







从文件中读取数据
要使用文本文件中的信息,首先需要将信息读取到内存中。为此,你可以一次性读取文件的全部内容,也可以以每次一行的方式逐步读取。
读取整个文件
要读取文件,需要一个包含几行文本的文件。下面首先创建一个文件,它包含精确到小数点后30为的圆周率,且在小数点后每10位处换行:
#pi_digits.txt
3.1415926535
8979323846
2643383279
下面的程序打开并读取这个文件,再将内容显示到屏幕上:
#file_reader.py
with open('pi_digits.txt') as file_object:
contents = file_object.read()
print(contents)
在这个程序中,第一行代码做了大量的工作。 我们先来看函数 open()。要以任何方式使用文件,哪怕仅仅是打印其内容,都得先打开文件,才能访问它。函数open()接受一个参数:要打开的文件的名称。Python在当前执行的文件所在的目录中查找指定的文件。在本例中,当前运行的是 dile_reader.py, 因此python在 file_reader.py 的目录中查找 pi_digits.txt。函数 open()返回一个表示文件的对象。 在这里,ooen(pi_digits.txt)返回一个表示文件 pi_digits.txt 的对象,Python将该对象赋给 file_object 供以后使用。
关键字 with 在不再需要访问文件后将其关闭。在这个程序中,注意到我们调用了 open(),但没有调用close()。也可以调用open()和close()来打开和关闭文件,但这样做时,如果程序存在bug导致方法close()未执行,文件将不会关闭。这看似微不足道,但未妥善关闭文件可能导致数据丢失或受损。 如果在程序中过早调用 close(),你会发现需要使用文件时它已关闭(无法访问),这会导致更多的错误。并未在任何情况下都能轻松确定关闭文件的恰当时机,但通过使用前面所示的结构,可让Python去确认:你只管打开文件,并在需要时使用它,Python自会在合适的时候自动将其关闭。
有了表示 pi_digits.txt 的文件对象后,使用方法 read() 读取这个文件的全部内容,并将其作为一个长长的字符串赋给变量 contents。这样,通过打印 contents 的值,就可将这个文本文件的全部内容显示出来。
相比原始文件,该输出唯一不同的地方时末尾多了一个空行。为何会多出这个空行呢?因为 read() 到达文件末尾时返回一个空字符串,而将这个字符串显示出来就是一个空行。 要删除多出来的空行,可在函数调用 print()中使用rstrip():
with open('pi_digits.txt') as file_object:
contents = file_object.read()
print(contents.rstrip())
文件路径
- 相对文件路径
例如,你可能将程序文件存储在了文件夹 python_work 中, 而该文件夹中有一个名为 text_files 的文件夹用于存储程序文件操作的文本文件.
with open('text_files/filename.txt') as file_object
这行代码让Python到文件夹 python_work 下的文件夹 text_files 中去查找指定的 .txt 文件
显示文件路径时,Windows系统使用反斜杠(\)而不是斜杠(/),但在代码中依然可以使用斜杠。
- 绝对文件路径
绝对路径通常比相对路径长,因此将其赋给一个变量,再将该变量传递给 open()会有所帮助:
file_path = '/home/ehmatthes/other_files/text_files/filename.txt'
with open(file_path) as file_object
通过使用绝对路径,可读取系统中任何地方的文件。就目前而言,最简单的做法是,要么将数据文件存储在程序文件所在的目录,要么将其存储在程序文件所在目录下的一个文件夹(如 text_file)中。
如果在文件路径中直接使用反斜杠,将引发错误,因为反斜杠用于对字符串中的字符进行转移。例如,对于路径"C:\path\to\file.txt",其中的 \t 将被解读为制表符。如果一定要使用反斜杠,可对路径中的每个反斜杠都进行转义,如:“C:\path\to\file.txt”。
逐行读取
file_name = 'pi_digits.txt'
with open(file_name) as file_object:
for line in file_object:
print(line)
file_name = 'pi_digits.txt' 将要读取的文件的名称赋给变量 filename。这是使用文件时的一种常见做法。 变量 filename 表示的并非实际文件——它只是一个让Python知道到哪里去查找文件的字符串,因此可以轻松地将 pi_digits.txt替换为要使用的另一个文件的名称。
with open(file_name) as file_object:调用open()后,将一个表示文件及其能用的对象赋给了变量 file_object。这里也使用了关键字with,让Python负责妥善的打开和关闭文件。
for line in file_object:为查看文件的内容,通过对文件对象执行循环来便利文件中的每一行。
打印每一行时,发现空白更多了:

为何会出现这些空白行呢?因为在这个文件中,每行的末尾都有一个看不见的换行符,而函数调用 print()也会加上一个换行符,因此每行末尾都有两个换行符:一个来自文件,另一个来自函数调用print()。要消除这些多余的空白行,可在函数调用 print()中使用rstrip():
file_name = 'pi_digits.txt'
