







文章目录
线性回归
模型:y = wx+b
损失函数: 一般为平方差损失
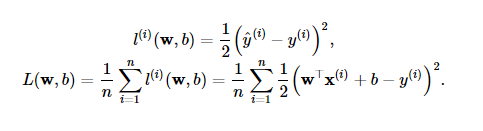
优化函数:梯度下降法(每次训练更新表达如下)

Softmax与分类模型
对于线性回归, 输出层输出有以下问题:
1,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。
2,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax 可将输出值变换成值为正且和为1的概率分布:


小批量矢量计算表达式: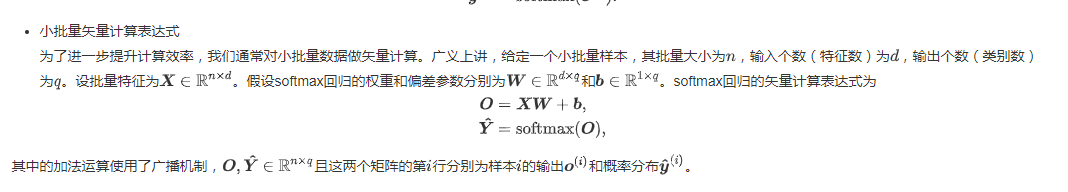
损失函数:交叉熵损失(更适合衡量两个概率分布差异的测量函数)
交叉熵:
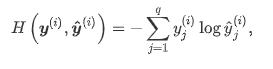
交叉熵损失:
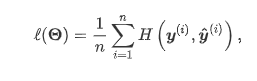
多层感知机
图表示:

表达公式:
具体来说,给定一个小批量样本 X∈Rn×d ,其批量大小为 n ,输入个数为 d 。假设多层感知机只有一个隐藏层,其中隐藏单元个数为 h 。记隐藏层的输出(也称为隐藏层变量或隐藏变量)为 H ,有 H∈Rn×h 。因为隐藏层和输出层均是全连接层,可以设隐藏层的权重参数和偏差参数分别为 Wh∈Rd×h 和 bh∈R1×h ,输出层的权重和偏差参数分别为 Wo∈Rh×q 和 bo∈R1×q 。
对于一个含有一个隐藏层的多层感知机,有:
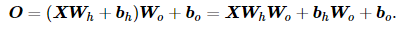
激活函数:
从上面式子联立后的式子可以看出,虽然神经网络引入了隐藏层,却依然等价于一个单层神经网络:其中输出层权重参数为 WhWo ,偏差参数为 bhWo+bo 。不难发现,即便再添加更多的隐藏层,以上设计依然只能与仅含输出层的单层神经网络等价。
上述问题的根源在于全连接层只是对数据做仿射变换(affine transformation),而多个仿射变换的叠加仍然是一个仿射变换。解决问题的一个方法是引入非线性变换,例如对隐藏变量使用按元素运算的非线性函数进行变换,然后再作为下一个全连接层的输入。这个非线性函数被称为激活函数(activation function)。
常用激活函数如下:
1,Relu:(ReLU函数只保留正数元素,并将负数元素清零)
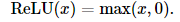
2,Sigmoid:(sigmoid函数可以将元素的值变换到0和1之间)
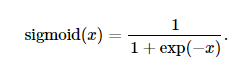
3,tanh:(tanh(双曲正切)函数可以将元素的值变换到-1和1之间)
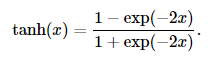
其中 tanh的导数如下:(当输入为0时,tanh函数的导数达到最大值1;当输入越偏离0时,tanh函数的导数越接近0)
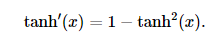
关于激活函数的选择
a,ReLu函数是一个通用的激活函数,目前在大多数情况下使用。但是,ReLU函数只能在隐藏层中使用。
b,用于分类器时,sigmoid函数及其组合通常效果更好。由于梯度消失问题,有时要避免使用sigmoid和tanh函数。
c,在神经网络层数较多的时候,最好使用ReLu函数,ReLu函数比较简单计算量少,而sigmoid和tanh函数计算量大很多。
d,在选择激活函数的时候可以先选用ReLu函数如果效果不理想可以尝试其他激活函数。
文本预处理
预处理通常包括四个步骤:
1,读入文本
2,分词
3,建立字典,将每个词映射到一个唯一的索引(index)
4,将文本从词的序列转换为索引的序列,方便输入模型
python示例:
读入文本
import collections
import re
def read_time_machine():
with open('/home/kesci/input/timemachine7163/timemachine.txt', 'r') as f:
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
return lines
lines = read_time_machine()
print('# sentences %d' % len(lines))
英文分词
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
if token == 'word':
return [sentence.split(' ') for sentence in sentences]
elif token == 'char':
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unkown token type '+token)
tokens = tokenize(lines)
tokens[0:2]
建立字典(为了方便模型处理,我们需要将字符串转换为数字。因此我们需要先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号。)
class Vocab(object):
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
counter = count_corpus(tokens) # :
self.token_freqs = list(counter.items())
self.idx_to_token = []
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['', '', '', '']
else:
self.unk = 0
self.idx_to_token += ['']
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
self.token_to_idx = dict()
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def count_corpus(sentences):
tokens = [tk for st in sentences for tk in st]
return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
用现有工具进行分词:
spaCy, NLTK(英文)
jieba(中文)
语言模型(基于统计)
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为 T 的词的序列 w1,w2,…,wT ,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
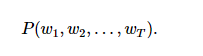
假设序列 w1,w2,…,wT 中的每个词是依次生成的,我们有
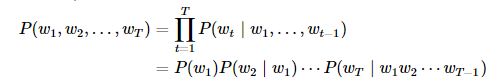
语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如, w1 的概率可以计算为:
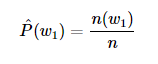
类似的,给定 w1 情况下, w2 的条件概率可以计算为:
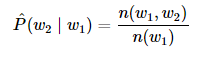
n元语法:
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。 n 元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面 n 个词相关,即 n 阶马尔可夫链(Markov chain of order n ),如果 n=1 ,那么有 P(w3∣w1,w2)=P(w3∣w2) 。基于 n−1 阶马尔可夫链,我们可以将语言模型改写为
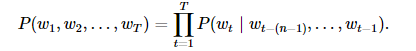
当 n 分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。例如,长度为4的序列 w1,w2,w3,w4 在一元语法、二元语法和三元语法中的概率分别为
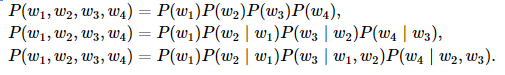
当 n 较小时, n 元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当 n 较大时, n 元语法需要计算并存储大量的词频和多词相邻频率。
n 元语法缺陷:
a,参数空间过大
b,数据稀疏
循环神经网络
图式:
下图展示了如何基于循环神经网络实现语言模型。我们的目的是基于当前的输入与过去的输入序列,预测序列的下一个字符。循环神经网络引入一个隐藏变量 H ,用 Ht 表示 H 在时间步 t 的值。 Ht 的计算基于 Xt 和 Ht−1 ,可以认为 Ht 记录了到当前字符为止的序列信息,利用 Ht 对序列的下一个字符进行预测。

