







声明:该文章纯属个人对文章的粗略理解,不代表作者观点,具体细节需请各位下方链接读原论文,如果有不同意的地方,还希望大家指出。
论文简单理解
这篇文章主要讲的是如何通过图卷积来实现目标跟踪。首先他显示指出了用SiamNet做目标跟踪的通病,就是不考虑时空连贯信息,一旦目标一定时间从视线中消失,或者说是出现明显的光照条件变化,那基本上跟踪器也就失效了。所以作者就通过图结构把 前T 帧的视频时空信息都给连接在了一块,其中每一帧的选中区域作者又将其分成M个部分,然后M个部分形成一个团,每个团代表空间信息,而把不同的帧的团连在一起之后就代表了时空信息。接下来,通过图卷积把图每个节点的计算结果都输出来之后,再经过一次针对上下文的图卷积,输出结果做一次softmax之后就成了我们要的Template的特征了,接着,我们直接将这个特征和search Image通过shared ConvNet 生成的结果进行互相关计算,就和SiamFC一样,结果就出来了。
论文要点: 图卷积 时空域关联 孪生网络结构跟踪
作者实验效果
跟踪效果图片

在跟踪丢失这块,我们主要对比他和SiamFC以及ECO,我们可以看出来,在光照变化以及中间目标消失的前提下,他具有更好的跟踪效果。相对同样考虑到位置变化的TRACA,他的边缘识别准确率更高。
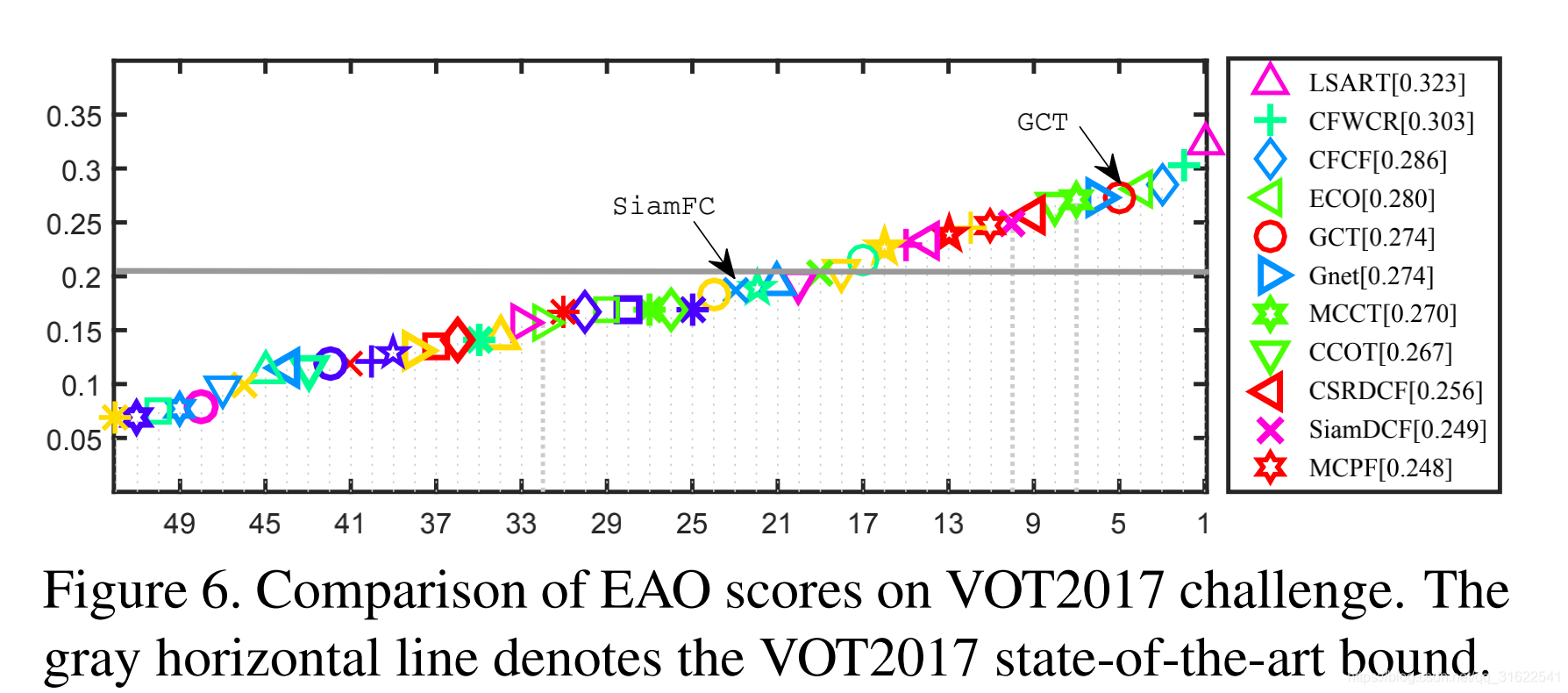
EAO分数在作者以VOT2017为基准的实验中也相对于大部分方法要高。
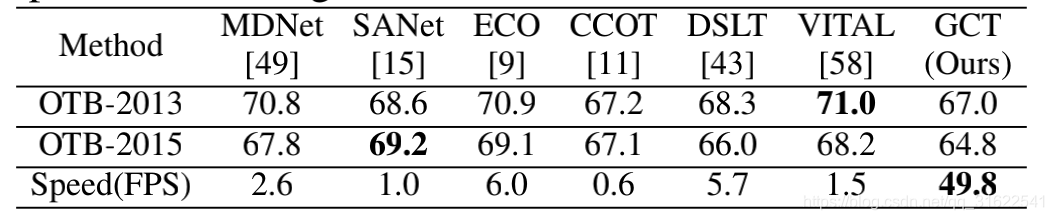
最后就是速度,基本上也达到了实时要求。
论文摘要(原文)
Tracking by siamese networks has achieved favorable performance in recent years. However, most of existing siamese methods do not take full advantage of spatialtemporal target appearance modeling under different