with open(file_name) as file_object:
for line in file_object:
print(line.rstrip())
现在,输出又与文件内容完全相同了。
创建一个包含文件各行内容的列表
使用关键字 with 时,open()返回的文件对象只在 with 代码块内可用。如果要在 with 代码块外访问文件的内容,可在 with 代码块内将文件的各行存储在一个列表中,并在 with 代码块外使用该列表:可以立即处理文件的各个部分,也可以推迟到程序后面再处理。
下面的实例在 with 代码块中将文件 pi_digits.txt 的各行存储在一个列表中,再在 with 代码块外打印:
file_name = 'pi_digits.txt'
with open(file_name) as file_object:
lines = file_object.readlines()
for line in lines:
print(line.rstrip())
lines = file_object.readlines()中的方法 readlines()从文件中读取每一行,并将其存储在一个列表中,接下来,该变量赋给变量lines。
因为列表lines的每个元素都对应与文件的每一行,所以输出与文件内容完全一致。
使用文件的内容
将文件读取到内存中后,就能以任何方式使用这些数据了。下面以简单的方式使用圆周率的值。首先创建一个字符串,它包含文件中存储的所有数字,且没有让空格:
#pi_string.py
file_name = "pi_digits.txt"
with open(file_name) as file_ogject:
lines = file_ogject.readlines()
pi_string = ''
for line in lines:
pi_string += line.strip()
print(pi_string)
print(len(pi_string))

:::tips
读取文本文件时,Python将其中的所有文本都解读为字符串。如果读取的时数,并要将其作为数值使用,就必须使用函数int()将其转换为整数或使用函数float()将其转换为浮点数
:::
包含一百万位的大型文件
filename = 'pi_million_digits.txt'
with open(filename) as file_object:
lines = file_object.readlines()
pi_string = ''
for line in lines:
pi_string += line.strip()
print(f"{pi_string[:52]}...")
print(len(pi_string))
#在这里,只打印到小数点后50位,以免终端为显示全部1 000 000位而不断滚动。
输出表明,创建的字符串确实包含精确到小数点后 1 000 000 位的圆周率值:

对于可处理的数据量,Python没有任何限制。只要系统的内存足够多,你想处理多少都可以。
圆周率包含你的生日吗
filename = 'pi_million_digits.txt'
with open(filename) as file_object:
lines = file_object.readlines()
pi_string = ''
for line in lines:
pi_string += line.strip()
'''
print(f"{pi_string[:52]}...")
print(len(pi_string))
'''
birthday = input("Enter your birthday, in the form mmddyy: ")
if birthday in pi_string:
print("Your birthday appears in the first million digits of pi!")
else:
print("Your birthday does not appear in the first million digits of pi.")
写入文件
保存数据的最简单方式之一是将其写入文件中。通过将输出写入文件,即便关闭包含程序输出的终端窗口,这些输出也依然存在:可以在程序结束运行后查看这些输出,可以与别人分享输出文件,还可以编写程序来将这些输出读取到内存中并进行处理。
写入空文件
要将文本写入文件,在调用open()时需要提供另一个实参,告诉Python你要写入打开的文件。为明白其中的工作原理,我们来将一条简单的消息存储到文件中,而不是将其打印到屏幕上:
filename = 'programming.txt'
with open(filename, 'w') as file_object:
file_object.write("I love programming.")
with open(filename, 'w') as file_object: 在本例中,调用open()时提供了两个实参。第一个实参也是要打开的文件名称。第二个实参(‘w’)告诉Python,要以写入模式打开这个文件。打开文件时,可指定读取模式(‘r’)、写入模式(‘w’)、附加模式(‘a’)或读写模式(‘r+’)。如果省略了模式形参,Python将以默认的只读模式打开文件。
如果要写入的文件不存在,函数open()将自动创建它。然而,以写入模式(‘w’)打开文件时千万要小心,因为如果指定的文件已经存在,Python将在返回文件对象前清空该文件的内容。
file_object.write("I love programming.")使用文件对象的方法write()将一个字符串写入文件。这个程序没有终端输出。但如果打开文件 programming.txt 将看到其中包含如下一行内容:
I love programming.
