及优化
1、在关联表的时候采用从左到右表的大小依次增加的方式关联
2、经常查询的字段为该字段添加分区
3、hive.auto.convert.join为true ---将没有超过指定大小的表放入到内存中进行计算(map--join,老版本 )
(set hive.mapjoin.smalltable.filesize ---指定表的大小)
4、hive.groupby.skewindata=true --使map任务和reduce任务分配均匀
5、关于为null值的倾斜:01可以将不用为null的字段进行关联;02可以将为null的字段给一个默认值
-
关于对hiveserver2和beeline的理解
1、hiveserver2:hive的远程服务,开启后才客户端才能够进行访问
2、beeline工具:只是为看使用hive,自己理解相当于一个远程操作hive(只有在开启hiveserver2后才可以进行beeline的操作)
-
HIEV函数
1、Hive函数分类:UDF、UDAF、UDTF
UDF:一进一出(查询出理后的数据条数与数据库的数据相等)如:trim
UDAF:多进一出(查询处理后的数据条数比数据库的数据条数少)聚合函数如:sum,count
UDTF:(查询处理后的数据条数比数据库的数据条数多)如:explode
自定义函数:自己写一个函数导入到hive中,使用方式和hive内置函数一样
-
部分补充:
OLTP:联机事务处理,实时(业务处理)
OLAP:联机分析处理,离线(报表、数据分析处理)
关于hive的数据类型、DDL、DML、DQL不做介绍希望对大家有所帮助。















 2156
2156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