表达式:
我们先看循环神经网络的具体构造。假设 Xt∈Rn×d 是时间步 t 的小批量输入, Ht∈Rn×h 是该时间步的隐藏变量,则:
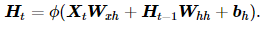
其中, Wxh∈Rd×h , Whh∈Rh×h , bh∈R1×h , ϕ 函数是非线性激活函数。由于引入了 Ht−1Whh , Ht 能够捕捉截至当前时间步的序列的历史信息,就像是神经网络当前时间步的状态或记忆一样。由于 Ht 的计算基于 Ht−1 ,上式的计算是循环的,使用循环计算的网络即循环神经网络(recurrent neural network)。
在时间步 t ,输出层的输出为:
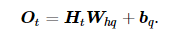
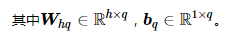
Pytorch中的nn.RNN来构造循环神经网络,参数如下:
- input_size - The number of expected features in the input x
- hidden_size – The number of features in the hidden state h
- nonlinearity – The non-linearity to use. Can be either ‘tanh’ or ‘relu’. Default: ‘tanh’
- batch_first – If True, then the input and output tensors are provided as (batch_size, num_steps, input_size). Default: False
这里的batch_first决定了输入的形状,我们使用默认的参数False,对应的输入形状是 (num_steps, batch_size, input_size)。
forward函数的参数为:
-
input of shape (num_steps, batch_size, input_size): tensor containing the features of the input sequence.
-
h_0 of shape (num_layers * num_directions, batch_size, hidden_size): tensor containing the initial hidden state for each element in the batch. Defaults to zero if not provided. If the RNN is bidirectional, num_directions should be 2, else it should be 1.
forward函数的返回值是: -
output of shape (num_steps, batch_size, num_directions * hidden_size): tensor containing the output features (h_t) from the last layer of the RNN, for each t.
-
h_n of shape (num_layers * num_directions, batch_size, hidden_size): tensor containing the hidden state for t = num_steps.
过拟合、欠拟合及其解决方案
训练误差和泛化误差
训练误差:模型在训练数据集上表现出的误差
泛化误差:模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似
模型选择
验证数据集: 给定的训练集中随机选取一小部分作为验证集,根据验证集得到的泛化误差来评估模型好坏,从而使得最终用于测试数据集的模型具有较好的泛化性能。
K折交叉验证:由于验证数据集不参与模型训练,当训练数据不够用时,预留大量的验证数据显得太奢侈。一种改善的方法是K折交叉验证(K-fold cross-validation)。在K折交叉验证中,我们把原始训练数据集分割成K个不重合的子数据集,然后我们做K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
过拟合和欠拟合
过拟合:模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting);
欠拟合:模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)
解决要点在于型复杂度和训练数据集大小
1,