相比于计算器中的其他文件,这个文件没有什么不同,你可以打开它、在其中输入新文本、复制其内容、将内容粘贴到其中,等等。
:::tips
Python只能将字符串写入文本文件。要将数值数据存储到文本文件中,必须先使用函数str()将其转换为字符串格式。
:::
写入多行
函数write()不会再写入的文件末尾添加换行符,因此如果写入多行时没有指定换行符,文件看起来可能不是你希望的那样:
filename = 'programming.txt'
with open(filename, 'w') as file_object:
file_object.write("I love programming.")
file_object.write("I love creating new games.")
如果你打开 programming.txt,将发现两行内容挤在一起:
I love programming.I love creating new games.
要让每个字符串都独占一行,需要再方法调用 write()中包含换行符:
filename = 'programming.txt'
with open(filename, 'w') as file_object:
file_object.write("I love programming.\n")
file_object.write("I love creating new games.\n")
现在,输出出现在不同的行中:
I love programming.
I love creating new games.
:::tips
像显示到终端的输出一样,还可以使用空格、制表符和空行来设置这些输出的格式。
:::
附加到文件
如果要给文件添加内容,而不是覆盖原有的内容,可以以附加模式打开文件。以附加模式打开文件时,Python不会再返回文件对象前清空文件的内容,而是将写入文件的行添加到文件末尾。如果指定的文件不存在,Python将为你创建一个空文件。
下面来修改 write_message.py
filename = 'programming.txt'
with open(filename, 'a') as file_object:
file_object.write("I also love finding meaning in large datasets.\n")
file_object.write("I love creating apps that can run in a browser.\n")
with open(filename, 'a') as file_object: 打开文件时指定了实参 ‘a’ , 以便将内容附加到文件末尾,而不是覆盖文件原来的内容。
I love programming.
I love creating new games.
I also love finding meaning in large datasets.
I love creating apps that can run in a browser.
最终的结果是,文件原来的内容还在,后面则是刚添加的内容。
异常
Python使用称为异常的特殊对象来管理程序执行期间发生的错误。每当发生让Python不知所措的错误时,它都会创建一个异常对象。如果你编写了处理该异常的代码,程序将继续运行;如果未对异常进行处理,程序将停止并显示traceback,其中包含有关异常的报告。
异常是使用 try-except 代码块处理的。 try-except 代码块让Python执行指定的操作,同时告诉Python发生异常怎么办。使用 try-except 代码块时, 即便出现异常,程序也将继续运行:显示你编写的友好的错误消息,而不是令用户迷惑的 traceback。
处理ZeroDivisionError异常
下面来看一种导致Python引发异常的简单错误。你可能知道,不能用数除以0,但还是让python这样做
#division_calculator.py
print(5/0)
显然,Python无法这样做,因此你将看到一个traceback:
Traceback (most recent call last):
File "division_calculator.py", line 1, in <module>
print(5/0)
ZeroDivisionError: division by zero
ZeroDivisionError: division by zero : 在上述 traceback中, 指出的错误 ZeroDivisionError 是个异常对象。 Python无法按你的要求做时,就会创建这种对象。在这种情况下, Python将停止运行程序, 并指出引发了哪种异常, 而我们可根据这些信息对程序进行修改。
下面来告诉Python,发生这种错误时怎么办。这样,如果再次发生此类错误,我们就有备无患了。
使用 try-except 代码块
处理ZeroDivisionError异常的try-except代码块类似于下面这样:
try:
print(5/0)
except ZeroDivisionError:
print("You can't divide by zero!")
