







笔记
1.评估方法
1.留出法
直接将数据集D 划分为两个互斥的集合,其中一个
集合作为训练集 S,另一个作为测试集T,
即 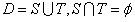 ,
,
在 S上训练出模型后,用 T来评估其测试误差,作为对泛化误差的估计.
2.交叉验证法
将数据 D分为 k个大小相似的互斥子集,
特例:假定数据集D中包含m个样本,若令 k=m ,则得到了交叉验证法的一个特例:留一法
3.自助法
给定包含 m个样本的数据集 D我们对它进行采样产生数据集 D'
2.性能度量

1.错误率与精度
2.查准率、查全率与F1
3.代价敏感错误率与代价曲线
3.比较检验
1.假设检验
2.交叉验证T检验
3.McNemar检验
4.Friedman 检验与 Nemenyl 后续检验
4.偏差与方差
偏差、方差、噪声的含义:
偏差: 度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
方差: 量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;
噪声: 则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
一般来说,偏差与方差是有冲突的,这称为偏差一方差窘境(bias-variance dilemma).
假定我们能控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足
以便学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全
局的特性被学习器学到了,则将发生过拟合.
习题
1.数据集包含 1000 个样本,其中 500 个正例、 500 个反例,将其划分为包含 70% 样本的训练集和 30% 样本的测试集用于留出法评估,试估算共有多少种划分方式.
答:
如果从来样(sampling) 的角度来看待数据集的划分过程,则保留类别比例的采样方式通常称为 “分层采样”。
根据分层采样原则,共有方法:
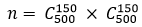
2.数据集包含100 个样本,其中正、反例各一半,假定学习算法所产生的模型是将新样本预测为训练样本数较多的类别(训练样本数相同时进行随机猜测),试给出用10 折交叉验证法和留一法分别对错误率进行评估所得的结果。
答:因为模型是将新样本预测为训练样本数较多的类别
留一法:测试集1个样本,训练集99个样本,50+49,有50个与测试集真实类别不同,故测试集无法被划分到正确的类,错误率100%;
交叉验证法:在采用分层抽样的前提下,分类靠随机猜,错误率因为50%;
3.若学习器A 的F1 值比学习器B 高,试析A 的BEP 值是否也比B 高.
BEP:是"查准率= 查全率"时的取值。
F1:是P与R的调和平均,1/F1 = (1/P + 1/R) / 2;
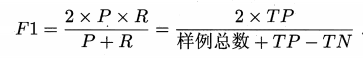

4.试讲述真正例率(TPR) 、假正例率(FPR)与查准率§ 、查全率®之间的联系.
答:
P,查准率(准确率),(预测正例)中(真实正例)的比例.
R,查全率(召回率),(真实正例)中(预测正例)的比例.
TPR,真正例率,(真实正例)中(预测正例)的比例,TPR = R.
FPR,假正例率,(真实反例)中(预测正例)的比例.


5.试证明式(2.22).

ROC 全称是"受试者工作特征" (Receiver Operating Characteristic),ROC 曲线的纵轴是"真正
例率" (True Positive Rate ,简称 TPR) ,横轴是"假正例率" (False Positive Rate ,简称 FPR)。
AUC是ROC 线下 的面积。

6.试述错误率与 ROC 曲线的联系.
错误率可由代价-混淆矩阵得出;
ROC曲线基于TPR与FPR表示了模型在不同截断点取值下的泛化性能。
ROC曲线上的点越靠近(1,0)学习器越完美,但是常需要通过计算等错误率来实现P、R的折衷,而P、R则反映了我们所侧重部分的错误率。
7. 试证明任意一条 ROC 曲线都有一条代价曲线与之对应,反之亦然.
ROC曲线的点对应了一对(TPR,FPR),即一对(FNR,FPR),由此可得一条代价线段(0,FPR)–(1,FNR),由所有代价线段构成簇,围取期望总体代价和它的边界–代价曲线。所以说,ROC对应了一条代价曲线,反之亦然。
8. Min-max 规范化和公score 规范化是两种常用的规范化方法.令
X’ 分别表示变量在规范化前后的取值,相应的,令 Xmin 即表示
规范化前的最小值和最大值 x~in z;mz 表示规范化后的最小值和
最大值,军和 σz 分别表示规范化前的均值和标准差,则 min-max 规范
化、 z-score 规范化分别如式(2 .43) (2 .44) 所示.试析二者的优缺点.
















 7766
7766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