2,一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
解决方案
权重衰减:权重衰减等价于 [Math Processing Error] 范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段
1,L2 范数正则化(regularization):l2范数正则化在模型原损失函数基础上添加l2范数惩罚项,从而得到训练所需要最小化的函数。l2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积
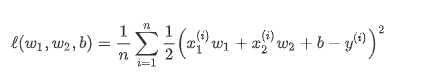
引入后的损失函数为:
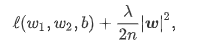

2,丢弃法:训练是随机失活隐藏层某些单元
梯度消失、梯度爆炸
假设一个层数为 L 的多层感知机的第 l 层 H(l) 的权重参数为 W(l) ,输出层 H(L) 的权重参数为 W(L) 。为了便于讨论,不考虑偏差参数,且设所有隐藏层的激活函数为恒等映射(identity mapping) ϕ(x)=x 。给定输入 X ,多层感知机的第 l 层的输出 H(l)=XW(1)W(2)…W(l) 。此时,如果层数 l 较大, H(l) 的计算可能会出现衰减或爆炸。举个例子,假设输入和所有层的权重参数都是标量,如权重参数为0.2和5,多层感知机的第30层输出为输入 X 分别与 0.230≈1×10−21 (消失)和 530≈9×1020 (爆炸)的乘积。当层数较多时,梯度的计算也容易出现消失或爆炸。
解决方案
1, 随机初始化模型参数:

方法:
Xavier随机初始化
假设某全连接层的输入个数为 a ,输出个数为 b ,Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布,它的设计主要考虑到,模型参数初始化后,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响
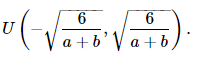
考虑环境因素
1,协变量偏移
2,标签偏移
3,概念偏移
循环神经网络进阶





注意力机制与Seq2seq模型
1,注意力机制框架


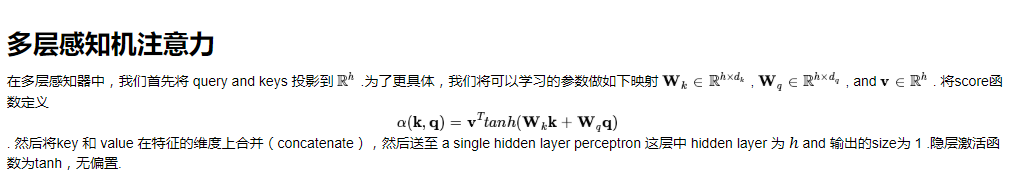

Transformer
由于
CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。
RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。
为了整合CNN和RNN的优势,[Vaswani et al., 2017] 创新性地使用注意力机制设计了Transformer模型。该模型利用attention机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的tokens,上述优势使得Transformer模型在性能优异的同时大大减少了训练时间。
Transformer 架构:

多头注意力层

解码器

卷积神经网络基础
二维卷积层

(注意)互相关运算与卷积运算
卷积层得名于卷积运算,但卷积层中用到的并非卷积运算而是互相关运算。我们将核数组上下翻转、左右翻转,再与输入数组做互相关运算,这一过程就是卷积运算。由于卷积层的核数组是可学习的,所以使用互相关运算与使用卷积运算并无本质区别。
感受野:影响元素 x 的前向计算的所有可能输入区域(可能大于输入的实际尺寸)叫做 x 的感受野(receptive field)。我们可以通过更深的卷积神经网络使特征图中单个元素的感受野变得更加广阔,从而捕捉输入上更大尺寸的特征。
填充:指在输入高和宽的两侧填充元素(通常是0元素),图2里我们在原输入高和宽的两侧分别添加了值为0的元素。
步幅:卷积核在输入数组上滑动,每次滑动的行数与列数即是步幅(stride)
输出形状计算:

多输入通道和多输出通道相关计算:


1x1卷积层:

对比

池化:

leNet
使用全连接层的局限性:
- 图像在同一列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。
- 对于大尺寸的输入图像,使用全连接层容易导致模型过大。
使用卷积层的优势: - 卷积层保留输入形状。
- 卷积层通过滑动窗口将同一卷积核与不同位置的输入重复计算,从而避免参数尺寸过大
letnet 模型: LeNet交替使用卷积层和最大池化层后接全连接层来进行图像分类

LeNet缺点
1.神经网络计算复杂。
2.还没有⼤量深⼊研究参数初始化和⾮凸优化算法等诸多领域
卷积神经网络进阶
AlexNet



NiN重复使⽤由卷积层和代替全连接层的1×1卷积层构成的NiN块来构建深层⽹络。
NiN去除了容易造成过拟合的全连接输出层,而是将其替换成输出通道数等于标签类别数 的NiN块和全局平均池化层。
NiN的以上设计思想影响了后⾯⼀系列卷积神经⽹络的设计。
















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