将导致错误的代码行print(5/0)放在一个try代码块中。如果try代码块中的代码运行起来没有问题,Python将跳过except代码块块;如果try代码块中的代码导致了错误,Python将查找与之匹配的except代码块并运行其中的代码。
如果 try-except 代码块后面还有其他代码,程序将接着运行,因为已经告诉了Python如何处理这种错误。
使用异常避免崩溃
发生错误时,如果程序还有工作尚未完成,妥善地处理错误就尤其重要。这种情况经常会出现在要求用户提供输入的程序中;如果程序能够妥善的处理无效输入,就能再提升用户提供有效输入,而不至于崩溃。
下面来创建一个只执行除法运算的简单计算器:
#division_calculator.py
print("Give me two numbers, and I'll divide them.")
print("Enter 'q' to quit.")
while True:
first_number = input("\nFirst number: ")
if first_number == 'q':
break
second_number = input("\nSecond number: ")
if second_number == 'q':
break
answer = int(first_number) / int(second_number)
print(answer)
该程序没有采取任何处理错误的措施,因此在执行除数为0的除法运算时,它将崩溃:
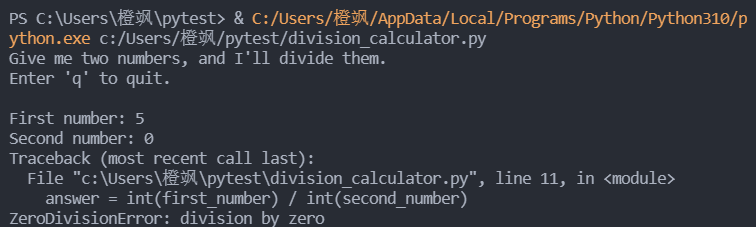
:::tips
让用户看到 traceback,不懂技术的用户会被搞糊涂,怀有恶意的用户还会通过 traceback 获悉你不想他知道的信息。 例如,他将知道你的程序文件的名称,还能看到部分不能正确运行的代码。有时候,训练有素的攻击者可根据这些信息判断出可对你的代码发起什么样的攻击。
:::
else代码块
通过将可能引发错误的代码块放在 try-except 代码块中, 可提高程序抵御错误的能力。 错误是执行除法运算的代码导致的,因此需要将它放到 try-except 代码块中。 这个实例还包含一个 else 代码块。 依赖 try 代码块成功执行的代码都应放到else代码块中:
print("Give me two numbers, and I'll divide them.")
print("Enter 'q' to quit.")
while True:
first_number = input("\nFirst number: ")
if first_number == 'q':
break
second_number = input("Second number: ")
if second_number == 'q':
break
try:
answer = int(first_number) / int(second_number)
except ZeroDivisionError:
print("You can't divide by 0!")
else:
print(answer)
try代码块只包含可能导致错误的代码,依赖try代码块成功执行的代码都放在else代码块中; except代码块告诉Python, 出现 ZeroDivisionError 异常时该如何办,如果 try代码块因除零错误而失败,就打印一条友好的信息,告诉用户如何避免这种错误,程序继续运行,用户根本看不到 traceback:
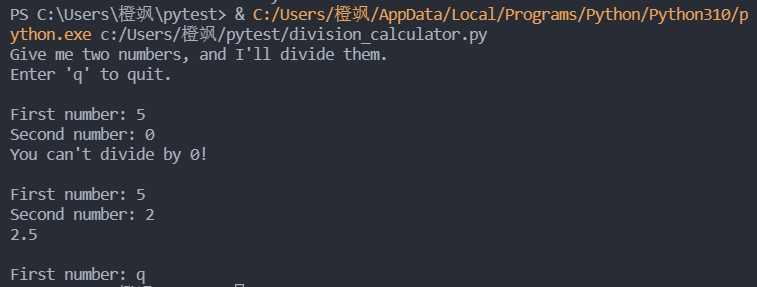
try-except-else代码块的工作原理大致如下,Python尝试执行try代码块中的代码,只有可能引发异常的代码才需要放在try语句中。有时候,有一些仅在try代码块成功执行时才需要运行的代码,这些代码应放在else代码块中。except代码块告诉Python,如果尝试运行try代码块中的代码引发了指定的异常该怎么办。
通过预测可能发生错误的代码,可编写健壮的程序。它们即便面临无效数据或缺少资源,也能继续运行,从而抵御无意的用户错误和恶意的攻击。
处理FileNotFoundError异常
使用文件时,一种常见的问题是找不到文件:查找的文件可能在其他地方,文件名可能不正确,或者这个文件根本就不存在。对于所有这些情形,都可使用try-except代码块以直观的方式处理。
我们来尝试读取一个不存在的文件。下面的程序尝试读取文件alice.txt的内容,但该文件没有存储在alice.py所在的目录中:
#alice.py
filename = 'alice.txt'
with open(filename,encoding='utf-8') as f:
content = f.read()
相比于本章前面的文件打开方式,这里有两个不同之处。一是使用变量f来表示文件对象,这是一种常见的做法。二是给参数encoding指定了值,在系统的默认编码与要读取文件使用的编码不一致时,必须这样做。
Python无法读取不存在的文件,因此它引发一个异常:
上述traceback的最后一行报告了FileNotFoundError异常,这是Python找不到要打开的文件时创建的异常。在本例中,这个错误是函数open()导致的。因此,要处理这个错误,必须将try语句放在包含open()的代码行之前:
filename = 'alice.txt'
try:
with open(filename,encoding='utf-8') as f:
content = f.read()
except:
print(f"Sorry, the file {filename} does not exist.")