contextual situations. In fact, the spatial-temporal information can provide diverse features to enhance the target representation, and the context information is important for online adaption of target localization. To comprehensively leverage the spatial-temporal structure of historicaltarget exemplars and get benefit from the context information,in this work, we present a novel Graph Convolutional Tracking (GCT) method for high-performance visual tracking. Specifically, the GCT jointly incorporates two types of Graph Convolutional Networks (GCNs) into a siamese framework for target appearance modeling. Here, we adopt a spatial-temporal GCN to model the structured representation of historical target exemplars. Furthermore, a context GCN is designed to utilize the context of the current frame to learn adaptive features for target localization. Extensive results on 4 challenging benchmarks show that our GCT method performs favorably against state-of-the-art trackers while running around 50 frames per second.
网络结构
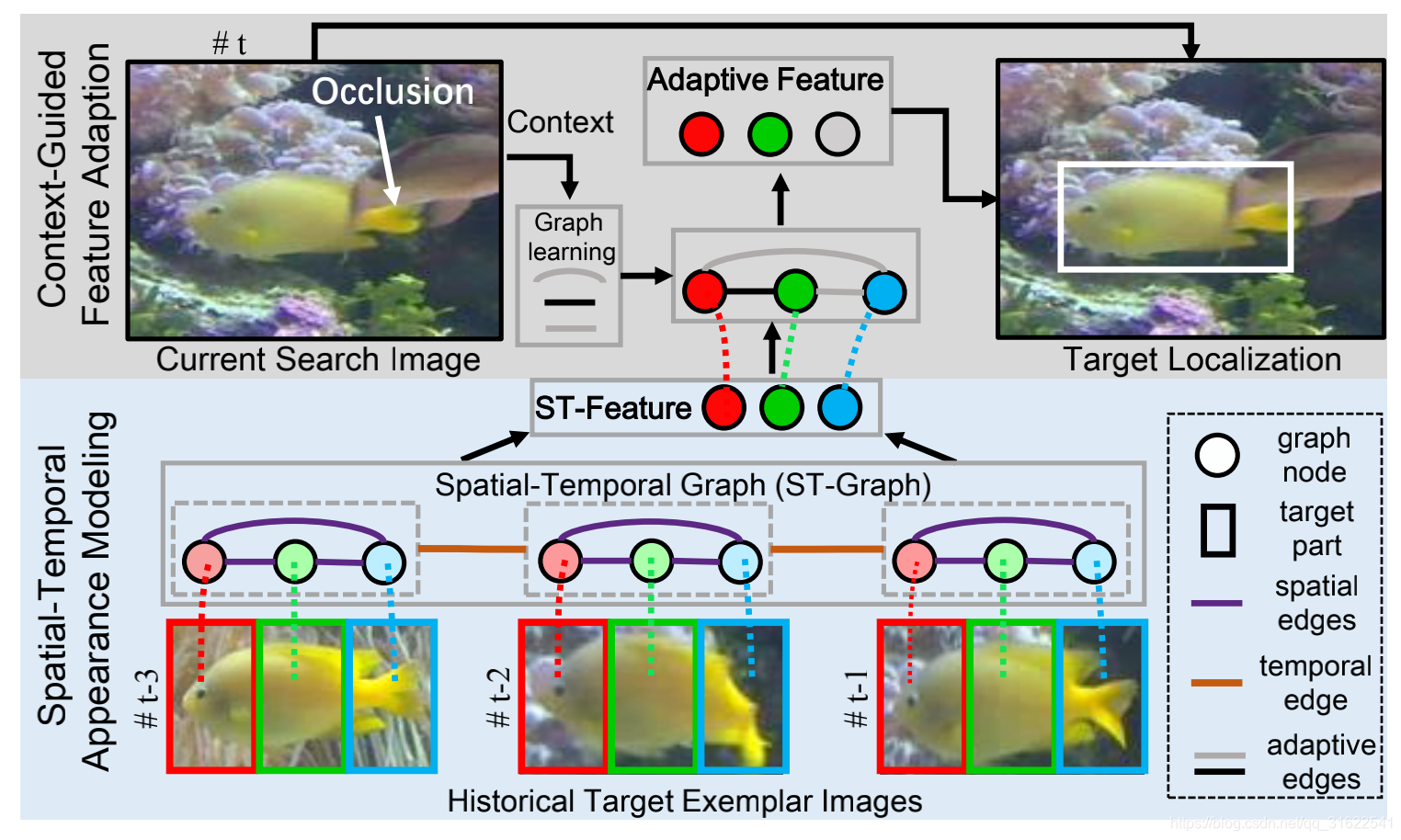
这个是之前讲的网络结构的一部分,主要是从下到上描述图卷积的计算过程以及作者是怎么按时间和区域分离出图中每一个节点的。

这个是作者完整的网络结构,我们可以看到,走的孪生网络的思路,不过在提取模版图特征的时候考虑到了时空间的前后关系,并用图卷积实现。
整个网络可以由文章第三节Graph Convolutional Tracking中的公式(1)(2)(3)(4)更加准确的描述。
论文贡献总结
- 提出了一种端到端的网络结构,且首次将图卷积用于SiamNet以实现目标跟踪。
- 将时空间信息用到了基于SiamNet的框架中,大幅提高跟踪器稳定性。
- 在大量数据集上验证了自己的算法并给出了结果。
作者信息 :Junyu Gao1,2,3, Tianzhu Zhang1,2,4 and Changsheng Xu1,2,3
1 National Lab of Pattern Recognition (NLPR),
Institute of Automation, Chinese Academy of Sciences (CASIA)
2 University of Chinese Academy of Sciences (UCAS)
3 Peng Cheng Laboratory, ShenZhen, China
4 University of Science and Technology of China
文章地址:https://www.zpascal.net/cvpr2019/Gao_Graph_Convolutional_Tracking_CVPR_2019_paper.pdf
代码:待作者开源后更新














 2907
2907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