如果文件不存在,这个程序就什么都做不了,错误处理代码也意义不大。下面来扩展这个示例,看看在你使用多个文件时,异常处理可提供什么样的帮助。
分析文本
你可以分析包含整本书的文本文件。很多经典文学作品都是简单以文本文件的形式提供的,因为它们不受版权限制。本节使用的文本来自古登堡计划,该计划提供了一系列不受版权限制的文学作品。如果你要在编程项目中使用文学文本,这是一个很不错的资源。
下面来提取童话《爱丽丝漫游奇境记》(Alice in Wonderland)的文本,并尝试计算它包含多少个单词。我们将使用方法**split()**,它能根据一个字符串创建一个单词列表。下面是对只包含童话名"Alice in Wonderland"的字符串调用方法split()的结果:
title = "Alice in Wonderland"
title.split()
['Alice', 'in', 'Wonderland']
**方法split()以空格为分隔符将字符串分拆成多个部分,并将这些部分都存储到一个列表中。**结果是一个包含字符串中所有单词的列表,虽然有些单词可能包含标点。为计算《爱丽丝漫游奇境记》包含多少个单词,我们将对整篇小说调用split(),再计算得到的列表包含多少个元素,从而确定整篇童话大致包含多少个单词:
filename = 'alice.txt'
try:
with open(filename,encoding='utf-8') as f:
content = f.read()
except:
print(f"Sorry, the file {filename} does not exist.")
else:
# 计算该文件大致包含多少个单词
words = content.split()
num_words = len(words)
print(f"The file {filename} has about {num_words} words.")
我们将文件alice.txt移到了正确的目录中,让try代码块能够成功执行。在words = content.split()处,对变量contents(它现在是一个长长的字符串,包含童话《爱丽丝漫游奇境记》的全部文本)调用方法split(),以生成一个列表,其中包含这部童话中的所有单词。使用len()来确定这个列表的长度时,就能知道原始字符串大致包含多少个单词了(见num_words = len(words))。在print(f"The file {filename} has about {num_words} words.")处,打印一条消息,指出文件包含多少个单词。这些代码都放在else代码块中,因为仅当try代码块成功执行时才执行它们。输出指出了文件alice.txt包含多少个单词:
PS C:\Users\橙飒\pytest> & C:/Users/橙飒/AppData/Local/Programs/Python/Python310/python.exe c:/Users/橙飒/pytest/alice.py
The file alice.txt has about 29465 words.
这个数稍大一点,因为使用的文本文件包含出版商提供的额外信息,但还是成功估算出了童话《爱丽丝漫游奇境记》的篇幅。
使用多个文件
下面多分析几本书。这此之前,先将这个程序的大部分代码移到一个名为count_words()的函数中。这样,对多本书进行分析时将更容易:
def count_words(filename):
'''计算一个文件大致包含多少个单词。'''
try:
with open(filename,encoding='utf-8') as f:
content = f.read()
except:
print(f"Sorry, the file {filename} does not exist.")
else:
# 计算该文件大致包含多少个单词
words = content.split()
num_words = len(words)
print(f"The file {filename} has about {num_words} words.")
filename = 'alice.txt'
count_words(filename)
这些代码大多与原来一样,只是移到了函数count_words()中,并增加了缩进量。修改程序的同时更新注释是个不错的习惯,因此我们将注释改成文档字符串,并稍微调整了一下措辞'''计算一个文件大致包含多少个单词。'''
现在可以编写一个简单的循环,计算要分析的任何文本包含多少个单词了。为此,将要分析的文件的名称存储在一个列表中,然后对列表中的每个文件调用count_words()。我们将尝试计算《爱丽丝漫游奇境记》《悉达多》(Siddhartha)、《白鲸》(Moby Dick)和《小妇人》(Little Women)分别包含多少个单词,它们都不受版权限制。我故意没有将siddhartha.txt放到word_count.py所在的目录中,从而展示该程序在文件不存在时应对得有多出色:
def count_words(filename):
'''计算一个文件大致包含多少个单词。'''
try:
with open(filename,encoding='utf-8') as f:
content = f.read()
except:
print(f"Sorry, the file {filename} does not exist.")
else:
# 计算该文件大致包含多少个单词
words = content.split()
num_words = len(words)
print(f"The file {filename} has about {num_words} words.")
filenames = ['alice.txt', 'siddhartha.txt','moby_dick.txt','little_women.txt']
for filename in filenames:
count_words(filename)
PS C:\Users\橙飒\pytest> & C:/Users/橙飒/AppData/Local/Programs/Python/Python310/python.exe c:/Users/橙飒/pytest/word_count.py
The file alice.txt has about 29465 words.
Sorry, the file siddhartha.txt does not exist.
Sorry, the file moby_dick.txt does not exist.
Sorry, the file little_women.txt does not exist.
在本例中,使用try-except代码块提供了两个重要的优点:**避免用户看到traceback,以及让程序继续分析能够找到的其他文件。**如果不捕获因找不到siddhartha.txt而引发的FileNotFoundError异常,用户将看到完整的traceback,而程序将在尝试分析《悉达多》后停止运行。它根本不会分析《白鲸》和《小妇人》。
静默失败
在前一个示例中,我们告诉用户有一个文件找不到。但并非每次捕获到异常都需要告诉用户,有时候你希望程序在发生异常时保持静默,就像什么都没有发生一样继续运行。要让程序静默失败,可像通常那样编写try代码块,但在except代码块中明确地告诉Python什么都不要做。Python有一个pass语句,可用于让Python在代码块中什么都不要做:
def count_words(filename):
'''计算一个文件大致包含多少个单词。'''
try:
with open(filename,encoding='utf-8') as f:
content = f.read()
except:
pass
else:
# 计算该文件大致包含多少个单词
words = content.split()
num_words = len(words)
print(f"The file {filename} has about {num_words} words.")
filenames = ['alice.txt', 'siddhartha.txt','moby_dick.txt','little_women.txt']
for filename in filenames:
count_words(filename)
相比于前一个程序,这个程序唯一的不同之处是pass语句。现在,出现FileNotFoundError异常时,将执行except代码块中的代码,但什么都不会发生。这种错误发生时,不会出现traceback,也没有任何输出。用户将看到存在的每个文件包含多少个单词,但没有任何迹象表明有一个文件未找到.
pass语句还充当了占位符,提醒你在程序的某个地方什么都没有做,并且以后也许要在这里做些什么。例如,在这个程序中,我们可能决定将找不到的文件的名称写入文件missing_files.txt中。用户看不到这个文件,但我们可以读取它,进而处理所有找不到文件的问题。
决定报告哪些错误
该在什么情况下向用户报告错误?又该在什么情况下静默失败呢?如果用户知道要分析哪些文件,他们可能希望在有文件却没有分析时出现一条消息来告知原因。如果用户只想看到结果,并不知道要分析哪些文件,可能就无须在有些文件不存在时告知他们。向用户显示他不想看到的信息可能会降低程序的可用性。Python的错误处理结构让你能够细致地控制与用户分享错误信息的程度,要分享多少信息由你决定。
编写得很好且经过详尽测试的代码不容易出现内部错误,如语法或逻辑错误,但只要程序依赖于外部因素,如用户输入、存在指定的文件、有网络链接,就有可能出现异常。凭借经验可判断该在程序的什么地方包含异常处理块,以及出现错误时该向用户提供多少相关的信息。
存储数据
很多程序都要求用户输入某种信息,如让用户存储游戏首选项或提供要可视化的数据。不管关注点是什么,程序都把用户提供的信息存储在列表和字典等数据结构中。用户关闭程序时,几乎总是要保存他们提供的信息。一种简单的方式是使用模块json来存储数据。
模块json让你能够将简单的Python数据结构转储到文件中,并在程序再次运行时加载该文件中的数据。你还可以使用json在Python程序之间分享数据。更重要的是,JSON数据格式并非Python专用的,这让你能够将以JSON格式存储的数据与使用其他编程语言的人分享。这是一种轻便而有用的格式,也易于学习。
:::info
注意 JSON(JavaScript Object Notation)格式最初是为JavaScript开发的,但随后成了一种常见格式,被包括Python在内的众多语言采用
:::
使用 json.dump() 和 json.load()
我们来编写一个存储一组数的简短程序,再编写一个将这些数读取到内存中的程序。第一个程序将使用**json.dump()**来存储这组数,而第二个程序将使用**json.load()**。
函数**json.dump()****接受两个实参:要存储的数据,以及可用于存储数据的文件对象。**下面演示了如何使用**json.dump()**来存储数字列表:
#number_writer.py
import json
numbers =[2, 3, 5, 7, 11, 13]
filename = 'numbers.json'
with open(filename, 'w') as f:
json.dump(numbers, f)
先导入模块json, 再创建一个数字列表。 在filename = 'numbers.json'处,指定了要将该数字列表存储到哪个文件中。通常使用文件扩展名.json来指出文件存储的数据为JSON格式。
with open(filename, 'w') as f:接下来,以写入模式打开这个文件,让json能够将数据写入其中
json.dump(numbers, f)使用函数json.dump()将数字列表存储到文件numbers.json中。
这个程序没有输出,但可以打开文件numbers.json来看看内容。数据的存储格式与Python中一样:
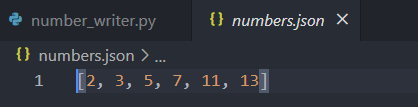
下面再编写一个程序,使用json.load()将列表读取到内存中:
#number_reader.py
import json
filename = 'numbers.json'
with open(filename) as f:
numbers = json.load(f)
print(numbers)
filename = 'numbers.json'处,确保读取的是前面写入的文件。
with open(filename) as f:这次以读取方式打开该文件,因为Python只需要读取它。
numbers = json.load(f)使用函数json.load()加载存储在numbers.json中的信息,并将其赋给变量 numbers。
最后,打印恢复的数字列表,看看是否与 number_writer.py 中创建的数字列表相同
PS C:\Users\橙飒\pytest> & C:/Users/橙飒/AppData/Local/Programs/Python/Python310/python.exe c:/Users/橙飒/pytest/number_reader.py
[2, 3, 5, 7, 11, 13]
这是一种在程序之间共享数据的简单方式。
保存和读取用户生成的数据
使用json保存用户生成的数据大有裨益,因为如果不以某种方式存储,用户的信息会在程序停止运行时丢失。下面来看一个这样的例子:提示用户首次运行程序时输入自己的名字,并在再次运行程序时记住他。
先来存储用户的名字:
#remember_me.py
import json
username = input("What is your name? ")
filename = 'user_name.json'
with open(filename, 'w') as f:
json.dump(username, f)
print(f"We'll remember you when you come back, {username}!")
username = input("What is your name? ") 提示输入用户名并将其赋给一个变量。
json.dump(username, f)接下来,调用json.dump(),并将用户名和一个文件对象传递给它,从而将用户名存储到文件中。
print(f"We'll remember you when you come back, {username}!")然后,打印一条消息,指出存储了用户输入的信息。
PS C:\Users\橙飒\pytest> & C:/Users/橙飒/AppData/Local/Programs/Python/Python310/python.exe c:/Users/橙飒/pytest/remember_me.py
What is your name? Eric
We'll remember you when you come back, Eric!
现在再编写一个程序,向已存储了名字的用户发出问候:
#greet_user.py
import json
filename = 'user_name.json'
with open(filename) as f:
username = json.load(f)
print(f"Welcome back, {username}")
username = json.load(f)使用json.load()将存储在usrname.json中的信息读取到变量username中。回复用户名后,就可以欢迎用户回来了:
PS C:\Users\橙飒\pytest> & C:/Users/橙飒/AppData/Local/Programs/Python/Python310/python.exe c:/Users/橙飒/pytest/greet_user.py
Welcome back, Eric
需要将这两个程序合并到一个程序(remember_me.py)中。这个程序运行时,将尝试从文件username.json中获取用户名。因此,首先编写一个尝试恢复用户名的try代码块。如果这个文件不存在,就在except代码块中提示用户输入用户名,并将其存储到username.json中,以便程序再次运行时能够获取:
#remember_me.py
import json
# 如果以前存储了用户名,就加载它。
# 否则,提示用户输入用户名并储存它。
filename = 'username.json'
try:
with open(filename) as f:
username = json.load(f)
except FileNotFoundError:
username = input("What is your name? ")
with open(filename, 'w') as f:
json.dump(username, f)
print(f"We'll remember you when you come back, {username}!")
else:
print(f"Welcome back, {username}!")
这里没有任何新代码,这是将前两个示例的代码合并到了一个程序中。在with open(filename) as f:中,尝试打开 username.json 。
username = json.load(f)如果该文件存在,就将其中的用户名读取到内存中,再执行else代码块,打印一条欢迎用户回来的消息。
except FileNotFoundError:用户首次运行该程序时,文件username.json 不存在, 将引发 FileNotFoundError异常,因此Python将执行 except代码块,提示用户输入用户名,再使用 json.dump() 存储该用户和合适的问候语。
重构
你经常会遇到这样的情况:代码能够正确地运行,但通过将其划分为一系列完成具体工作的函数,还可以改进。这样的过程称为重构。重构让代码更清晰、更易于理解、更容易扩展。
要重构remember_me.py,可将其大部分逻辑放到一个或多个函数中。remember_me.py的重点是问候用户,因此将其所有代码都放到一个名为greet_user()的函数中:
import json
def greet_user():
'''问候用户,并指出其名字'''
filename = 'username.json'
try:
with open(filename) as f:
username = json.load(f)
except FileNotFoundError:
username = input("What is your name? ")
with open(filename, 'w') as f:
json.dump(username, f)
print(f"We'll remember you when you come back, {username}!")
else:
print(f"Welcome back, {username}!")
greet_user()
考虑到现在使用了一个函数,我们删除原注释,转而使用一个文档字符串来指出程序的作用。这个程序更加清晰,但函数greet_user()所做的不仅仅是问候用户,还在存储了用户名时获取它、在没有存储用户名时提示用户输入。
下面来重构greet_user(),减少其任务。为此,首先将获取已存储用户名的代码移到另一个函数中:
import json
def get_stored_username():
'''如果存储了用户名,就获取它。'''
filename = 'username.json'
try:
with open(filename) as f:
username = json.load(f)
except FileNotFoundError:
return None
else:
return username
def greet_user():
'''问候用户,并指出其名字'''
username = get_stored_username()
if username:
print(f"Welcome back, {username}!")
else:
username = input("What is your name? ")
filename = 'username.json'
with open(filename, 'w') as f:
json.dump(username, f)
print(f"We'll remember you when you come back, {username}!")
greet_user()
新增的函数get_stored_username()目标明确,'''如果存储了用户名,就获取它。'''处的文档字符串指出了这一点。如果存储了用户名,该函数就获取并返回它;如果文件username.json不存在,该函数就返回None(见return None)。这是一种不错的做法:函数要么返回预期的值,要么返回None。这让我们能够使用函数的返回值做简单的测试。在if username:处,如果成功地获取了用户名,就打印一条欢迎用户回来的消息,否则提示用户输入用户名。
还需要重构greet_user()中的另一个代码块,将没有存储用户名时提示用户输入的代码放在一个独立的函数中:
import json
def get_stored_username():
'''如果存储了用户名,就获取它。'''
filename = 'username.json'
try:
with open(filename) as f:
username = json.load(f)
except FileNotFoundError:
return None
else:
return username
def get_new_username():
'''提示用户输入用户名。'''
username = input("What is your name? ")
filename = 'username.json'
with open(filename, 'w') as f:
json.dump(username,f)
return username
def greet_user():
'''问候用户,并指出其名字'''
username = get_stored_username()
if username:
print(f"Welcome back, {username}!")
else:
username = get_new_username()
print(f"We'll remember you when you come back, {username}!")
greet_user()
在remember_me.py的这个最终版本中,每个函数都执行单一而清晰的任务。我们调用greet_user(),它打印一条合适的消息:要么欢迎老用户回来,要么问候新用户。为此,它首先调用get_stored_username(),该函数只负责获取已存储的用户名(如果存储了的话)。最后在必要时调用get_new_username(),该函数只负责获取并存储新用户的用户名。要编写出清晰而易于维护和扩展的代码,这种划分必不可少。















 2127
2127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









